
I’ve done enough research into prompt training to try to turn it into a paper. The key differentiators to the google paper are:
- Placing the prompt at the end instead of the start
- Using GPT2 models instead of T5
- Using a linear layer at the end to perform classification instead of selecting a token to target
To write the paper it would be good to dramatically simplify the training loop. I think that I have enough to be able to train the model using the huggingface framework by creating a wrapper model that holds the prompt. Working on the code a little is needed to perform more systematic comparisons of the different approaches. I may also want to evaluate this on GLUE or a similar more popular challenge. Finally comparing the performance to fine tuning the model would provide a good baseline - does the linear layer and prompt together make the model as good as fine tuning?
Retreating to writing more code is a retreat to safety for me - I am very good at writing code. To get some progress on this I should write some of the paper, and that is what this post is for. I am going to fill this out with the different sections and the progress so far, and things like prompt training in huggingface can move to another post.
How to Write a Paper
I have read quite a few papers and I have spoken to people who have written papers. I’ve been told that I have done enough research for a paper, so that is why I am trying this. The problem is that I have never written a paper so how do I actually do that?
googles “how to write a paper”
I’ve immediately found this manual by Mike Ashby at the University of Cambridge. Looks like I’ve got a bit of reading to do. It seems really good.
It outlines the process of creating a paper as the following 5 stages:
The first thing is to identify the market need. This is the audience for the paper. It suggests three main audiences:
- Examiners - of a university degree thesis
- Scientists - of an academic paper
- Lay people - of an article on a scientific subject
For my paper the audience will be data scientists interested in a new technique.
Then the ideating occurs. This is done on a large piece of paper and involves outlining the different sections and providing a tiny bit of detail for each. The title of the paper and the first line of the abstract are about as detailed as it gets.
I’ve done this, possibly rather poorly.
Title:
Suffix Prompt Training for Efficient Classification
Could be low resource instead of efficient? The tutorial said that the title should be brief rather than complete, so it might be enough to be Suffix Prompt Training.
Abstract
- Mention Google Paper
- Prefix vs Suffix
- Classification tasks
- Using tokens vs linear layer
- Multi task performance
Method
- Prompt training
- Token vs Linear head
- Prompting in real life often comes after the information
- Selection of correct tokens for classifications is hard, using a linear head is equivalent and optimizable
Results
- Vary model size - gpt2-small gpt2-medium gpt2-large gptneo-1.3
- Vary prompt size
- Vary task
- Compare with fine tuning
- Compare with prefix prompting?
- Train for two tasks at once (combine separately trained linear layer?)
Discussion
- Suffix prompting could be better than prefix for some tasks
- Performs well compared to fine tuning
- Cheap to run
- Can do multiple tasks in a batch
- Can use past optimization to implement efficiently
The main thrust of the paper is being able to perform tasks cheaply with only a modest loss in accuracy. Optimising for cheaply performing tasks is quite important. Having working code that uses the past_key_values, as well as prompts trained on multiple different tasks.
Just Copy My Blog Posts
I spoke about this with a colleague and they said that there were two broad approaches to paper writing, one good and one bad.

He was inclined towards the thinker approach and found the final step of pulling the notes together to be overwhelming. At that point there was much too much material to go through and all of it was only partially formed.
The experimenter does more work up front by writing up the results of each experiment, but when it comes time to pull that together the source material is far more solid. That up front work makes it much easier to get the skeleton of a paper. By writing this blog I have followed the experimenter route.
So I need to make my skeleton by only copying text from the existing blog posts. That will be a terrible start but I can work with that.
Abstract
The original post I wrote about prompt training has a good introduction:
I’ve been thinking about Language Model prompts recently. They can be used to perform natural language tasks without retraining. This is due to the deep understanding that modern language models internalize as part of the training. GPT-3 has even internalized enough to start being able to perform arithmetic.
The biggest problem is coming up with an appropriate prompt for the task. So maybe data science is the search for the best prompt?
I speak adequate English and no other languages. I am unlikely to write a poem or become a wordsmith. Inventing an appropriate prompt seems to be a hard problem.
I don’t want to spend time trying to come up with ways to trick the language model into providing the results I want. Tricking language models won’t make me a better writer. It would be better to come up with a way to produce the correct prompt from the input and results, much like how a neural net works to begin with.
DeepDream was created in 2014 and involves using back propagation to alter the input instead of the model. The input is changed to produce a certain kind of strong output, which leads to psychedelic imagery.
