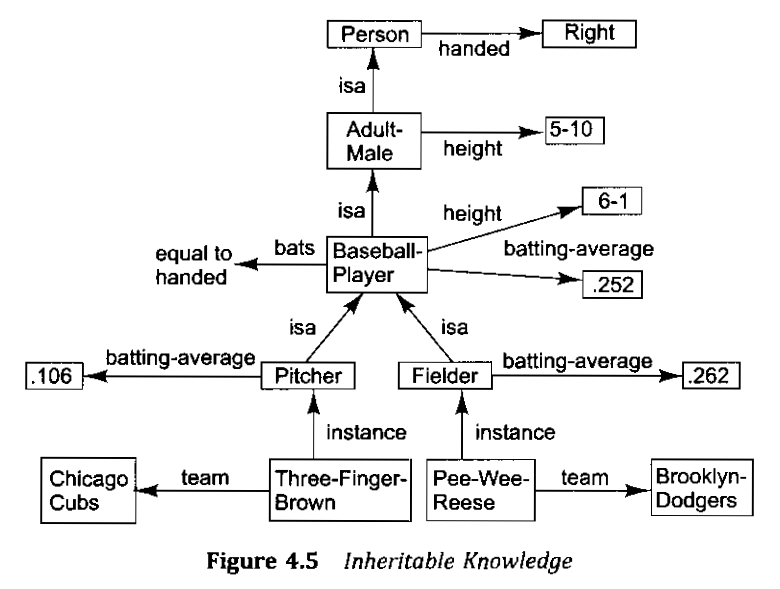
Optimizing training hyperparameters with various libraries
Trying out the smolagents framework for this course
Creating a Q&A bot for this blog
Breaking text down to atomic facts with FactScore
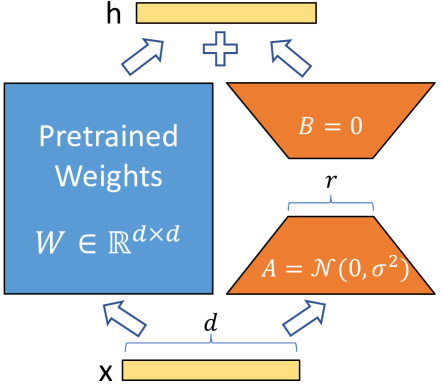
Customizing a pretrained model while keeping the handy utility methods
How to perform Retrieval Augmented Generation over graph datastructures?
What’s the worst way I can generate art with deep learning models?
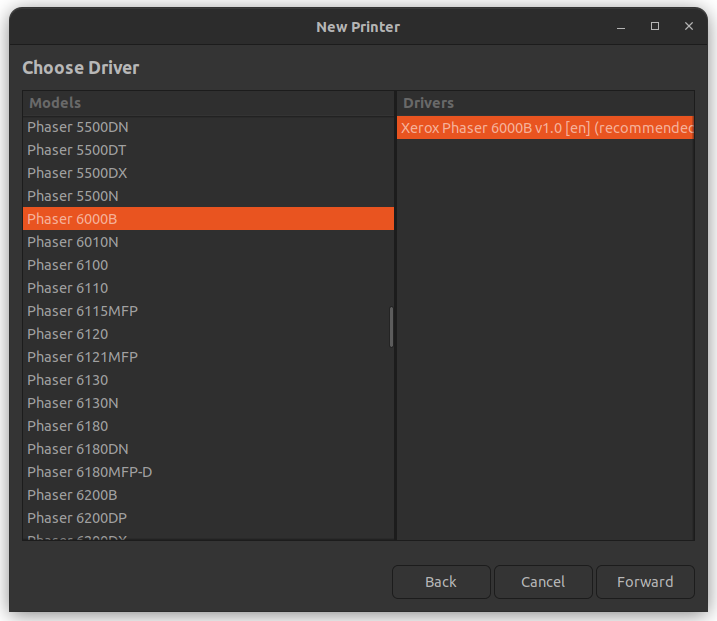
What I had to do to set up my printer
Changing ssh configuration based on laptop location
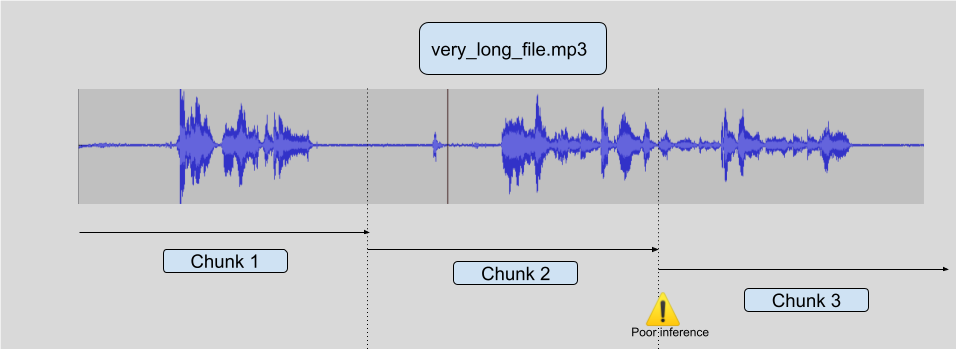
How fast is Whisper v3? How fast can I make it?
Measuring the difference between floating point embeddings and the binarized form
Can I use a LLM to discuss a paper?
Part 2
Creating a conversational interface to an API
How Multilingual is Multi-Genre Natural Language Inference
Generating text based on a skill list to match an advert
Using the latest whisper model to transcribe speech
Can the effect of an intervention be measured when the intervention is dependent on the measured value?
Uploading some Aspect Sentiment datasets to the Huggingface hub
What I did to clear up my install
Is a Cosine Similarity of 0.5 discriminative for high dimensional vectors?
Is KL Divergence better than Cross Entropy?
What is a scoring rule and how does it work?
How does CTranslate2 compare to Transformers for speed?
Changing GPT2 model to use ALiBi positional embeddings
Are large language models unidirectional? Can they benefit from saving intermediate state of previous runs?
A comparison of two 7B language models
Ways to restrict the output of Large Language Models
A reminder for me about how I configure my keyboard
Investigation of the technique for training large models
Checking out the new composition of deep learning models by Huggingface
Can I recommend perfumes based on comments?
Can I find relationships between scents in perfumes using Bayesian Networks?
First run at using LLaMA-7B
Working through the basics before getting onto networks
Evaluating different visualization techniques for this blog
Can we show what matters by calculating over missing values?
How can we show the influence of the input to the output?
Looking at a transformer model for tabular data
Reviewing a paper on Blocking Adverts based on image content
Is ONNX really a reliable way to translate code from Python to Java?
What parts of an image contribute to the CLIP classification?
How good is the OpenAI Whisper speech to text model? How easy is it to quantize?
Sentence Transformer models create embeddings out of text, can they be trained with the Huggingface Trainer?
