Classification with trained prompts by clustering the token confidence
Published
May 6, 2021
In the previous post I investigated moving away from picking the tokens to target. I used that as an opportunity to skip the language model token confidence as well. The results were not great.
Since the prompt training is viable I think that stripping the language model head was a mistake. I’m now going to investigate clustering the outputs once again, but this time after the conversion to token confidences.
Mandatory Block of Code
Here is the dataloader
Code
#collapsefrom typing import Dict, Iterator, Optional, Tuple, Unionimport pandas as pdimport torchfrom transformers import AutoModelForCausalLM, AutoTokenizerPast = Tuple[Tuple[torch.Tensor, ...], ...]TextBatch = Dict[str, torch.Tensor]PastBatch = Dict[str, Union[torch.Tensor, Past]]class TextDataloader:"""Provides a dataloader over a text dataframe"""def__init__(self, df: pd.DataFrame,*, tokenizer: AutoTokenizer, batch_size: int, max_length: int, device: torch.device = torch.device("cuda"), shuffle: bool=True, ) ->None:self.tokenizer = tokenizerself.df = dfself.batch_size = batch_sizeself.max_length = max_lengthself.device = deviceself.shuffle = shuffledef__iter__(self) -> Iterator[TextBatch]:"""Returns an iterator that returns batches. The final batch can be a partial batch."""ifself.shuffle: df =self.df.sample(frac=1).reset_index(drop=True)else: df =self.df batch_size =self.batch_sizefor i inrange(len(self)): start = i * batch_size end = start + batch_sizeyieldself.to_batch(df[start:end])def__len__(self) ->int:"""Returns the total number of batches that can be returned.""" full_batches =len(self.df) //self.batch_sizeiflen(self.df) %self.batch_size:return full_batches +1return full_batchesdef to_batch(self, rows: pd.DataFrame) -> TextBatch:"""Converts the rows into a batch""" tokens =self.tokenizer( rows.text.tolist(), return_tensors="pt", padding=True, truncation=True, max_length=self.max_length, ).to(self.device) labels = torch.tensor(rows.label.tolist(), dtype=torch.long, device=self.device)return {"input_ids": tokens["input_ids"],"attention_mask": tokens["attention_mask"],"labels": labels, }class PastDataloader(TextDataloader): # pylint: disable=too-few-public-methods"""Provides a dataloader which converts the text into past tensors"""def__init__(self, df: pd.DataFrame,*, model: AutoModelForCausalLM, tokenizer: AutoTokenizer, batch_size: int, max_length: int, label_map: Optional[Dict[str, int]] =None, device: torch.device = torch.device("cuda"), shuffle: bool=True, ) ->None:if label_map: df = df.copy() df["label"] = df.label.map(label_map)super().__init__( df=df, tokenizer=tokenizer, batch_size=batch_size, max_length=max_length, device=device, shuffle=shuffle, ) model.to(device)self.model = model@torch.no_grad()def to_batch(self, rows: pd.DataFrame) -> PastBatch: batch =super().to_batch(rows) past_key_values =self.model( input_ids=batch["input_ids"], attention_mask=batch.get("attention_mask", None), ).past_key_valuesreturn {"past_key_values": past_key_values,"attention_mask": batch["attention_mask"],"labels": batch["labels"], }
Here is the training loop
Code
#collapsefrom typing import Callable, Dict, Tuple, Unionimport torchfrom tqdm.auto import tqdmfrom transformers import AutoModelForCausalLM, AutoTokenizerLossFunction = Callable[[torch.Tensor, torch.Tensor], torch.Tensor]def train(*, dl: PastDataloader, model: AutoModelForCausalLM, tokenizer: AutoTokenizer, prompt_tokens: int, epochs: int, loss_fn: LossFunction,) -> torch.Tensor:"""Train the prompt""" prompt, prompt_attention = _make_prompt( model=model, tokenizer=tokenizer, prompt_tokens=prompt_tokens, device=dl.device, )# optimize just the prompt optimizer = torch.optim.Adam([prompt], lr=1e-3) total_loss =0.0with tqdm(range(epochs), leave=False, bar_format="loss: {postfix[0]:>8.4f}", postfix=[0.0] ) as bar:for _epoch in bar:for batch in tqdm(dl, leave=False): total_loss += _process( batch=batch, model=model, optimizer=optimizer, prompt=prompt, prompt_attention=prompt_attention, loss_fn=loss_fn, ) average_loss = total_loss /len(dl) bar.postfix[0] = average_lossprint(f"Average loss: {average_loss:0.4f}") total_loss =0.0return prompt.datadef _make_prompt(*, model: AutoModelForCausalLM, tokenizer: AutoTokenizer, prompt_tokens: int, device: torch.device,) -> Tuple[torch.nn.Parameter, torch.Tensor]:"""Generate the prompt by randomly choosing tokens and then converting to embeddings""" prompt_indexes = torch.randint( size=(prompt_tokens,), low=0, high=tokenizer.vocab_size, device=device ) prompt_attention = torch.ones( size=(1, prompt_tokens), dtype=torch.long, device=device ) prompt = torch.nn.Parameter( model.transformer.wte(prompt_indexes).clone()[None, :, :] )return prompt, prompt_attentiondef _process(*, batch: Dict[str, Union[torch.Tensor, Past]], model: AutoModelForCausalLM, optimizer: torch.optim.Optimizer, prompt: torch.nn.Parameter, prompt_attention: torch.Tensor, loss_fn: Callable[[torch.Tensor, torch.Tensor], torch.Tensor],) ->float: optimizer.zero_grad() logits = _get_output_with_past( model=model, prompt=prompt, attention_mask=prompt_attention, past=batch["past_key_values"], past_attention_mask=batch["attention_mask"], ) loss = loss_fn(logits, batch["labels"]) loss.backward() optimizer.step()return loss.item()def _get_output_with_past(*, model: AutoModelForCausalLM, prompt: torch.nn.Parameter, attention_mask: torch.Tensor, past: Past, past_attention_mask: torch.Tensor,) -> torch.Tensor:"""Get the predictions for the next token after the prompt"""# concatenate the past attention with the prompt attention batch_size = past_attention_mask.shape[0] attention_mask = attention_mask.repeat_interleave(batch_size, dim=0) attention_mask = torch.cat([past_attention_mask, attention_mask], dim=-1)# expand the prompt to match the batch size input_ids = prompt.repeat_interleave(batch_size, dim=0) state = model.transformer( inputs_embeds=input_ids, attention_mask=attention_mask, past_key_values=past, ).last_hidden_state logits = model.lm_head(state)return logits[:, -1]
Here is a method to get the token confidence for a piece of text
Code
#collapse@torch.no_grad()def get_output( text: str, prompt: torch.Tensor, model: AutoModelForCausalLM, tokenizer: AutoTokenizer) -> torch.Tensor: tokens = ( tokenizer(text, return_tensors="pt")["input_ids"] .to("cuda") ) token_embedding = model.transformer.wte(tokens)# join the tensors - dim 0 is the batch, 1 is the tokens, 2 is the specific embedding value full_embedding = torch.cat([token_embedding, prompt], dim=1) state = model.transformer(inputs_embeds=full_embedding).last_hidden_state logits = model.lm_head(state)return logits[0, -1]
Now that we have the code and dataloaders, we can use the different training approaches.
Cosine Similarity Loss Training
So now we have to consider the loss function. Ideally it would be fast to compute, as I will need to run it against every pair of rows in the batch. For now let’s just take the cosine similarity and then see if the labels match.
Code
def cosine_loss_fn(output: torch.Tensor, labels: torch.Tensor) -> torch.Tensor: batch_size = output.shape[0] cycled_output = output.repeat((batch_size, 1))# This repeats the tensor as if using cycle()# [1, 2, 3] -> [1, 2, 3, 1, 2, 3...] interleaved_output = output.repeat_interleave(batch_size, dim=0)# This repeats each element of the tensor# [1, 2, 3] -> [1, 1.., 2, 2.., 3, 3..] cycled_labels = labels.repeat(batch_size) interleaved_labels = labels.repeat_interleave(batch_size, dim=0) repeated_labels = (cycled_labels == interleaved_labels).long() repeated_labels = (repeated_labels *2) -1# label needs to be -1 for different or 1 for same# true -> 1 -> 1*2-1 -> 1# false -> 0 -> 0*2-1 -> -1return torch.nn.functional.cosine_embedding_loss( cycled_output, interleaved_output, repeated_labels )
I’m not 100% sure this is correct but I’m going to give it a go anyway.
bad_output = get_output("What a script, what a story, what a mess!", prompt=cosine_trained_prompt, model=model, tokenizer=tokenizer)good_output = get_output("Brilliant and moving performances by Tom Courtenay and Peter Finch.", prompt=cosine_trained_prompt, model=model, tokenizer=tokenizer)
Instead of cosine, which is based on the direction of the vector, I am going to try the absolute distance between the points that each vector represents. If the points are for the same class then the distance should be minimized, and if they are for different classes then it should be maximized.
