Try to calculate the moving centroid for each class
Published
May 10, 2021
I’ve been trying to train prompts to make classifers (see here and here). The general principle is that a language model can take some input and a trained prompt to become a task specific classifier. For example the prompt “This person feels” might get a language model to act as an emotion classifier (as it might say good or bad or happy or sad).
Coming up with a suitable prompt is hard so I want to use classical training techniques to produce one. I’ve managed to train a prompt like this.
The next problem is the appropriate selection of words to look for in the output. If I choose a token then I might choose poorly. There could be a better token to choose for a given category. Once again I want to be able to choose a token automatically.
I’m now reasonably confident that the visualization techniques that I have used are working correctly. So I can use these to determine if the method of training is working.
Problem Statement
The principle problem that I have had is that I want the outputs for different classes to be distinguishable without choosing them in advance. When I select two tokens to compare (like good and bad) they are distinguishable but I have chosen them. Instead the output of the model should vary by class and this variation should be consistent.
I first tried to train the prompt by measuring the difference between two inputs. If the inputs have the same label then the distance between them should be small. For inputs with different labels the distance should be large. Doing this let me train the model but when I visualized the results the model was not clearly distinguishing between the input labels.
The problem with the distance measurement is that the points start out randomly distributed. This means that the prompt is guided in arbitrary directions rather than a consistent direction.
The second problem is that the pure distance measurement has two loss functions - one for two inputs with the same class, and one for two inputs with different classes - and the curve of these loss functions is not the same. The loss for the same class is the distance between the points - so it grows linearly. The loss for different classes is the reciprocal of the distance - so it shrinks exponentially. It is very unlikely that these two loss factors are in balance and so one relationship will tend to dominate the learning.
Proposed Solution
To solve these problems I am going to move to modelling each class as a centroid. This means that there is one ideal point for each class in the output space. The loss for a given output is thus the distance from that output to the centroid. This makes the loss function consistent across classes.
The next part is that the centroid should be discovered. To do this I will be adjusting the centroid based on the observed outputs from the model. So while the current centroid alters the prompt, the current outputs then adjust the centroid. In this way the centroid is being trained parallel to the prompt.
Finally the centroids must be different. After all, the model prompt could tell the model to ignore the input. That would mean that the output of the model becomes extremely consistent. So when updating the centroids a small impulse must be provided to move the updated centroids away from other centroids.
Centroid Movement as an Analogy of Optimizers
Optimizers move the weights of the model. Moving the centroid is like this.
A pure movement of the centroid based on the current outputs would be equivalent to SGD. So perhaps we can incorporate some of the advances that have been made in optimizer design? Momentum, dampening, etc.
The next thing is that the movement of the centroids apart is like regularization.
Can the centroids be treated as parameters of the model and trained with the same optimizer? I believe so. The loss could incorporate the distance between the centroids as a factor as well and that could use the optimizer for regularization.
Loss Function
This all means that the core problem is the definition of the loss function. We have already defined the loss for a given point as:
\[loss = \sum_{n \in batch} distance(point_n, centroid_{C_n})\] Where \(C_n\) is the classification class for point n.
If given the opportunity to optimize both \(point_n\) and \(centroid_{C_n}\) then the optimizer will act to bring them together. The rate at which it moves the centroid relative to the points can be adjusted by placing them in separate groups and having different learning rates for each group.
Then this just needs a factor related to the distance between each centroid.
Code
import torchdef centroid_loss_fn( output: torch.Tensor, labels: torch.Tensor, centroids: torch.nn.Parameter, distance_factor: float=1, repulsion_factor: float=1,) -> torch.Tensor:# only supports two classes for the moment targets = centroids[labels] distance = torch.pairwise_distance(output, targets).mean() repulsion =1/ torch.pairwise_distance(centroids[0][None, :], centroids[1][None, :]).sum()return (distance_factor * distance) + (repulsion_factor * repulsion)
Data Loader, Training Loop et al
Now we need a chunk of code to load the data appropriately. I’ve taken to collapsing this as these are quite extensive.