I want to perform this same approach using a language model. The prompt is part of the input to the language model and I want to “train” the prompt to perform the task that I desire.
I need to cut this down into a readable abstract. The base of this has already been established by google so it might be good to cover the suffix / prefix difference?
I was specifically told not to make this section perfect otherwise I would obsess over it and it might change because of subsequent sections anyway. So this has problems, I accept that. Moving on.
Method
That first post really is great. I wrote it to explain this idea and it covers all of this very well.
So how is this going to work? Let’s start with an idea of how a neural network is trained.
An optimizer collects model parameters that are to be optimized. The input to the model is passed through the model and the influence that the parameters have over the output quality is tracked. Quality must be a positive scalar value where lower is better.
This quality is referred to as the loss, and a loss of zero is produced by the best model possible.
When deep dreaming the model is not the target of the optimizer, instead the input is.
This means that the adjustments that the optimizer makes change the input image instead of the model. In the same way I want to change the prompt. The prompt is unusual though as it is normally part of the input instead of the whole input.
This is where GPT-2 is useful. GPT-2 has the ability to use previously computed output as part of the calculation, referred to as the past. This is a separate input. By pushing the tweet text to the past I can easily define the prompt as an optimizable parameter.
This is a good start but it’s not enough. The prompt is text, which can’t be optimized because it’s not a tensor. The tokenized prompt is a long tensor, which can’t be optimized because it’s not continuous.
The first stage of a language model is an embedding layer. This is a simple layer that converts each token into a 1 dimensional float tensor, so the sequence of tokens becomes a 2 dimensional float tensor. At this point it can be optimized.
This involves altering the model though, as the GPT-2 model is expecting to receive the tokenized prompt as it’s input. So a little surgery is required.
I should strip the talk of the past from this and it would be nice to have appropriate graphics.
Results
To do this nicely I should make tables that have bold numbers as well as graphs. I’ve been running some sweeps for this paper in wandb so I need to export the metrics for them. Luckily there is documentation to do that.
This is their example code:
Code
import wandb
api = wandb.Api()
runs = api.runs("matthewfranglen/prompt-training")
summary_list = []
config_list = []
name_list = []
for run in runs:
# run.summary are the output key/values like accuracy. We call ._json_dict to omit large files
summary_list.append(run.summary._json_dict)
# run.config is the input metrics. We remove special values that start with _.
config_list.append({k:v for k,v in run.config.items() if not k.startswith('_')})
# run.name is the name of the run.
name_list.append(run.name)
import pandas as pd
summary_df = pd.DataFrame.from_records(summary_list)
config_df = pd.DataFrame.from_records(config_list)
name_df = pd.DataFrame({'name': name_list})
all_df = pd.concat([name_df, config_df,summary_df], axis=1)Code
