Code
from pathlib import Path
DATA_FOLDER = Path("/data/blog/2021-10-20-yolo-clip-open-images")
DATA_FOLDER.mkdir(parents=True, exist_ok=True)
IMAGE_FOLDER = Path(".").resolve()
IMAGE_FOLDER.mkdir(parents=True, exist_ok=True)I want to try out using YOLO + CLIP to do object detection. YOLO is an efficient bounding box detector which takes quite a bit of effort to post process the output to collect the image boundaries. CLIP is a pair of models, one which encodes text and the other encodes the image. Then the most similar text to the image is considered to be the best available description of the imaeg. If I can pair these two together then it should be possible to come up with an e
I’ve downloaded \(\frac{1}{16}\)th of the open images data as well as the test and validation datasets. This should be enough to try it all out together and then we can see how good it is without training.
from pathlib import Path
DATA_FOLDER = Path("/data/blog/2021-10-20-yolo-clip-open-images")
DATA_FOLDER.mkdir(parents=True, exist_ok=True)
IMAGE_FOLDER = Path(".").resolve()
IMAGE_FOLDER.mkdir(parents=True, exist_ok=True)To get yolo v5 working I first need to install the requirements. They are listed here. It’s easy enough to add them to the poetry env for this blog:
poetry add \
matplotlib numpy opencv-python \
Pillow PyYAML requests scipy \
torch torchvision tqdm \
tensorboard pandas seabornIt takes a moment to think about it, however everything installed without a hitch.
Loading the model is quite easy and is a chance to use torch.hub. This creates the model by loading a python file from the provided repository.
#hide_output
import torch
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)Using cache found in /home/matthew/.cache/torch/hub/ultralytics_yolov5_master
YOLOv5 🚀 2021-10-20 torch 1.8.1+cu102 CUDA:0 (NVIDIA TITAN RTX, 24220.3125MB)
Fusing layers...
Model Summary: 213 layers, 7225885 parameters, 0 gradients
Adding AutoShape... It’s quite fun to push images through the model and see the results. To keep this focused I’m going to collapse the images following the first, you can expand them if you want to look at them. The later images are more busy and you can see the limitations of the model - a very busy model with small items will result in a lot of missing boxes.
def show_boxes(*images: str) -> None:
results = model(list(images))
results.save(IMAGE_FOLDER)
print(results.files)#hide_output
show_boxes("https://ultralytics.com/images/zidane.jpg")Saved 1 image to /home/matthew/Programming/Blog/blog/_notebooks/media/2021-10-20-yolo-clip-open-images['zidane.jpg']
This is a messy room with children in it. The most noticeable omission is the two other chairs by the table, and the incorrect person annotation in the top right. Quite a lot of the items in the image are missing annotations even though they are clear and in focus.
#hide_output
show_boxes("https://i.huffpost.com/gen/2623684/images/o-KIDS-MESSY-HOUSE-facebook.jpg")Saved 1 image to /home/matthew/Programming/Blog/blog/_notebooks/media/2021-10-20-yolo-clip-open-images['o-KIDS-MESSY-HOUSE-facebook.jpg']
This all shows that the yolo model is reasonably good at spotting things, even though this is the smallest model available. It also incorporates object classification. I’m hoping to remove the existing classifier and use a different one though as that should give me more flexibility. I believe the existing classifier is a resnet model.
I think that the model is split into two parts - the first being the bounding box detector, the second being the image classifier. If I can split this and just get the bounding boxes then it should be possible to replace the detector with CLIP.
After looking at the model quite a bit it seems that this is quite difficult. Unfortunately the source code for the different parts of the model are not very clear and the work of the model is split between the AutoModel wrapper and the underlying model.
