I previously discussed training the prompt for a language model to tune it for a specific task without altering the language model. This technique is precisely the subject of a paper (Lester, Al-Rfou, and Constant 2021) by google. They say it’s great. I wrote about it 5 days before this paper was published. I’m not bitter.
I’m really not - it’s great validation of my idea that Google was working on it. Let’s see if my next idea will be such a smash.
Anyway, lets have a look at this paper.
The paper outlines the current approaches to classification of text starting with a deep learning model. There is the approach of fine tuning the model to perform a specific task (something I recently read about in (Howard and Ruder 2018)). Then there is the approach of using a prompt to cause the language model to propose a solution.
Prompting in this way really arose after GPT-3, and the idea was to provide a few examples of the task as well as a description of the task and then let the model predict the language following the text (Brown et al. 2020). The predicted text would then be the solution to the problem:
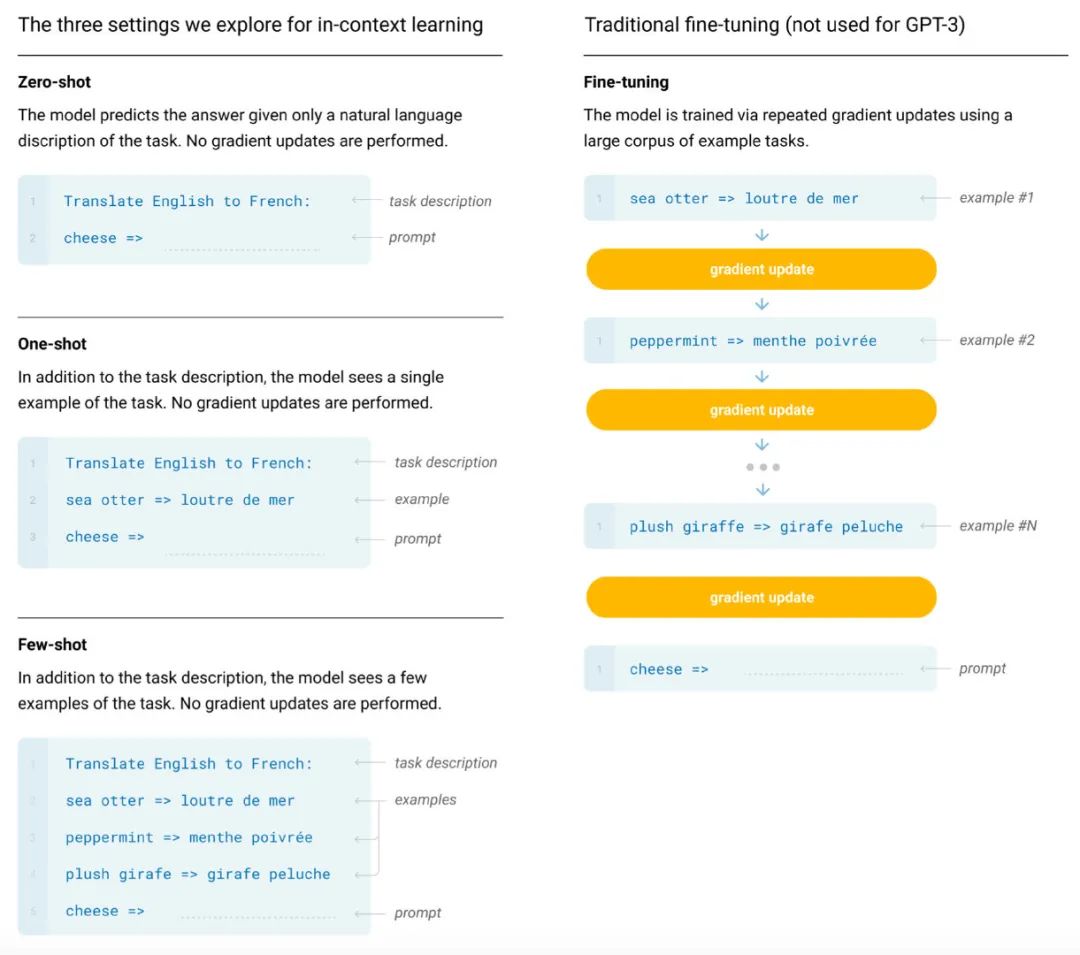
In these examples the prompt is Translate English to French:.
Coming up with a good prompt for a task is tricky. I’ve been trying to do this for a task at work (and that is what triggered my original investigation of prompt training). It seems that people at Google have had the same thought process, as they want to automate the generation of high quality prompts. Since they are basing this work on the original few shot paper they are investigating adding a prefix to the text.
Literature Review
In the paper they review the literature to find competing methods, which is quite interesting as it gives hints as to techniques that could be used for model tuning that I could apply to other problems. The different approaches that they discuss are qualified based on the number of parameters that need to change. That metric puts model fine tuning at the bottom as that involves updating the entire model (thus, 100% of the parameters change). This also has the downside that the model becomes task specific so it cannot be applied to other tasks - primarily a memory / hardware problem as you need to keep multiple different models loaded, one for each required task.