all_df| name | fp16 | seed | debug | model | n_ctx | round | top_k | top_p | epochs | ... | gradients/transformer.h.18.mlp.c_proj.bias | gradients/transformer.h.16.mlp.c_proj.bias | gradients/transformer.h.23.ln_2.bias | gradients/transformer.h.4.mlp.c_proj.bias | train/train_samples_per_second | train/train_loss | train/total_flos | train/train_steps_per_second | train/train_runtime | gradients/input_extension | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | gpt2-large_model_prefix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | {'values': [1, 0, 0, 0, 1, 1, 2, 2, 2, 2, 1, 2... | {'values': [1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 3... | {'values': [1, 0, 0, 0, 1, 2, 2, 2, 2, 5, 3, 1... | {'_type': 'histogram', 'bins': [-0.01849125325... | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | gpt2-large_model_prefix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.01344758830... | {'values': [1, 0, 0, 1, 3, 2, 2, 4, 8, 4, 5, 6... | {'values': [1, 0, 1, 1, 0, 1, 0, 3, 3, 4, 8, 7... | {'bins': [-0.024627190083265305, -0.0238870475... | 48.956 | 0.487356 | 1.060810e+17 | 3.060 | 13756.9291 | NaN |
| 2 | gpt2-medium_model_prefix-prompt_model-type_10_... | False | 42 | [] | gpt2-medium | 1024 | 0.0 | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.00144530110... | {'values': [2, 0, 0, 0, 0, 1, 1, 0, 0, 3, 4, 3... | {'_type': 'histogram', 'bins': [-0.00943612959... | {'_type': 'histogram', 'values': [1, 1, 2, 2, ... | 77.971 | 0.707936 | 5.564736e+16 | 2.437 | 8637.7444 | NaN |
| 3 | gpt2-medium_model_prefix-prompt_model-type_10_... | False | 42 | [] | gpt2-medium | 1024 | 0.0 | 50 | 1 | 10 | ... | {'bins': [-0.0018060412257909775, -0.001741327... | {'bins': [-0.0018799628596752882, -0.001808310... | {'_type': 'histogram', 'bins': [-0.01162351667... | {'_type': 'histogram', 'bins': [-0.00215399940... | 84.548 | 0.696624 | 5.564656e+16 | 2.643 | 7965.7900 | NaN |
| 4 | gpt2-medium_model_prefix-prompt_model-type_10_... | False | 42 | [] | gpt2-medium | 1024 | 0.0 | 50 | 1 | 10 | ... | {'values': [1, 1, 0, 4, 0, 0, 1, 3, 3, 4, 6, 5... | {'values': [1, 0, 1, 0, 2, 1, 0, 0, 5, 7, 5, 1... | {'_type': 'histogram', 'bins': [-0.02058961242... | {'_type': 'histogram', 'values': [1, 0, 0, 0, ... | 92.661 | 0.685788 | 5.564576e+16 | 2.896 | 7268.3196 | NaN |
| 5 | gpt2-medium_model_prefix-prompt_model-type_10_... | False | 42 | [] | gpt2-medium | 1024 | 0.0 | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.00510465633... | {'values': [1, 1, 0, 1, 0, 2, 1, 3, 1, 2, 3, 1... | {'values': [1, 0, 1, 0, 1, 0, 4, 1, 3, 4, 4, 1... | {'_type': 'histogram', 'bins': [-0.00656862184... | 102.069 | 0.649759 | 5.564495e+16 | 3.190 | 6598.3986 | NaN |
| 6 | gpt2-medium_model_prefix-prompt_model-type_10_... | False | 42 | [] | gpt2-medium | 1024 | 0.0 | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.01135736331... | {'_type': 'histogram', 'values': [1, 0, 0, 0, ... | {'_type': 'histogram', 'bins': [-0.04558126628... | {'values': [1, 0, 0, 0, 2, 1, 2, 3, 0, 0, 6, 6... | 111.768 | 0.508424 | 5.564431e+16 | 3.493 | 6025.7818 | NaN |
| 7 | gpt2_model_prefix-prompt_model-type_10_epochs_... | False | 42 | [] | gpt2 | 1024 | 0.0 | 50 | 1 | 10 | ... | NaN | NaN | NaN | {'_type': 'histogram', 'bins': [-0.00101139291... | 239.989 | 0.692224 | 1.951746e+16 | 7.501 | 2806.3330 | NaN |
| 8 | gpt2_model_prefix-prompt_model-type_10_epochs_... | False | 42 | [] | gpt2 | 1024 | 0.0 | 50 | 1 | 10 | ... | NaN | NaN | NaN | {'values': [1, 0, 1, 1, 0, 0, 1, 0, 1, 0, 0, 2... | 263.760 | 0.684473 | 1.951686e+16 | 8.244 | 2553.4193 | NaN |