Code
#collapsefrom typing import Dict, Iterator, Optional, Tuple, Unionimport pandas as pdimport torchfrom transformers import AutoModelForCausalLM, AutoTokenizerPast = Tuple[Tuple[torch.Tensor, ...], ...]TextBatch = Dict[str, torch.Tensor]PastBatch = Dict[str, Union[torch.Tensor, Past]]class TextDataloader:"""Provides a dataloader over a text dataframe"""def__init__(self, df: pd.DataFrame,*, tokenizer: AutoTokenizer, batch_size: int, max_length: int, device: torch.device = torch.device("cuda"), shuffle: bool=True, ) ->None:self.tokenizer = tokenizerself.df = dfself.batch_size = batch_sizeself.max_length = max_lengthself.device = deviceself.shuffle = shuffledef__iter__(self) -> Iterator[TextBatch]:"""Returns an iterator that returns batches. The final batch can be a partial batch."""ifself.shuffle: df =self.df.sample(frac=1).reset_index(drop=True)else: df =self.df batch_size =self.batch_sizefor i inrange(len(self)): start = i * batch_size end = start + batch_sizeyieldself.to_batch(df[start:end])def__len__(self) ->int:"""Returns the total number of batches that can be returned.""" full_batches =len(self.df) //self.batch_sizeiflen(self.df) %self.batch_size:return full_batches +1return full_batchesdef to_batch(self, rows: pd.DataFrame) -> TextBatch:"""Converts the rows into a batch""" tokens =self.tokenizer( rows.text.tolist(), return_tensors="pt", padding=True, truncation=True, max_length=self.max_length, ).to(self.device) labels = torch.tensor(rows.label.tolist(), dtype=torch.long, device=self.device)return {"input_ids": tokens["input_ids"],"attention_mask": tokens["attention_mask"],"labels": labels, }class PastDataloader(TextDataloader): # pylint: disable=too-few-public-methods"""Provides a dataloader which converts the text into past tensors"""def__init__(self, df: pd.DataFrame,*, model: AutoModelForCausalLM, tokenizer: AutoTokenizer, batch_size: int, max_length: int, label_map: Optional[Dict[str, int]] =None, device: torch.device = torch.device("cuda"), shuffle: bool=True, ) ->None:if label_map: df = df.copy() df["label"] = df.label.map(label_map)super().__init__( df=df, tokenizer=tokenizer, batch_size=batch_size, max_length=max_length, device=device, shuffle=shuffle, ) model.to(device)self.model = model@torch.no_grad()def to_batch(self, rows: pd.DataFrame) -> PastBatch: batch =super().to_batch(rows) past_key_values =self.model( input_ids=batch["input_ids"], attention_mask=batch.get("attention_mask", None), ).past_key_valuesreturn {"past_key_values": past_key_values,"attention_mask": batch["attention_mask"],"labels": batch["labels"], }
Then the training loop. We are operating over the raw model output instead of the tokenized version.
This has some subtlety as it creates the centroids and returns them after training. I’m also making quite a few adjustments to this during this post so I need to add flexibility for that.