Having worked with YOLO before the use of the underlying model has always been quite hard. This is because the output is every single possible bounding box. The way that YOLO works is as follows:
You can see this in the following picture:
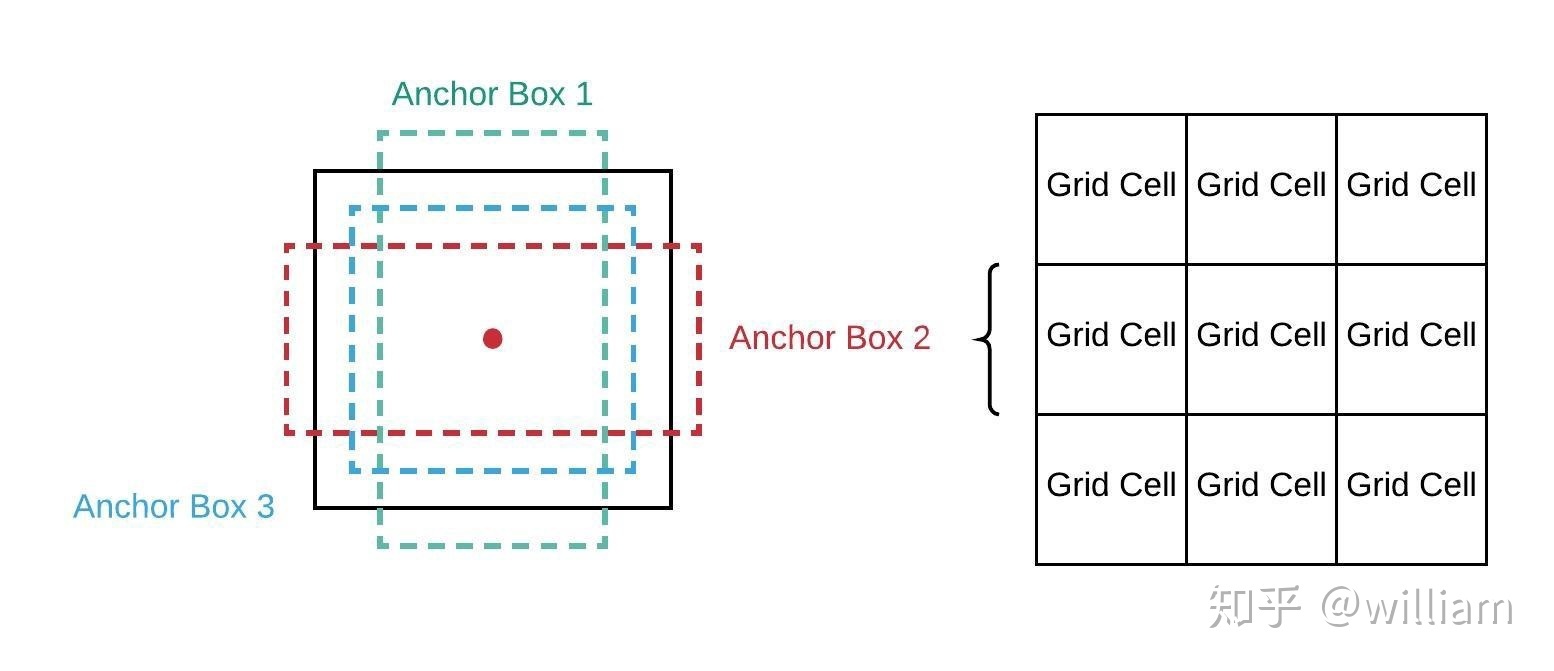 (source - in Chinese? I can’t read it, it has quite a few more pictures of the process)
(source - in Chinese? I can’t read it, it has quite a few more pictures of the process)
As the model adjust the bounds of each of these boxes it also produces a confidence level for the box. The most confident box of the grid cell is taken, and if the confidence is great enough then it is considered to be a detection. This is non max suppression and I have not completely or correctly described it here. I remember it being quite involved to implement myself, and you can see the yolo v5 implementation here.
Anyway given how hard it is to work with effectively I’m actually fine with just running the model and then running the nicely computed output through subsequent classification steps. It would be nice to verify that all of the detections are being returned even if the classification model is unable to produce anything for them. Still, let’s get on with it.
I recently downloaded a chunk of the open images dataset, including the labels. That should allow me to test this all out.