| 9 | gpt2_model_prefix-prompt_model-type_10_epochs_... | False | 42 | [] | gpt2 | 1024 | 0.0 | 50 | 1 | 10 | ... | NaN | NaN | NaN | {'_type': 'histogram', 'values': [1, 0, 0, 0, ... | 282.572 | 0.659188 | 1.951626e+16 | 8.832 | 2383.4241 | NaN |
| 10 | gpt2_model_prefix-prompt_model-type_10_epochs_... | False | 42 | [] | gpt2 | 1024 | 0.0 | 50 | 1 | 10 | ... | NaN | NaN | NaN | {'_type': 'histogram', 'values': [1, 0, 1, 0, ... | 311.006 | 0.643057 | 1.951566e+16 | 9.721 | 2165.5205 | NaN |
| 11 | gpt2_model_prefix-prompt_model-type_10_epochs_... | False | 42 | [] | gpt2 | 1024 | 0.0 | 50 | 1 | 10 | ... | NaN | NaN | NaN | {'_type': 'histogram', 'values': [1, 2, 2, 1, ... | 344.208 | 0.526910 | 1.951517e+16 | 10.758 | 1956.6378 | NaN |
| 12 | gpt2-large_model_suffix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | {'values': [1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0... | {'values': [2, 0, 0, 1, 2, 2, 1, 4, 6, 1, 5, 1... | {'bins': [-0.006419372744858265, -0.0062074009... | {'values': [1, 1, 1, 3, 4, 4, 6, 4, 8, 8, 11, ... | 34.291 | 0.317935 | 1.060878e+17 | 2.144 | 19640.4549 | {'bins': [-0.0005494012730196118, -0.000532238... |
| 13 | gpt2-large_model_suffix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.00422320188... | {'_type': 'histogram', 'bins': [-0.00436296034... | {'_type': 'histogram', 'bins': [-0.00244044559... | {'_type': 'histogram', 'bins': [-0.00771678425... | 37.144 | 0.348722 | 1.060861e+17 | 2.322 | 18131.6393 | {'_type': 'histogram', 'bins': [-0.00345833227... |
| 14 | gpt2-large_model_suffix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | {'values': [1, 0, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1... | {'_type': 'histogram', 'bins': [-0.01896799728... | {'_type': 'histogram', 'bins': [-0.00777081586... | {'bins': [-0.01550107728689909, -0.01499922666... | 40.247 | 0.305307 | 1.060843e+17 | 2.516 | 16733.7893 | {'values': [1, 0, 0, 1, 3, 3, 3, 0, 2, 8, 13, ... |
| 15 | gpt2-large_model_suffix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | {'values': [1, 2, 0, 1, 3, 1, 2, 2, 3, 3, 1, 6... | {'values': [1, 5, 3, 1, 6, 4, 2, 10, 7, 11, 17... | {'_type': 'histogram', 'bins': [-0.00077923014... | {'_type': 'histogram', 'bins': [-0.00125554483... | 44.201 | 0.308146 | 1.060826e+17 | 2.763 | 15237.0541 | {'_type': 'histogram', 'bins': [-0.00090658687... |
| 16 | gpt2-large_model_suffix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.00439604464... | {'_type': 'histogram', 'bins': [-0.00469387555... | {'_type': 'histogram', 'bins': [-0.00408640597... | {'values': [1, 0, 0, 0, 0, 1, 0, 2, 4, 3, 3, 2... | 48.194 | 0.314865 | 1.060811e+17 | 3.013 | 13974.4535 | {'_type': 'histogram', 'bins': [-0.00595530960... |
| 17 | gpt2-large_model_suffix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.00197306647... | {'_type': 'histogram', 'bins': [-0.00261437473... | {'values': [1, 0, 0, 1, 1, 2, 0, 1, 4, 1, 5, 3... | {'_type': 'histogram', 'bins': [-0.00493339728... | 34.241 | 0.121672 | 1.060876e+17 | 2.140 | 19669.1429 | {'bins': [-0.0018333703046664596, -0.001767404... |
| 18 | gpt2-large_model_suffix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.00269448617... | {'bins': [-0.0034013791009783745, -0.003291144... | {'_type': 'histogram', 'bins': [-0.00252108718... | {'bins': [-0.010219709016382694, -0.0099595328... | 37.008 | 0.107422 | 1.060859e+17 | 2.313 | 18198.2685 | {'_type': 'histogram', 'bins': [-0.00186982809... |