Using the Intel Neural Compressor to perform Quantization Aware Training
Using the built in benchmarking code to measure quantized model performance
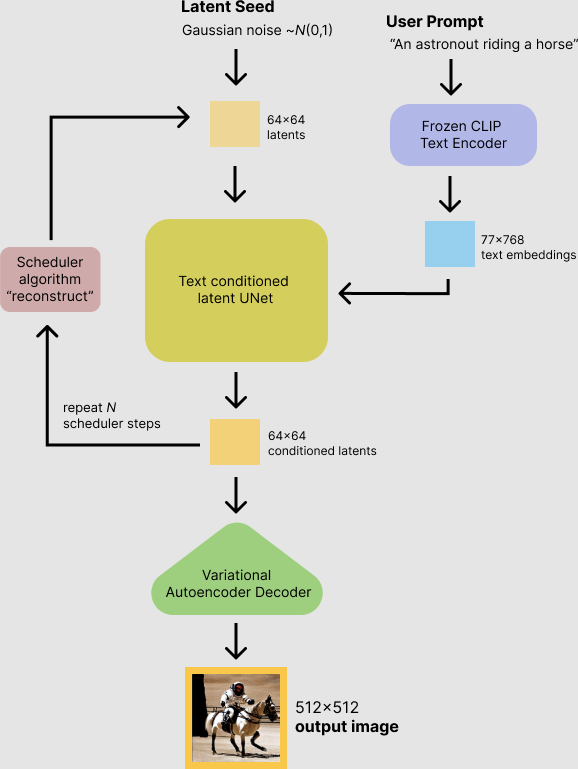
This model can generate images from a prompt, like DALL-E
Different ways to Optimize a model with performance
Training a model with the Wikipedia Dataset
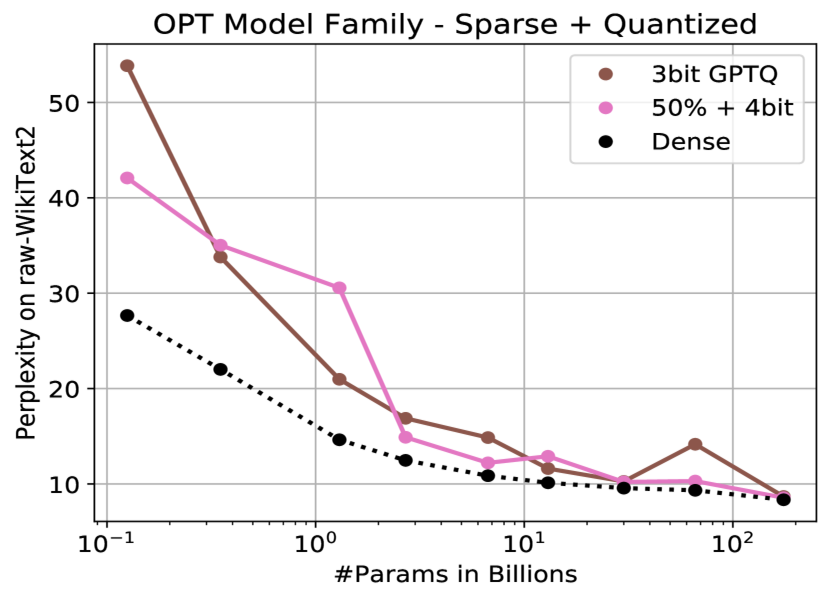
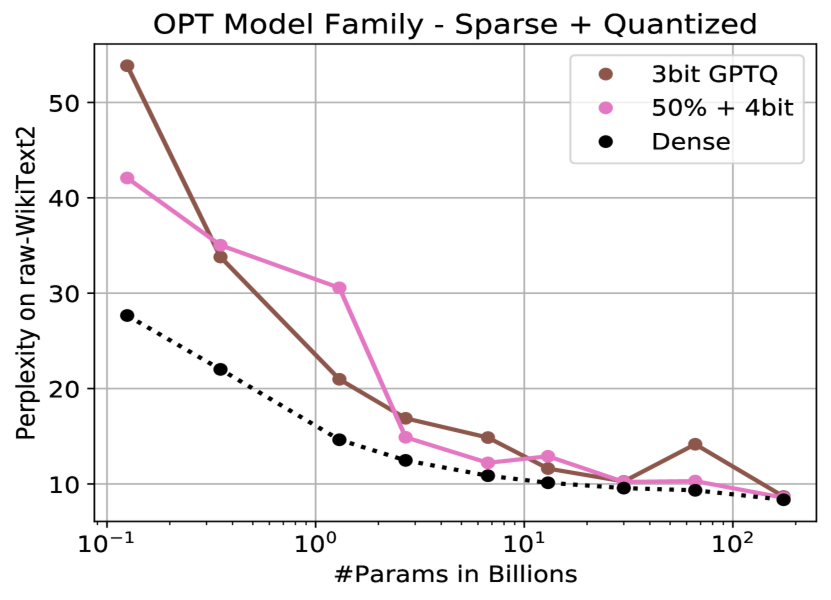
Different ways to Quantize a model with performance
Using Wikipedia and Wikidata to link other languages to English articles
Creating an evaluation framework for Word Sense Induction
Changing the blog framework
A bit of fun
Visualizing the different clustering metrics
Resolving words based on model features and Wikipedia Synonyms
Clustering the Wikipedia linked article features for Word Sense Induction
Can use Wikipedia articles as targets for word sense induction
Trying to reduce model collapse by simultaneous language modelling
Does XLM-RoBERTa collapse into a fixed set of outputs if it is trained for a long time
I’ve been using the wrong model all this time!