While I have the direct labels and bounding boxes for this, lets just start by loading an image and seeing the possible labels that it could have.
import pandas as pd
openimages_labels = (
pd.read_csv("/data/openimages/external/label_names.csv")
.rename(columns={"LabelName": "id", "DisplayName": "name"})
.set_index("id")
)
openimages_labels| name | |
|---|---|
| id | |
| /m/0100nhbf | Sprenger's tulip |
| /m/0104x9kv | Vinegret |
| /m/0105jzwx | Dabu-dabu |
| /m/0105ld7g | Pistachio ice cream |
| /m/0105lxy5 | Woku |
| ... | ... |
| /m/0zrpfhj | Throwing |
| /m/0zrrls2 | Red dahlia |
| /m/0zrthkd | Brine (Food) |
| /m/0zrv5th | Lamborghini huracán |
| /m/0zvk5 | Helmet |
19994 rows × 1 columns
Now I’m working with the bounding box labels so I want to be able to cut this list of labels down to just bounding box labels.
import pandas as pd
bounding_boxes = pd.read_csv("/data/openimages/external/train_bounding_boxes.csv")
bounding_boxes| ImageID | Source | LabelName | Confidence | XMin | ... | XClick4X | XClick1Y | XClick2Y | XClick3Y | XClick4Y | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 000002b66c9c498e | xclick | /m/01g317 | 1 | 0.012500 | ... | 0.195312 | 0.148438 | 0.357812 | 0.587500 | 0.325000 |
| 1 | 000002b66c9c498e | xclick | /m/01g317 | 1 | 0.025000 | ... | 0.214062 | 0.914062 | 0.714063 | 0.782813 | 0.948438 |
| 2 | 000002b66c9c498e | xclick | /m/01g317 | 1 | 0.151562 | ... | 0.262500 | 0.198437 | 0.434375 | 0.507812 | 0.590625 |
| 3 | 000002b66c9c498e | xclick | /m/01g317 | 1 | 0.256250 | ... | 0.423438 | 0.651563 | 0.921875 | 0.826562 | 0.925000 |
| 4 | 000002b66c9c498e | xclick | /m/01g317 | 1 | 0.257812 | ... | 0.307812 | 0.235938 | 0.289062 | 0.348438 | 0.385938 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 14610224 | fffffdaec951185d | xclick | /m/0dzct | 1 | 0.445625 | ... | 0.672500 | 0.154784 | 0.168856 | 0.200750 | 0.176360 |
| 14610225 | fffffdaec951185d | xclick | /m/0dzct | 1 | 0.695625 | ... | 0.786250 | 0.118199 | 0.297373 | 0.233583 | 0.207317 |
| 14610226 | fffffdaec951185d | xclick | /m/0dzct | 1 | 0.788750 | ... | 0.835000 | 0.198874 | 0.272045 | 0.245779 | 0.247655 |
| 14610227 | fffffdaec951185d | xclick | /m/0dzct | 1 | 0.796875 | ... | 0.942500 | 0.156660 | 0.176360 | 0.189493 | 0.205441 |
| 14610228 | fffffdaec951185d | xclick | /m/0dzct | 1 | 0.991250 | ... | 0.999375 | 0.174484 | 0.185741 | 0.195122 | 0.181989 |
14610229 rows × 21 columns
14 million bounding boxes is pretty cool.
bounding_box_labels = openimages_labels.loc[bounding_boxes.LabelName.unique()]
bounding_box_labels| name | |
|---|---|
| id | |
| /m/01g317 | Person |
| /m/0284d | Dairy Product |
| /m/04bcr3 | Table |
| /m/0fszt | Cake |
| /m/0hnyx | Pastry |
| ... | ... |
| /m/0440zs | Cocktail shaker |
| /m/02mqfb | Can opener |
| /m/05w9t9 | Hair spray |
| /m/0h8ntjv | Pressure cooker |
| /m/080n7g | Paper cutter |
599 rows × 1 columns
Now that I have this we can write a simple wrapper to get the bounding boxes for an image.