| 19 | gpt2-large_model_suffix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | {'values': [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 3... | {'values': [4, 3, 3, 3, 3, 3, 4, 8, 7, 9, 10, ... | {'_type': 'histogram', 'bins': [-0.00115308142... | {'_type': 'histogram', 'values': [1, 0, 1, 0, ... | 40.342 | 0.109080 | 1.060841e+17 | 2.522 | 16694.5818 | {'_type': 'histogram', 'values': [1, 0, 2, 2, ... |
| 20 | gpt2-large_model_suffix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | {'bins': [-0.001987889176234603, -0.0019241998... | {'_type': 'histogram', 'bins': [-0.00298999925... | {'_type': 'histogram', 'bins': [-0.00240818993... | {'_type': 'histogram', 'bins': [-0.00448812264... | 44.505 | 0.109463 | 1.060824e+17 | 2.782 | 15132.8876 | {'_type': 'histogram', 'bins': [-0.00267837755... |
| 21 | gpt2-large_model_suffix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | {'_type': 'histogram', 'values': [1, 0, 0, 0, ... | {'_type': 'histogram', 'bins': [-0.00231365184... | {'_type': 'histogram', 'bins': [-0.00184366910... | {'_type': 'histogram', 'bins': [-0.00387635990... | 48.693 | 0.120755 | 1.060810e+17 | 3.044 | 13831.4925 | {'_type': 'histogram', 'values': [3, 0, 2, 0, ... |
| 22 | gpt2-medium_model_suffix-prompt_model-type_10_... | False | 42 | [] | gpt2-medium | 1024 | 0.0 | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.00678156362... | {'_type': 'histogram', 'bins': [-0.00684588169... | {'bins': [-0.07772248983383179, -0.07549932599... | {'_type': 'histogram', 'bins': [-0.01199907995... | 75.973 | 0.426049 | 5.565057e+16 | 2.375 | 8864.8318 | {'values': [1, 0, 2, 0, 1, 0, 1, 3, 1, 3, 6, 4... |
| 23 | gpt2-medium_model_suffix-prompt_model-type_10_... | False | 42 | [] | gpt2-medium | 1024 | NaN | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.00270534027... | {'bins': [-0.004261664114892483, -0.0041233287... | {'values': [1, 0, 1, 2, 3, 4, 3, 4, 6, 1, 4, 5... | {'_type': 'histogram', 'bins': [-0.00980937108... | 82.573 | 0.435361 | 5.564897e+16 | 2.581 | 8156.3290 | {'bins': [-0.005265606101602316, -0.0050871353... |
| 24 | gpt2-medium_model_suffix-prompt_model-type_10_... | False | 42 | [] | gpt2-medium | 1024 | NaN | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.00444102426... | {'values': [2, 0, 1, 0, 1, 0, 2, 1, 4, 0, 3, 8... | {'_type': 'histogram', 'bins': [-0.02033426798... | {'_type': 'histogram', 'bins': [-0.01074663270... | 90.623 | 0.419063 | 5.564736e+16 | 2.832 | 7431.7712 | {'values': [1, 0, 0, 0, 0, 0, 1, 2, 0, 2, 0, 5... |
| 25 | gpt2-medium_model_suffix-prompt_model-type_10_... | False | 42 | [] | gpt2-medium | 1024 | NaN | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.00236538005... | {'values': [1, 0, 0, 0, 0, 1, 0, 1, 1, 2, 1, 5... | {'_type': 'histogram', 'bins': [-0.01463427394... | {'values': [1, 1, 1, 0, 1, 2, 0, 2, 3, 3, 6, 7... | 100.305 | 0.392540 | 5.564576e+16 | 3.135 | 6714.3977 | {'_type': 'histogram', 'values': [3, 0, 0, 0, ... |
| 26 | gpt2-medium_model_suffix-prompt_model-type_10_... | False | 42 | [] | gpt2-medium | 1024 | NaN | 50 | 1 | 10 | ... | {'_type': 'histogram', 'bins': [-0.00261635938... | {'_type': 'histogram', 'bins': [-0.00293804891... | {'bins': [-0.023470813408493996, -0.0228090193... | {'_type': 'histogram', 'bins': [-0.00667972397... | 110.617 | 0.427815 | 5.564447e+16 | 3.457 | 6088.5114 | {'bins': [-0.006627310533076525, -0.0064125214... |
| 27 | gpt2_model_suffix-prompt_model-type_10_epochs_... | False | 42 | [] | gpt2 | 1024 | NaN | 50 | 1 | 10 | ... | NaN | NaN | NaN | {'bins': [-0.008618958294391632, -0.0083488197... | 235.791 | 0.456089 | 1.951987e+16 | 7.370 | 2856.3001 | {'_type': 'histogram', 'bins': [-0.00178531918... |