Another thing I am going to introduce in this notebook is animating the training progress. To do this I am leaning heavily on this stack overflow post. The basic process is to map the centroids and batch points to the same 2 dimensions using PCA:
Code
#collapsefrom __future__ import annotationsfrom dataclasses import dataclass, replaceimport matplotlib.pyplot as pltimport matplotlib.animation as animationimport numpy as npCENTROID_COLORS = np.array([ [1., 0, 0], [0, 0, 1.]])POINT_COLORS = np.array([ [1., 0.5, 0.5], [0.5, 0.5, 1.]])@dataclassclass Points: points: np.ndarray colors: np.ndarray sizes: np.ndarray@staticmethoddef make( points: np.ndarray, labels: np.ndarray, colors: np.ndarray = POINT_COLORS, size: float=10. ) ->None: sizes = np.ones((points.shape[0])) * sizereturn Points( points=points, colors=colors[labels], sizes=sizes, )def decay(self) ->None:self.colors += (1-self.colors) *0.1self.sizes *=0.9@staticmethoddef combine(*points: Points) -> Tuple[np.ndarray, np.ndarray, np.ndarray]: all_points = np.concatenate([point.points for point in points]) all_colors = np.concatenate([point.colors for point in points]) all_sizes = np.concatenate([point.sizes for point in points])return all_points, all_colors, all_sizesclass AnimatedScatter(object):"""An animated scatter plot using matplotlib.animations.FuncAnimation."""def__init__(self, centroids: np.ndarray, batches: np.ndarray, labels: np.ndarray) ->None:self.centroids = [ Points.make( points=centroid, labels=np.array([0, 1]), colors=CENTROID_COLORS, size=100. )for centroid in centroids ]self.batches = [ Points.make(points=batch, labels=label)for batch, label inzip(batches, labels) ] all_points, *_ = Points.combine(*self.centroids, *self.batches)self.axis = [ all_points[:, 0].min() *1.1, all_points[:, 0].max() *1.1, all_points[:, 1].min() *1.1, all_points[:, 1].max() *1.1, ]# Setup the figure and axes...self.fig, self.ax = plt.subplots()# Then setup FuncAnimation.self.ani = animation.FuncAnimation(self.fig,self.update, interval=50, init_func=self.setup_plot, blit=False )def setup_plot(self):"""Initial drawing of the scatter plot.""" x, y =self.batches[0].points.Tself.scat =self.ax.scatter( x, y, )self.ax.axis(self.axis)# For FuncAnimation's sake, we need to return the artist we'll be using# Note that it expects a sequence of artists, thus the trailing comma.returnself.scat,def update(self, i):"""Update the scatter plot.""" all_points, all_colors, all_sizes = Points.combine(*self.batches[:i],self.centroids[i] )self.scat.set_offsets(all_points)self.scat.set_color(all_colors)self.scat.set_sizes(all_sizes)for batch inself.batches[:i]: batch.decay()# We need to return the updated artist for FuncAnimation to draw..# Note that it expects a sequence of artists, thus the trailing comma.returnself.scat,
Let’s give it a go. I’m returning essentially all of the outputs and the centroids at each batch to see if I can animate the progress of the prompt as it trains. I think it will be fun, provided it’s not too memory hungry.
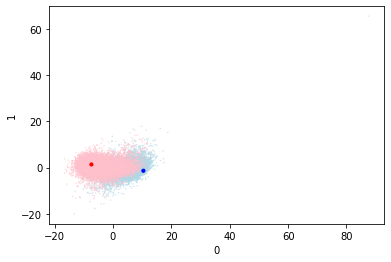
Random Centroid Start
In this I am just going to randomly initialize the centroid positions and see how we get on. While the centroids might start badly, hopefully they can be adjusted into a better position as training proceeds.
We can now look at them in a few different ways - both statistically and visually.
It is clear from the classification report that this is performing very badly. The classifications that it produces are barely better than random chance. We can use the visualizations to explore why this might be.
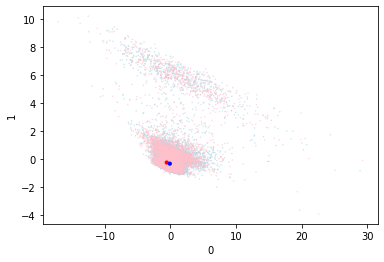
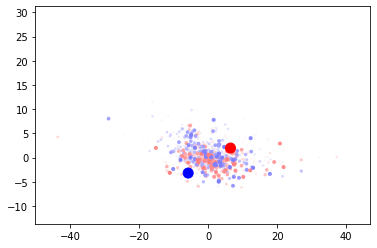
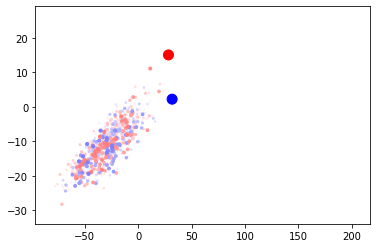
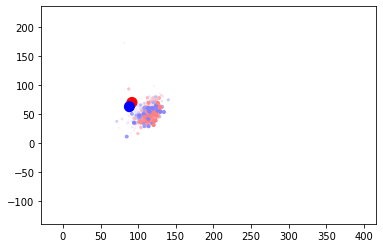
The first visualization is the same PCA clustering that was explored before. We can see that the classes are intermingled. The larger blue dot is the position of the “good” centroid, and the red is the “bad” centroid. While the points are clustered around them they are not separated, and the centroids themselves are very close to each other.