Excluding or punishing the most common tokens for XLM-RoBERTa
Calculating the frequency statistics for token predictions
Using the large Spacy models to preprocess the Tatoeba dataset
Using CLIP to VQGAN to turn text into an image
Another reminder for myself about getting CUDA working on Ubuntu
Using the recent kuprel rewrite to understand and implement DALL-E
Trying different models for the multilingual prediction
Trying another way to calculate the multi-token prediction
Turn off Fn key behaviour on Ubuntu
Getting the DALL-E Mini model from huggingface running
Using the Tatoeba cross language dataset to internalize a multi lingual prompt in a single space
How well do image captioning models work?
Can I update the model used for persona based conversations?
Can I use prompt internalization to perform Word Sense Induction?
Can I use KL Divergence to teach a model to match a prompted model?
Create a distilled model with a different adjustment to the teacher
Create a distilled model
Is it possible to make a better speech recognizer?
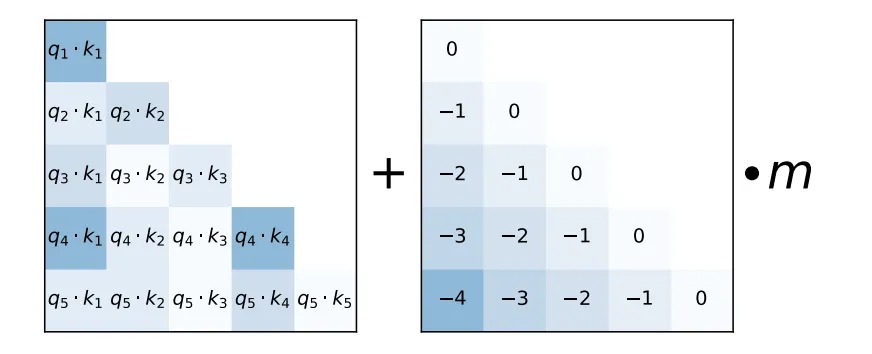
It’s about time that I thoroughly explored the Attention mechanism
Can I shift the domain of a sentiment model by changing embeddings only?
Can I do the homework that has been set by a cruel and unusual math tutor?
Can we unshuffle the shuffled words we made?
Can I implement a full shuffler of a number of arbitrary 8-bit values?
How do Quantum Circuits actually work?
How does QuTiP compare to Qiskit for Quantum Computing?
Can I perform the simplest operation using a simulated Quantum Computer?
I’ve been using graphviz to create the flow charts for these posts. Can I use LaTeX instead?
GPT-2 can take previous activations to process the following tokens in the sentence. How does this work with a bi-directional model like RoBERTa?
How can we know what we talk about?
JINA is a content insensitive document index. Can I use it to index images with CLIP and then search for them?
