Code
import blog.transformers_loggingI attended a workshop on model distillation (available on youtube here). It was a combination of distillation and compilation to AWS inferentia, and had a heavy AWS element.
I’m going to use this blog post to recreate that workshop locally.
The video from the workshop has been uploaded to youtube and is available here:
youtube: https://www.youtube.com/watch?v=3fulTyMXhWQ
The code that was used for the workshop is available here.
One of the presenters, Lewis Tunstall, wrote a book on nlp with transformers. You can see that at https://transformersbook.com/
My initial notes on the workshop were:
in distillation the student is trained on the task, and is also trained to produce the same class distribution as the teacher (referred to as a knowledge distillation loss parameter). It has a composite loss function where the accuracy of the student on the task is combined with the degree to which the student output matches the teacher.
The large model has likely learned details about the decision boundaries between the different classes. The knowledge distribution loss function provides hints about the boundaries to the student.
The teacher has learned decision boundaries between the different classes. This is the information that the teacher needs to transmit to the student.
The teacher is likely very confident in it’s output, so it may well assign more than 99% of the probability weight to the correct class. To effectively pass the information about the decision boundaries to the student we need to adjust the teacher output to show these boundaries more clearly.
There is a temperature parameter which is a way of spreading the predicted class. The teacher is likely very confident in the prediction, so the student is likely to get little from the addition of the teacher distribution. Spreading the distribution means that the distribution still reflects the teacher, but shows more of the other classes. This means that the student then has to put effort into matching this as well as the actual correct class.
What values of temperature are good?
usually values of T=2-5 are a good starting point, but in practice you can get better models even with larger values like 10-20
having T<1 will tend to put the teacher’s probabilities to be very similar to the ground truth label, so it isn’t very common in my experience (since you don’t gain any new information)
paper suggests that distillation doesn’t work if the teacher and students have different architectures https://arxiv.org/pdf/2010.13382.pdf
Inferentia is a CPU machine that can compile GPU instructions. The compilation does involve some loss of precision. Once the model has been compiled in this way it can run efficiently on the inferentia machines, faster even than on a GPU. It also compresses the model. In the workshop the model changed size to about ~\(\frac{2}{3}\) of the original.
The compilation process involves mapping the model operations to inferentia operations. Some of this compilation is referred to as fusing which is optimizing. In the workshop some 95% of the model operations were fused.
There are GPU operations which have no corresponding inferentia operation. These cannot be run on inferentia.
An inferentia model does not support dynamic sized input. All input needs to be of a fixed size.
import blog.transformers_loggingThe workshop went over the following code which is in the notebook.
from sagemaker.huggingface import HuggingFace
from huggingface_hub import HfFolder
# hyperparameters, which are passed into the training job
hyperparameters={
'teacher_id':'optimum/roberta-large-finetuned-clinc',
'student_id':'nreimers/MiniLMv2-L12-H384-distilled-from-RoBERTa-Large',
'dataset_id':'clinc_oos',
'dataset_config':'plus',
'epochs': 10,
# distillation parameter
'alpha': 0.055199695773231194, # 0.5,
'temparature': 19, # 4
'learning_rate': 1e-4, # 3e-5
# hpo parameter
"run_hpo": False,
"n_trials": 100,
# push to hub config
'push_to_hub': True,
'hub_model_id': 'MiniLMv2-L12-H384-distilled-finetuned-clinc',
'hub_token': HfFolder.get_token()
}
# define Training Job Name
job_name = f'knowledge-distillation'
# create the Estimator
huggingface_estimator = HuggingFace(
entry_point = 'knowledge_distillation.py',
source_dir = './scripts',
instance_type = 'ml.p3.2xlarge',
instance_count = 1,
role = role,
base_job_name = job_name,
transformers_version = '4.17',
pytorch_version = '1.10',
py_version = 'py38',
hyperparameters = hyperparameters,
)ModuleNotFoundError: No module named 'sagemaker'The code is heavily reliant on sagemaker. It also appears to lack anything to do with distillation.
If we review it carefully it really is just a way of triggering a train on another machine. The actual code is referred to here:
entry_point = 'knowledge_distillation.py',
source_dir = './scripts', The knowledge_distillation.py script contains everything needed to perform distillation locally.
It’s also reasonable to think that huggingface has code related to distillation that could be worth a review. While I have enough with the knowledge_distillation.py script, I did also find a very exciting script on transformers about distilling a classifier which seems solid.
Copying from the knowledge_distillation.py script we can see that the training is achieved by overriding the training arguments and trainer. It’s actually quite a simple extension.