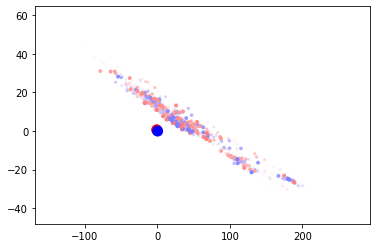
The animation shows the centroid positions and the training batches over time. You can see that the training batches appear more clustered than the validation ones, as they consistently lie on the diagonal. The training batches do slightly close in on the centroids, however the effect is not large. Finally the centroids themselves do not visibly move during training.
Part of the problem statement is that the centroid position is not known in advance, so the fact that the centroids do not move is a problem. A bigger problem is that the centroids are not representative of the data - the position of the centroids is no where near the actual data. Let’s start by moving the centroids closer to the points.
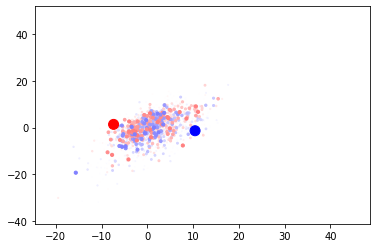
Representative Centroid Start
This time I am going to take a value for each class, pass it through the model, and use it’s output as the centroid starting position. Doing this ensures that the centroids start in a position that is representative of at least one entry in the training set.
Would this approach be improved if the average of all entries in the traning set were used? I think that might result in both centroids being in a very similar position, as the prompt is totally untrained.
Would it be better to take a moving average of the center of each class, and remove the centroids from optimization? It might be - that is something to explore later.
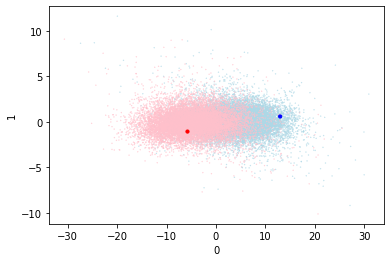
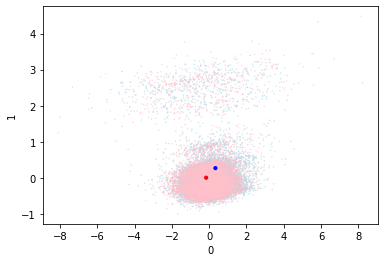
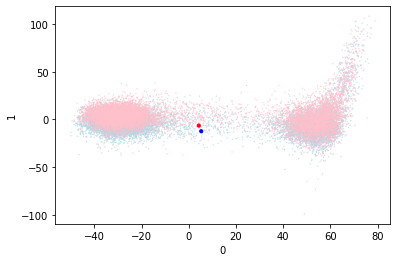
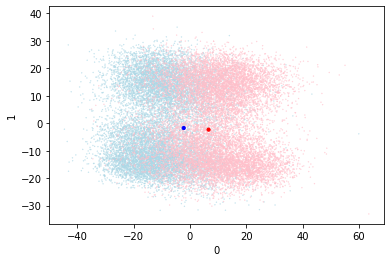
So this simple change has vastly improved the performance, and clearly distinguished the two centroids. This is seen in the validation data visualization which shows a strong distinction between red and blue. If anything the red zone (bad) is larger and that may contribute to the misclassifications.
There does seem to be a tiny amount of centroid movement. I wonder if the centroids would move to a better place for the classification if they were more able to?
Only Train Prompt
I think that the centroid approach has value. There are either bugs with it or the implementation needs quite a bit of tuning. To that end I’m going to try to make it simpler.