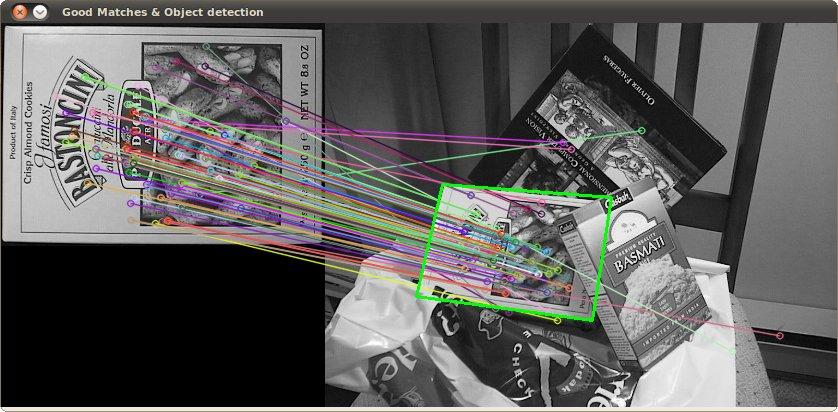
YOLO detects bounding boxes, CLIP can classify images using natural language promopts. Can they be combined?
See how easy it is to get some images from this zoo of different datasets
I want to see how easy simple transformers is to use for context sensitive text generation
Train the wikipedia link recognition model using mean squared error and reduce the number of tokens considered
Train the wikipedia link recognition model using mean squared error
Someone linked me a 2015 paper on using pigeons to classify mammograms. I want to reproduce this using a neural network
How to prepare data, customize a model, and train it
Arranging the recent work on Wikipedia Link recognition into a paper
Can try training the model using the class based approach hinted at with the perplexity metric
Training is slow and performance varies wildly. A way to track the quality of the model early could make progress more systematic
Link spotting seems weak, using inside - outside - beginning as the classifier could help?
Try to improve the preprocessing performance
First go at training a Wikipedia Link recognizer
Trying to extract meaningful tokens from a page using mutual information
This seems to be bigger than I anticipated - let’s further investigate and prepare the data
I can use the aspect sentiment technique to recognize and cluster wikipedia linked text
Using a different system for entity extraction allows for a more focused model
Predicting the presence of hashtags on tweets
How to evaluate the performance?
How well does the token classification approach work?
Can I find a dataset that can work with my approach?
Can the prophet predict the most erratic of all timeseries?
Marking up entities in a single pass
Can Sequence to Sequence models be trained to extract entities and mark up sentiment?
A review of a comprehensive blog post on prompt training
Prompt Training GPT2 works well until GPT2-large
Handling pipe/spread/collect patterns across process boundaries in pytorch
Using Huggingface Trainer and Dataset to do Prompt Training
I’ve done enough research on Prompt Training to try to write a paper about it
The solution to a recent problem I had with NVidia and CUDA
Is dagster a good fit for a data science pipeline?
Using the techniques from ULMFit to do image classification
Train a linear classifier per prompt
Try to calculate the moving centroid for each class
Clustering the trained prompts to try to extract the different classes
Classification with trained prompts by clustering the token confidence
Classification with trained prompts by clustering the raw transformer output instead
Evaluating prompt training on a more popular dataset
Google published a paper on training a prompt for a language model
Another Calculus lesson for Neural Networks
Using DeepDream techniques to generate a language model prompt
Actually training GPT-2 for another language properly
Making a chatbot listen to you
A chatbot that thinks it is a house
A primer in Calculus as it relates to Neural Networks
Train GPT-2 with some Spanish data
Prepare some Spanish data using Wikipedia dumps
Some difficult questions I found
How to update Kaggle Kernels with make commands
How to use Kaggle Kernels with your regular development setup
How to explain the output a Deep Learning model
See if I can report training progress to Weights and Biases
Convert GPT-2 to int8 and check performance
Another questionnaire on deep learning
A model to classify pictures of people
Evaluation of error visualizer for tensor operations
Quick evaluation of different models introduced in first lesson
Convert floating point models into int8 models
Visualize differences between two dataframes
CMU lecture on fundamentals of Macchine Translation - part 2
Questionnaire on Deep Learning
CMU lecture on fundamentals of Macchine Translation
What is worth investigating in Data Science and Deep Learning?
Data investigation for Kidney Image Segmentation challenge
Checking out a network visualizer
Checking out spaCy part of speech tagging
How I originally set this blog up
Checking out a new model from OpenAI