Because for the same class as the distance tends to zero, the loss will too. Equally for different classes as the distance tends to infinity, the loss will tend to zero. These may need balancing in some way.
Code
def distance_loss_fn( output: torch.Tensor, labels: torch.Tensor) -> torch.Tensor: batch_size = output.shape[0] cycled_output = output.repeat((batch_size, 1))# This repeats the tensor as if using cycle()# [1, 2, 3] -> [1, 2, 3, 1, 2, 3...] interleaved_output = output.repeat_interleave(batch_size, dim=0)# This repeats each element of the tensor# [1, 2, 3] -> [1, 1.., 2, 2.., 3, 3..] cycled_labels = labels.repeat(batch_size) interleaved_labels = labels.repeat_interleave(batch_size, dim=0) different_labels_mask = cycled_labels != interleaved_labels distance = torch.pairwise_distance( cycled_output, interleaved_output )# there is a problem with this,# it is considered an in-place operation which causes gradient calculations to fail# distance[different_labels_mask] = 1 / distance[different_labels_mask]return ( distance[~different_labels_mask].sum()+ (1/ distance[different_labels_mask]).sum() )
bad_output = get_output("What a script, what a story, what a mess!", prompt=distance_trained_prompt, model=model, tokenizer=tokenizer)good_output = get_output("Brilliant and moving performances by Tom Courtenay and Peter Finch.", prompt=distance_trained_prompt, model=model, tokenizer=tokenizer)
Now that we have a trained prompt we can try evaluating it. Evaluating the prompt is hard because we don’t know what output corresponds to a given class. The training just aims to separate the outputs for the two classes.
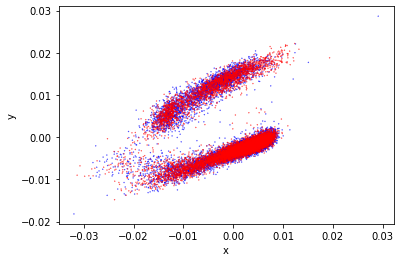
So I think the evaluation should try to visualize the outputs for the different classes and then we can see if they are separate. The code in this section will collect the outputs for the validation set and then use PCA to reduce them to two dimensions. At that point they can be visualized.
So it’s still having a rough time with a problem that this technique dealt with extremely well before.
Label Clustering
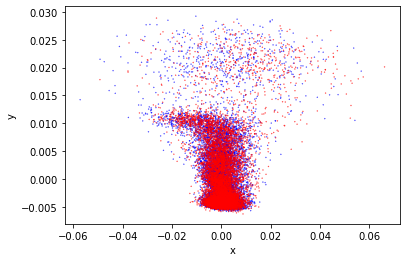
I suspect that PCA is not separating the clusters because the dominant dimensions that the points differ on are not the same dimensions that all of the points primarily vary on. Since the original prompts worked quite well for this task if I use this same visualization on them then it should be possible to see if PCA is actually helping. If it isn’t then I’ll have to come up with another assessment method.
So this isn’t separated either. I need to review how to evaluate this training approach.
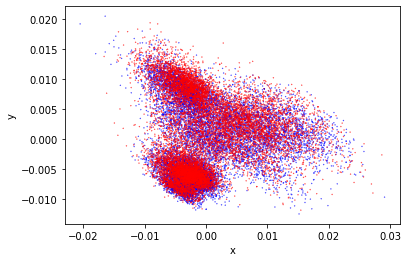
As a last spot check I can review the two reviews I have been using for the manual evaluation. This is more of a sanity check to confirm that I am loading and using this prompt correctly.
Code
bad_output = get_output("What a script, what a story, what a mess!", prompt=original_prompt, model=model, tokenizer=tokenizer)good_output = get_output("Brilliant and moving performances by Tom Courtenay and Peter Finch.", prompt=original_prompt, model=model, tokenizer=tokenizer)
So the reviews are correctly classified. It’s interesting that the cosine similarity is so high and that the distance between the tokens is so low. This does suggest that the training is doing something. I need to determine more systematically if these clusters are separable.