One way to make it simpler is to just train the prompt, or just train the centroids. Let’s start by just training the prompt.
from functools import partialtrained_data, training_statistics = train( dl=train_dataloader, model=model, tokenizer=tokenizer, prompt_tokens=5, epochs=3,# no point in including centroid repulsion in loss loss_fn=partial(centroid_loss_fn, distance_factor=100, repulsion_factor=0), centroid_manager=CentroidInitialOutput(), optimizer_factory=make_optimizer_only_prompt,)
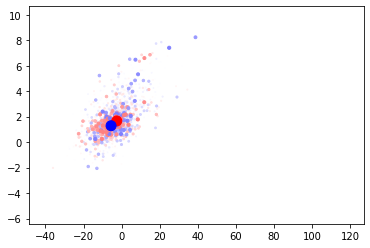
This actually performs better than the previous run. I think that this shows that the position of the centroid matters a great deal. The fact that the centroid cannot move to a better position is a problem.
Boids
I was thinking about this on my walk, and my concern about the asymmetrical nature of the two distance losses (which I will call \(loss_{attraction}\) and \(loss_{repulsion}\)) may be misplaced. The repulsive force becomes overwhelming if points move too close together and so there is an enforced minimum distance between points. I’m reminded of boids which are the simulated version of mumurations
murmuration
The simulation wants each bird to move to the center of the group while maintaining a minimum distance from the other members of the group. It uses a very similar approach to the two proposed loss functions, and the asymmetry does not cause a problem. I wonder how hard it would be to produce a boid simulation using these techniques?
Code
def boid_loss(boids: torch.Tensor) -> torch.Tensor:# This compares every boid to every other boid# This must not compare a boid to itself boid_count = boids.shape[0]# This creates the cartesian join of every index indexes = torch.tensor(range(boid_count)) left_indexes = indexes.repeat(boid_count) right_indexes = indexes.repeat_interleave(boid_count)# This mask filters out the points where an index joins to itself not_same_mask = left_indexes != right_indexes# These are then the expanded aligned comparisons left = boids[left_indexes[not_same_mask]] right = boids[right_indexes[not_same_mask]] distances = torch.pairwise_distance(left, right) want_to_be_near_loss = distances.mean() want_to_be_far_loss = (1/ distances).mean()return want_to_be_near_loss + want_to_be_far_lossdef boid_train() -> np.ndarray: boids = torch.nn.Parameter(torch.rand(10, 2) *10) stats = [boids.clone().detach().cpu().numpy()[None, :]] optimizer = torch.optim.Adam([boids], lr=1e-1)for _ inrange(100): optimizer.zero_grad() loss = boid_loss(boids) loss.backward() optimizer.step() stats.append(boids.clone().detach().cpu().numpy()[None, :])return np.concatenate(stats)
Code
boid_positions = boid_train()
Code
#collapsefrom __future__ import annotationsfrom dataclasses import dataclass, replaceimport matplotlib.pyplot as pltimport matplotlib.animation as animationimport numpy as np@dataclassclass SimplePoint: points: np.ndarray colors: np.ndarray sizes: np.ndarray@staticmethoddef make( points: np.ndarray, colors: np.ndarray = np.array([[.2, .2, .8]]), size: float=10. ) ->None: sizes = np.ones((points.shape[0])) * sizereturn Points( points=points, colors=colors[np.zeros(points.shape[0], dtype=int)], sizes=sizes, )def decay(self) ->None:self.colors += (1-self.colors) *0.1self.sizes *=0.9@staticmethoddef combine(*points: Points) -> Tuple[np.ndarray, np.ndarray, np.ndarray]: all_points = np.concatenate([point.points for point in points]) all_colors = np.concatenate([point.colors for point in points]) all_sizes = np.concatenate([point.sizes for point in points])return all_points, all_colors, all_sizesclass SimpleAnimation(object):"""An animated scatter plot using matplotlib.animations.FuncAnimation."""def__init__(self, batches: np.ndarray) ->None:self.batches = [ SimplePoint.make(points=batch)for batch in batches ]self.axis = [ batches[:, :, 0].min(), batches[:, :, 0].max(), batches[:, :, 1].min(), batches[:, :, 1].max(), ]# Setup the figure and axes...self.fig, self.ax = plt.subplots()# Then setup FuncAnimation.self.ani = animation.FuncAnimation(self.fig,self.update, interval=50, init_func=self.setup_plot, blit=False )def setup_plot(self):"""Initial drawing of the scatter plot.""" x, y =self.batches[0].points[:, 0], self.batches[0].points[:, 1]self.scat =self.ax.scatter( x, y, )self.ax.axis(self.axis)# For FuncAnimation's sake, we need to return the artist we'll be using# Note that it expects a sequence of artists, thus the trailing comma.returnself.scat,def update(self, i):"""Update the scatter plot.""" all_points, all_colors, all_sizes = SimplePoint.combine(*self.batches[:i+1] )self.scat.set_offsets(all_points)self.scat.set_color(all_colors)self.scat.set_sizes(all_sizes)for batch inself.batches[:i+1]: batch.decay()# We need to return the updated artist for FuncAnimation to draw..# Note that it expects a sequence of artists, thus the trailing comma.returnself.scat,
So this works well. The learning rate for the position for the boids needs to be boosted quite extensively to get them moving like this. That’s something to tune when training the model.