| 28 | gpt2_model_suffix-prompt_model-type_10_epochs_... | False | 42 | [] | gpt2 | 1024 | NaN | 50 | 1 | 10 | ... | NaN | NaN | NaN | {'_type': 'histogram', 'bins': [-0.00743164308... | 255.644 | 0.457330 | 1.951867e+16 | 7.990 | 2634.4842 | {'bins': [-0.00450912956148386, -0.00436404626... |
| 29 | gpt2_model_suffix-prompt_model-type_10_epochs_... | False | 42 | [] | gpt2 | 1024 | NaN | 50 | 1 | 10 | ... | NaN | NaN | NaN | {'_type': 'histogram', 'bins': [-0.01072437688... | 279.802 | 0.437861 | 1.951746e+16 | 8.745 | 2407.0266 | {'_type': 'histogram', 'bins': [-0.00349625479... |
| 30 | gpt2_model_suffix-prompt_model-type_10_epochs_... | False | 42 | [] | gpt2 | 1024 | NaN | 50 | 1 | 10 | ... | NaN | NaN | NaN | {'bins': [-0.00825427658855915, -0.00781507231... | 308.525 | 0.452944 | 1.951626e+16 | 9.643 | 2182.9378 | {'_type': 'histogram', 'bins': [-0.01047926023... |
| 31 | gpt2_model_suffix-prompt_model-type_10_epochs_... | False | 42 | [] | gpt2 | 1024 | NaN | 50 | 1 | 10 | ... | NaN | NaN | NaN | {'_type': 'histogram', 'bins': [-0.01043631508... | 342.543 | 0.454971 | 1.951529e+16 | 10.706 | 1966.1449 | {'_type': 'histogram', 'bins': [-0.00659146998... |
| 32 | gpt2_model_5_prompt-tokens_5_epochs_128_batch-... | False | 42 | [] | gpt2 | 1024 | NaN | 50 | 1 | 5 | ... | NaN | NaN | NaN | {'bins': [-0.006810349877923727, -0.0065916357... | 294.992 | 0.552810 | 1.187000e+16 | 2.308 | 1141.5412 | {'bins': [-0.0059301843866705894, -0.005713565... |
33 rows × 612 columns
So this is pretty big and it seems comprehensive. I’m interested in the combination of accuracy, prompt-tokens, model-name.
Code
all_df[["model", "model-type", "prompt-tokens", "eval/accuracy"]].sort_values(by="eval/accuracy")| model | model-type | prompt-tokens | eval/accuracy | |
|---|---|---|---|---|
| 21 | gpt2-large | suffix-prompt | 1 | 0.490826 |
| 20 | gpt2-large | suffix-prompt | 5 | 0.490826 |
| 19 | gpt2-large | suffix-prompt | 10 | 0.490826 |
| 18 | gpt2-large | suffix-prompt | 15 | 0.490826 |
| 17 | gpt2-large | suffix-prompt | 20 | 0.490826 |
| 7 | gpt2 | prefix-prompt | 20 | 0.542431 |
| 2 | gpt2-medium | prefix-prompt | 20 | 0.545872 |
| 3 | gpt2-medium | prefix-prompt | 15 | 0.596330 |
| 8 | gpt2 | prefix-prompt | 15 | 0.629587 |
| 0 | gpt2-large | prefix-prompt | 5 | 0.647936 |
| 4 | gpt2-medium | prefix-prompt | 10 | 0.682339 |
| 9 | gpt2 | prefix-prompt | 10 | 0.715596 |
| 10 | gpt2 | prefix-prompt | 5 | 0.763761 |
| 5 | gpt2-medium | prefix-prompt | 5 | 0.771789 |
| 32 | gpt2 | NaN | 5 | 0.810780 |
| 31 | gpt2 | suffix-prompt | 1 | 0.831422 |
| 11 | gpt2 | prefix-prompt | 1 | 0.839450 |
| 6 | gpt2-medium | prefix-prompt | 1 | 0.840596 |
| 28 | gpt2 | suffix-prompt | 15 | 0.841743 |
| 30 | gpt2 | suffix-prompt | 5 | 0.855505 |
| 27 | gpt2 | suffix-prompt | 20 | 0.858945 |
| 22 | gpt2-medium | suffix-prompt | 20 | 0.860092 |
| 29 | gpt2 | suffix-prompt | 10 | 0.861239 |
| 1 | gpt2-large | prefix-prompt | 1 | 0.875000 |
| 26 | gpt2-medium | suffix-prompt | 1 | 0.886468 |
| 23 | gpt2-medium | suffix-prompt | 15 | 0.889908 |
| 24 | gpt2-medium | suffix-prompt | 10 | 0.891055 |
| 25 | gpt2-medium | suffix-prompt | 5 | 0.893349 |
| 15 | gpt2-large | suffix-prompt | 5 | 0.918578 |
| 16 | gpt2-large | suffix-prompt | 1 | 0.918578 |
| 13 | gpt2-large | suffix-prompt | 15 | 0.920872 |
| 14 | gpt2-large | suffix-prompt | 10 | 0.928899 |
| 12 | gpt2-large | suffix-prompt | 20 | 0.930046 |
The problem here is that it does not appear to be the graph of the values, it’s just the last reported value.