Then there is the approach of just changing the classification head, which I have previously read about in (Howard and Ruder 2018). This seems to be quite widely used as the different model types in the huggingface framework differ based on their classification head (something that became quite apparent when I actually performed the prompt training - the body of the model was clearly separated from the language model head).
There is also an approach of adding a prefix to every activation as it passes through the network (including the input layer) (Li and Liang 2021). I found this one quite intriguing as it would seem to replicate the prompt training with a greater expressive range. The trained activation prefixes represent 0.1% of the model parameters. The paper claims to get comparable results to model fine tuning, which seems to be the strongest available approach. I’m interested in reading this paper more thoroughly.
The other interesting technique mentioned was comparatively older - published in 2017 for computer vision. This approach involves adding bottleneck blocks inbetween pretrained layers (Rebuffi, Bilen, and Vedaldi 2017). I’m very interested in this as I have been investigating neural architecture growth and this might link into a body of existing work on this topic. This is not considered to be a competative approach compared to the others as now it adds 2-4% more parameters to the model.
For comparison tuning the prompt adds around 0.001% more parameters.
Prompt Tuning Approach
Given the prefix approach outlined in Langauge Models are Few Shot Learners (Brown et al. 2020), the authors have decided to put the prompt before the text. This is in contrast to the approach that I used where the prompt is added as a suffix, however it does make it marginally easier to implement. So if I work on this in future using a prefix prompt would be worth investigating.
Model Preparation
The model they use is the T5.1.1 model from Google. This was trained to fix corrupted text (much like the training of BART). Unfortunately this skews the language model in a way that makes it under perform for the task at hand, requiring some fine tuning to turn the model into a general purpose language model. I did not encounter this problem as I was using GPT-2, which was not trained in this way. It is interesting to know that corrupted language repair is considered to be the best way to train language models these days. I guess this relates to teacher forcing and the ability of the model to produce good text based only on it’s own output.
Prompt Initialization
The prompt length varied from 1 to 150 tokens and they outlined three approaches for choosing the starting parameters. The first was random initialization (normal distribution between -0.5 and 0.5). This is interesting as while the embedding weights that I inspected in the embedding layer vary from this range, the weights after training were in each run close to this (typically varying from -0.6 to 0.6). This was the worst performing technique.
The next approach was to randomly choose the starting weights by selecting from the embeddings that the model uses. This has the benefit of starting with values that are in the range the model expects, and is the technique that I used. They refined it by only choosing from the 5,000 most common embeddings. Selecting a starting point from the embedding outperforms random initialization.
The final approach was for classification tasks. There the starting state was created by taking the embeddings of the target words of the classification (so in my test that would be “good” and “bad”). If a target word tokenizes to multiple tokens then the embeddings of those tokens are averaged together. If there are fewer target tokens than positions in the prompt then the remaining positions are populated from the top 5,000 embeddings (as above). This is a novel approach as it is intended to tell the model what words it is expected to produce.
Optimization
I also found it interesting that they did not use Adam as the optimizer, instead choosing adafactor (Shazeer and Stern 2018). When originally trying to use AdamW for the optimizer I hit a problem regarding an uninitialized beta value, I wonder if the effectiveness of plain Adam is in some way compromised by the restricted training approach. After briefly reviewing the paper I see that adafactor is an improved Adam which improves the memory usage. Neat.
The learning rate was also reported as 0.3, and was held constant, which seems extremely high. It’s unusual not to use some kind of schedule to allow better fine tuning. This setting is intimately tied to the optimizer choice so it may well be that adafactor allows for high learning rates. (the full description of the parameters is on page 4 of the paper).
Results
For a large model prompt tuning was indistinguishable from fine tuning the whole model. Prior to that point it consistently beats hand made prompts but underperforms against fine tuned models. The T5.1.1 XXL is presumably the 11 billion parameter model, which would line up with the graphs (the largest model just tops \(10^{10}\) parameters).
They also investigated ensembling the results of several separately trained prompts, which had encouraging results. It would be easy to ensemble this approach as you can just run all of the different prompts over the text in a single batch. With past calculations of GPT-2 this could be made quite efficient.
Quite frankly these results are astonishing. That such a large model can be tuned to a specific task by altering such a small number of parameters is incredible. For my purposes such a model is wildly impractical as there is no way I could feasibly run it. It’s good to know the upper limit on the technique though.
Benefits of Prompt Tuning
Having a single base model which is then turned to different tasks based on the prompt is extremely attractive from a practical perspective. This means that you only need a single model on the GPU which can service many different tasks. Being able to combine things like sentiment or emotion into a single pass of a single model would reduce complexity a lot.
For uni-directional models like GPT-2 with prompt suffixes (what I investigated) this is even more attractive. This is because the text can be turned into the past first and then expanded to provide the prefix for the different prompt tasks. As I consider GPT-2 I think that this uni-directional approach is what caused the investigation into activation prefixing (Li and Liang 2021). It’s fun to think this stuff through and come to realizations about how it fits together.