I’m going to try moving to this approach.
Attract Me, Repel You
This time I’m going to create the centroid equivalent of the boids training, above. Each point will be attracted to the centroid for it’s class and repelled from the centroid of the other class.
Code
import torchdef attract_repel_loss_fn( output: torch.Tensor, labels: torch.Tensor, centroids: torch.nn.Parameter, attraction_factor: float=1., repulsion_factor: float=1.,) -> torch.Tensor:# only supports two classes for the moment attraction_targets = centroids[labels] repulsion_targets = centroids[(labels ==0).long()] # assumption: label is 0 or 1, this flips it attraction_distance = torch.pairwise_distance(output, attraction_targets) repulsion_distance = torch.pairwise_distance(output, repulsion_targets) attraction_loss = attraction_factor * attraction_distance.mean() repulsion_loss = (repulsion_factor / repulsion_distance).mean()return attraction_loss + repulsion_loss
The centroids really do not want to move. It’s very unlikely that the starting position for them is the best possible position for them. I’m going to try to dislodge them by increasing the learning rate for the centroid parameters.
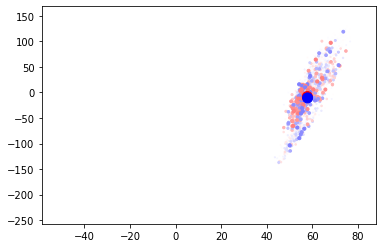
Well that’s pretty bad. They do move but it’s more of an oscillation and the classes don’t neatly separate. If anything the centroids get closer together, making it harder to separate the classes.
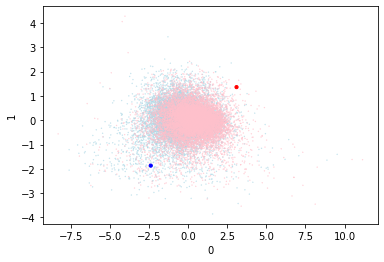
Cross Entropy Centroid Loss
The distance from an output to the two centroids is the main metric that we have. If I make the distance negative then the closest centroid will have the largest value. Then cross entropy loss can be used, as that takes a set of values and a target index, where the index of the highest value is the prediction.
I’m pretty pleased with this relevation. It handles the distance to both in a consistent way and it uses a well established loss metric. Tuning the centroid position may still be required.