Code
import wandb
api = wandb.Api()
runs = api.runs("matthewfranglen/prompt-training")
history_list = {}
config_list = {}
for run in runs:
name = run.name
accuracy = run.summary._json_dict["eval/accuracy"]
# skip the runs where the model was accidentally a regressor
if accuracy == 0.4908256880733945:
print(f"skipped bad run: {name} - {accuracy}")
continue
history_list[name] = run.history()
config_list[name] = {k:v for k,v in run.config.items() if not k.startswith('_')}skipped bad run: gpt2-large_model_suffix-prompt_model-type_10_epochs_16_batch-size_20_prompt-tokens_4944e - 0.4908256880733945
skipped bad run: gpt2-large_model_suffix-prompt_model-type_10_epochs_16_batch-size_15_prompt-tokens_1ac14 - 0.4908256880733945
skipped bad run: gpt2-large_model_suffix-prompt_model-type_10_epochs_16_batch-size_10_prompt-tokens_6f6a7 - 0.4908256880733945
skipped bad run: gpt2-large_model_suffix-prompt_model-type_10_epochs_16_batch-size_5_prompt-tokens_cd420 - 0.4908256880733945
skipped bad run: gpt2-large_model_suffix-prompt_model-type_10_epochs_16_batch-size_1_prompt-tokens_ee6ac - 0.4908256880733945Code
import pandas as pd
all_df = pd.DataFrame([
{"name": name, **config, **row}
for name, config in config_list.items()
for row in history_list[name].iloc
])Code
all_df| name | fp16 | seed | debug | model | n_ctx | round | top_k | top_p | epochs | ... | eval/samples_per_second | eval/runtime | train/train_loss | train/train_steps_per_second | train/train_samples_per_second | train/train_runtime | train/total_flos | n_special | predict_special_tokens | gradients/input_extension | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | gpt2-large_model_prefix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | gpt2-large_model_prefix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | gpt2-large_model_prefix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | gpt2-large_model_prefix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | gpt2-large_model_prefix-prompt_model-type_10_e... | False | 42 | [] | gpt2-large | 1024 | 0.0 | 50 | 1 | 10 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 7183 | gpt2_model_5_prompt-tokens_5_epochs_128_batch-... | False | 42 | [] | gpt2 | 1024 | NaN | 50 | 1 | 5 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | {'values': [2, 1, 1, 2, 0, 2, 1, 1, 2, 3, 5, 1... |
| 7184 | gpt2_model_5_prompt-tokens_5_epochs_128_batch-... | False | 42 | [] | gpt2 | 1024 | NaN | 50 | 1 | 5 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | {'_type': 'histogram', 'packedBins': {'min': -... |
| 7185 | gpt2_model_5_prompt-tokens_5_epochs_128_batch-... | False | 42 | [] | gpt2 | 1024 | NaN | 50 | 1 | 5 | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | {'_type': 'histogram', 'packedBins': {'size': ... |
| 7186 | gpt2_model_5_prompt-tokens_5_epochs_128_batch-... | False | 42 | [] | gpt2 | 1024 | NaN | 50 | 1 | 5 | ... | 774.21 | 1.1263 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 7187 | gpt2_model_5_prompt-tokens_5_epochs_128_batch-... | False | 42 | [] | gpt2 | 1024 | NaN | 50 | 1 | 5 | ... | NaN | NaN | 0.55281 | 2.308 | 294.992 | 1141.5412 | 1.187000e+16 | NaN | NaN | NaN |
7188 rows × 611 columns
Code
accuracy_df = (
all_df[
~all_df["eval/accuracy"].isna()
]
[["model", "model-type", "prompt-tokens", "train/epoch", "eval/accuracy"]]