# from src/main/python/blog/bounding_boxes/yolo_boxes.py
from typing import List, Tuple, Union
import torch
from PIL import Image
XYXY = Tuple[float, float, float, float]
Boxes = List[XYXY]
class YoloBoxes:
def __init__(self, model: str = "yolov5s", device: str = "cuda") -> None:
self.model = torch.hub.load("ultralytics/yolov5", model, pretrained=True)
self.model = self.model.to(device)
self.model = self.model.eval()
@torch.no_grad()
def __call__(self, image: Union[Image.Image, str]) -> Tuple[Image.Image, Boxes]:
results = self.model([image])
image = Image.fromarray(results.imgs[0])
return image, results.xyxy[0][:, :4].tolist()yolo_boxer = YoloBoxes()Using cache found in /home/matthew/.cache/torch/hub/ultralytics_yolov5_master
YOLOv5 🚀 2021-10-20 torch 1.8.1+cu102 CUDA:0 (NVIDIA TITAN RTX, 24220.3125MB)
Fusing layers...
Model Summary: 213 layers, 7225885 parameters, 0 gradients
Adding AutoShape... image, xyxy = yolo_boxer("https://ultralytics.com/images/zidane.jpg")
xyxy[[752.0, 46.0, 1148.0, 716.0],
[100.0, 201.5, 1002.0, 718.5],
[438.5, 422.0, 510.0, 720.0]]This is the same image as earlier, so these three boxes are the two people and one tie.
Now we want something to crop the images up and pass them to CLIP for labelling.
# from src/main/python/blog/bounding_boxes/crop_images.py
from typing import List, Tuple
from PIL import Image
XYXY = Tuple[float, float, float, float]
Boxes = List[XYXY]
def crop_images(image: Image.Image, xyxys: Boxes) -> List[Image.Image]:
return [image.crop(xyxy) for xyxy in xyxys]
# from src/main/python/blog/bounding_boxes/clip_labels.py
from typing import Dict, List
import clip
import torch
from PIL import Image
Labels = Dict[str, float]
class ClipLabels:
def __init__(self, model: str = "ViT-B/32", device: str = "cuda") -> None:
self.model, self.preprocess = clip.load(model, device=device)
self.device = device
@torch.no_grad()
def __call__(self, images: List[Image.Image], labels: List[str]) -> List[Labels]:
label_tokens = clip.tokenize(labels).to(self.device)
# encoded_text = clip_model.encode_text(label_tokens)
return [self._detect(image, labels, label_tokens) for image in images]
def _detect(
self, image: Image.Image, labels: List[str], label_embeddings: torch.Tensor
) -> Labels:
image_embedding = self.preprocess(image).unsqueeze(0).to(self.device)
# encoded_image = clip_model.encode_image(image_embedding)
logits_per_image, logits_per_text = self.model(
image_embedding, label_embeddings
)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
return dict(zip(labels, probs[0]))clip_labels = ClipLabels()Let’s try it out. I have the open images dataset and I know that the first image in the dataset has bounding boxes with the labels Person, Dairy Product, Table, Cake and Pastry. We can see what labels we get.
Since this gets quite a lot of bounding boxes I am going to show the most confident and least confident predictions.
from typing import Dict, Tuple
Labels = Dict[str, float]
Label = Tuple[str, float]
def get_probability(label: Label) -> float:
return label[-1]
def top_prediction(labels: Labels) -> Label:
return max(labels.items(), key=get_probability)from PIL import Image
image = Image.open("/data/openimages/external/train_0/000002b66c9c498e.jpg")
image
I’ve seen this image quite a lot as I’ve worked with this dataset before. It’s either a wedding or a birthday. I think it’s quite sweet.