Code
import torchdef cross_entropy_centroid_loss( output: torch.Tensor, labels: torch.Tensor, centroids: torch.nn.Parameter,) -> torch.Tensor:# pairwise distance works on 2d tensors so have to iterate# see if cdist works? distances = torch.cat([ torch.pairwise_distance( output[idx], centroids )[None, :]for idx inrange(output.shape[0]) ])return torch.nn.functional.cross_entropy(-distances, labels )
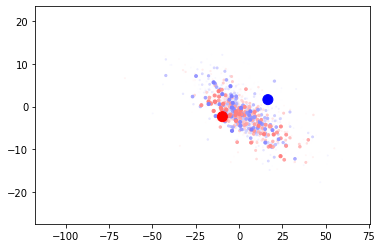
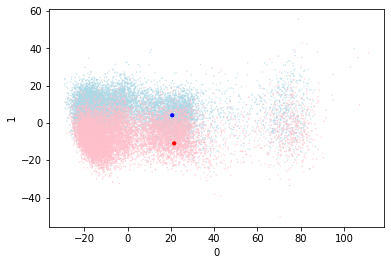
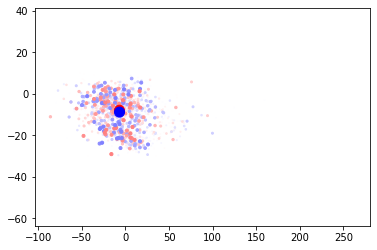
This is a really solid result. The metrics are the best yet and it still leaves an obvious avenue for improvement. When I look at the visualization of the points and the centroids I can see that the centroids are not even near the points.
I feel that moving to a calculated centroid would improve things substantially. I’m going to remove it from training and start updating it manually.
Calculated Centroids
I’m going to be using a few different inputs to the centroid calculation. The first is that the centroid will be the average position of all of the points in the class. Then there is some kind of momentum for the previous centroid position. Finally adding repulsion in to the other centroids would be good.
Code
import torchdef make_optimizer_only_prompt(prompt: torch.nn.Parameter, centroids: torch.nn.Parameter) -> torch.optim.Optimizer:return torch.optim.Adam([prompt], lr=1e-3)@dataclassclass CalculatedCentroid(CentroidInitialOutput): repulsion: float=0.1 momentum: float=0.9@torch.no_grad()def update(self,*, centroids: torch.nn.Parameter, inputs: torch.Tensor, labels: torch.Tensor, ) ->None:"""In place update to the centroids""" updated_centroids = {}for label in labels.unique(): center =self.centroid_center( outputs=inputs, labels=labels, label=label ) repulsion =self.centroid_repulsion( centroids=centroids, index=label, factor=self.repulsion ) updated_centroids[label] = center + repulsionfor label, centroid in updated_centroids.items(): centroids.data[label] =self.centroid_momentum( old=centroids.data[label], new=centroid, factor=self.momentum )def centroid_center(self, outputs: torch.Tensor, labels: torch.Tensor, label: torch.Tensor) -> torch.Tensor:return outputs[labels == label].mean(dim=0)def centroid_repulsion(self, centroids: torch.Tensor, index: int, factor: float) -> torch.Tensor: indexes = [idx for idx inrange(centroids.shape[0]) if idx != index] direction = centroids[indexes].mean(dim=0)return factor * direction / torch.norm(direction)def centroid_momentum(self, old: torch.Tensor, new: torch.Tensor, factor: float) -> torch.Tensor:return (old * factor) + (new * (1- factor))
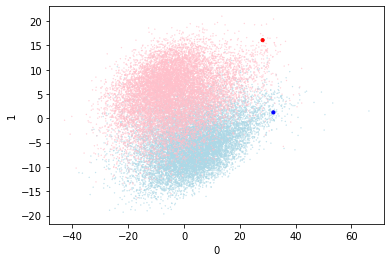
Without repulsion the two points have moved together as the center of the outputs overlaps. I think this is because the outputs have not been separated by the prompt and then the centroid movements make it harder to separate them. Let’s try with a repulsive force between the centroids.
So repulsion helps however the performance isn’t really on a par with the pure cross entropy loss training from before. I’ve realised that the current implementation doesn’t really do momentum, the different parameters are really more of a lethargy (reluctance to move). Maybe actually adding in momentum will help?
I’m going to stop this for now. It’s pretty clear that the centroids are oscillating now and that’s probably the cause of the underlying inaccuracy. If the centroids moved with more purpose then the points could tune up on them.
Maybe I should only update the centroids every few batches?
Anyway I need to use my GPU for something else now so I’m shutting this down.