.rename(columns={"train/epoch": "epoch", "eval/accuracy": "accuracy"})
)Code
accuracy_df.groupby(by=["model", "model-type", "prompt-tokens"]).agg(max)| epoch | accuracy | |||
|---|---|---|---|---|
| model | model-type | prompt-tokens | ||
| gpt2 | prefix-prompt | 1 | 10.0 | 0.839450 |
| 5 | 10.0 | 0.763761 | ||
| 10 | 10.0 | 0.715596 | ||
| 15 | 10.0 | 0.629587 | ||
| 20 | 10.0 | 0.542431 | ||
| suffix-prompt | 1 | 10.0 | 0.832569 | |
| 5 | 10.0 | 0.864679 | ||
| 10 | 10.0 | 0.861239 | ||
| 15 | 10.0 | 0.856651 | ||
| 20 | 10.0 | 0.870413 | ||
| gpt2-large | prefix-prompt | 1 | 10.0 | 0.883028 |
| 5 | 10.0 | 0.756881 | ||
| 10 | 10.0 | 0.709862 | ||
| 15 | 10.0 | 0.600917 | ||
| 20 | 10.0 | 0.580275 | ||
| suffix-prompt | 1 | 10.0 | 0.919725 | |
| 5 | 10.0 | 0.923165 | ||
| 10 | 10.0 | 0.931193 | ||
| 15 | 10.0 | 0.930046 | ||
| 20 | 10.0 | 0.930046 | ||
| gpt2-medium | prefix-prompt | 1 | 10.0 | 0.842890 |
| 5 | 10.0 | 0.785550 | ||
| 10 | 10.0 | 0.682339 | ||
| 15 | 10.0 | 0.596330 | ||
| 20 | 10.0 | 0.545872 | ||
| suffix-prompt | 1 | 10.0 | 0.886468 | |
| 5 | 10.0 | 0.893349 | ||
| 10 | 10.0 | 0.893349 | ||
| 15 | 10.0 | 0.889908 | ||
| 20 | 10.0 | 0.864679 |
Code
accuracy_df.groupby(by=["model", "model-type"]).agg(max)| prompt-tokens | epoch | accuracy | ||
|---|---|---|---|---|
| model | model-type | |||
| gpt2 | prefix-prompt | 20 | 10.0 | 0.839450 |
| suffix-prompt | 20 | 10.0 | 0.870413 | |
| gpt2-large | prefix-prompt | 20 | 10.0 | 0.883028 |
| suffix-prompt | 20 | 10.0 | 0.931193 | |
| gpt2-medium | prefix-prompt | 20 | 10.0 | 0.842890 |
| suffix-prompt | 20 | 10.0 | 0.893349 |
This is nice as it shows that prefix prompting isn’t the best. I want to be able to turn this into a graph too.
Code
accuracy_df.loc[accuracy_df["model-type"].isna(), "model-type"] = "suffix-prompt"Code
from typing import *
def show_comparison(df: pd.DataFrame, column: str, **limits: Any) -> None:
df = compare(df, column, **limits)
df.plot(title=f"{limits['model']} accuracy", ylim=(0,1))
def compare(df: pd.DataFrame, column: str, **limits: Any) -> pd.DataFrame:
base = df
for limit, value in limits.items():
base = base[base[limit] == value]
values = df[column].unique()
if values.size == 0:
return pd.DataFrame()
frames = [
base[base[column] == value]
.sort_values(by="epoch")
.drop(columns=limits.keys())
.drop(columns=["epoch", column])
.reset_index(drop=True)
.rename(columns={"accuracy": value})
for value in values
]
return pd.concat(frames, axis=1)Code
for model_name in accuracy_df.model.unique():
show_comparison(
accuracy_df,
column="model-type",
model=model_name,
**{"prompt-tokens": 20}
)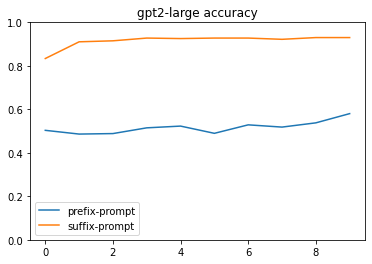
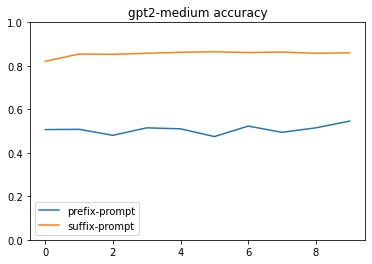
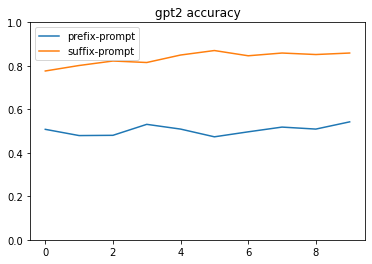
For this I need to wait for the gpt2-large prefix training to complete. These graphs look pretty convincing.
I said that I didn’t want to spend too long on any one section, and here I am doing programming. On to the next section.
Discussion
WOO SUFFIX PROMPT WOO
Maybe this is only better for GPT2? This has performance benefits which make multi classification more efficient (gpt2 past, unidirectional model). Proximity of prompt to prediction may be related. This uses a classification head, could try doing semantic training.
Why does this work at all? Is it possible to find words that produce a similar output?