from typing import Tuple, List
from PIL import Image
BoxPrediction = Tuple[Image.Image, str, float]
def get_predictions(image: Image.Image, labels: List[str]) -> List[BoxPrediction]:
_, xyxys = yolo_boxer(image)
images = crop_images(image, xyxys)
predictions = clip_labels(images, labels)
top_predictions = [
top_prediction(prediction)
for prediction in predictions
]
results = [
(box, label, probability)
for box, (label, probability) in zip(images, top_predictions)
]
return sorted(results, key=get_probability, reverse=True)image_predictions = get_predictions(image, [f"a picture of a {label}" for label in bounding_box_labels.name])
for box, label, probability in image_predictions[:3] + image_predictions[-3:]:
print(f"{label} - {probability * 100:0.3f}%")
display(box)a picture of a Wine glass - 55.078%
a picture of a Tart - 37.036%
a picture of a Whisk - 29.517%
a picture of a Baseball bat - 1.993%
a picture of a Harpsichord - 1.982%
a picture of a Vase - 1.205%
All of the bottom predictions are terrible. That third prediction is a wicker chair though. It might be hard to judge the relative size of that though.
I’ve run this over another busy image if you want to have a look.
#collapse_output
from PIL import Image
image = Image.open("/data/openimages/external/train_0/0000071d71a0a6f6.jpg")
display(image)
image_predictions = get_predictions(image, [f"a picture of a {label}" for label in bounding_box_labels.name])
for box, label, probability in image_predictions[:3] + image_predictions[-3:]:
print(f"{label} - {probability * 100:0.3f}%")
display(box)
a picture of a Microphone - 51.611%
a picture of a Woman - 30.859%
a picture of a Suit - 21.692%
a picture of a Suit - 15.540%
a picture of a Tie - 9.998%
a picture of a Human face - 4.230%
If you just wanted to label the objects in the image how would this compare to using CLIP directly? What are the top predictions for these images without using the bounding boxes?
from typing import Tuple, List
from PIL import Image
import pandas as pd
def pure_clip(image: Image.Image, labels: List[str]) -> Tuple[Image.Image, pd.DataFrame]:
predictions = clip_labels([image], labels)
df = pd.DataFrame([
{"label": label, "probability": probability}
for label, probability in predictions[0].items()
])
df = df.sort_values(by="probability", ascending=False)
return image, dfLet’s start with the nice picture of the party.
image, predictions = pure_clip(
Image.open("/data/openimages/external/train_0/000002b66c9c498e.jpg"),
[f"a picture of a {label}" for label in bounding_box_labels.name]
)
predictions.head(10)| label | probability | |
|---|---|---|
| 369 | a picture of a Limousine | 0.143433 |
| 3 | a picture of a Cake | 0.046570 |
| 463 | a picture of a Billiard table | 0.035706 |
| 164 | a picture of a Dessert | 0.035156 |
| 2 | a picture of a Table | 0.035156 |
| 388 | a picture of a Cake stand | 0.029587 |
| 165 | a picture of a Baked goods | 0.026123 |
| 277 | a picture of a Platter | 0.021988 |
| 50 | a picture of a Food | 0.021317 |
| 176 | a picture of a Serving tray | 0.018814 |
Person isn’t even in the top 10. We can also try the award ceremony.
image, predictions = pure_clip(
Image.open("/data/openimages/external/train_0/0000071d71a0a6f6.jpg"),
[f"a picture of a {label}" for label in bounding_box_labels.name]
)
predictions.head(10)| label | probability | |
|---|---|---|
| 419 | a picture of a Bust | 0.113525 |
| 7 | a picture of a Woman | 0.072205 |
| 21 | a picture of a Tie | 0.060791 |
| 445 | a picture of a Envelope | 0.055328 |
| 476 | a picture of a Stethoscope | 0.038025 |
| 291 | a picture of a Personal care | 0.026550 |
| 16 | a picture of a Man | 0.024170 |
| 573 | a picture of a Fax | 0.017960 |
| 64 | a picture of a Sculpture | 0.017960 |
| 278 | a picture of a Elephant | 0.016357 |
There is a woman, tie and man but no bust or stethoscope. Elephant is pretty amusing.
In the original CLIP paper they had to use quite a number of different prompts to get good results. It may be that this could address problems with both techniques. I feel that CLIP labelling bounding boxes actually works reasonably well compared to it’s overall performance on busy images.