# from src/main/python/blog/distillation/trainer.py
import logging
import sys
from pathlib import Path
from typing import Any, Dict, Tuple, Union
import numpy as np
import torch
import torch.nn.functional as F
from datasets import load_dataset, load_metric
from torch import nn
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
DataCollatorWithPadding,
EvalPrediction,
Trainer,
TrainingArguments,
)
def distill(
*,
teacher_id: str,
student_id: str,
dataset_id: str,
dataset_name: str,
output_dir: Path,
epochs: int,
per_device_train_batch_size: int,
per_device_eval_batch_size: int,
fp16: bool,
learning_rate: float,
alpha: float,
temperature: float,
) -> None:
# Set up logging
logging.basicConfig(
level=logging.getLevelName("INFO"),
handlers=[logging.StreamHandler(sys.stdout)],
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s",
)
# init tokenizer
tokenizer = AutoTokenizer.from_pretrained(teacher_id)
student_tokenizer = AutoTokenizer.from_pretrained(student_id)
# sample input
sample = "This is a basic example, with different words to test."
# assert results
assert tokenizer(sample) == student_tokenizer(
sample
), "Tokenizers are not compatible"
# load datasets
dataset = load_dataset(dataset_id, dataset_name)
# process dataset
def process(examples: Dict[str, Any]) -> Dict[str, Any]:
tokenized_inputs = tokenizer(examples["text"], truncation=True, max_length=512)
return tokenized_inputs
tokenized_datasets = dataset.map(process, batched=True)
tokenized_datasets = tokenized_datasets.rename_column("intent", "labels")
# define metrics and metrics function
accuracy_metric = load_metric("accuracy")
def compute_metrics(eval_pred: EvalPrediction) -> Dict[str, float]:
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
acc = accuracy_metric.compute(predictions=predictions, references=labels)
return {
"accuracy": acc["accuracy"],
}
# create label2id, id2label dicts for nice outputs for the model
labels = tokenized_datasets["train"].features["labels"].names
num_labels = len(labels)
id2label = dict(enumerate(labels))
label2id = {label: label_id for label_id, label in id2label.items()}
# define training args
training_args = DistillationTrainingArguments(
output_dir=output_dir,
num_train_epochs=epochs,
per_device_train_batch_size=per_device_train_batch_size,
per_device_eval_batch_size=per_device_eval_batch_size,
fp16=fp16,
learning_rate=learning_rate,
seed=33,
# logging & evaluation strategies
logging_dir=output_dir / "logs",
logging_strategy="epoch", # to get more information to TB
evaluation_strategy="epoch",
save_strategy="epoch",
save_total_limit=2,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
report_to="tensorboard",
# distilation parameters
alpha=alpha,
temperature=temperature,
)
# define data_collator
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
# define teach model
teacher_model = AutoModelForSequenceClassification.from_pretrained(
teacher_id,
num_labels=num_labels,
id2label=id2label,
label2id=label2id,
)
# init method is needed when using hpo
def student_init():
return AutoModelForSequenceClassification.from_pretrained(
student_id, num_labels=num_labels, id2label=id2label, label2id=label2id
)
trainer = DistillationTrainer(
model_init=student_init,
args=training_args,
teacher_model=teacher_model,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
# train model with inital hyperparameters or hyperparameters from the best run
trainer.train()
# Saves the model to s3 uses os.environ["SM_MODEL_DIR"] to make sure checkpointing works
trainer.save_model(output_dir / "best_model")
class DistillationTrainingArguments(TrainingArguments):
def __init__(
self, *args, alpha: float = 0.5, temperature: float = 2.0, **kwargs
) -> None:
super().__init__(*args, **kwargs)
self.alpha = alpha
self.temperature = temperature
class DistillationTrainer(Trainer):
def __init__(
self, *args, teacher_model: AutoModelForSequenceClassification = None, **kwargs
) -> None:
super().__init__(*args, **kwargs)
self.teacher = teacher_model
# place teacher on same device as student
self._move_model_to_device(self.teacher, self.model.device)
self.teacher.eval()
def compute_loss(
self,
model: AutoModelForSequenceClassification,
inputs: Dict[str, Union[torch.Tensor, Any]],
return_outputs: bool = False,
) -> Union[Tuple[torch.Tensor, torch.Tensor], torch.Tensor]:
# compute student output
outputs_student = model(**inputs)
student_loss = outputs_student.loss
# compute teacher output
with torch.no_grad():
outputs_teacher = self.teacher(**inputs)
# assert size
assert outputs_student.logits.size() == outputs_teacher.logits.size()
# Soften probabilities and compute distillation loss
loss_function = nn.KLDivLoss(reduction="batchmean")
loss_logits = (
loss_function(
F.log_softmax(outputs_student.logits / self.args.temperature, dim=-1),
F.softmax(outputs_teacher.logits / self.args.temperature, dim=-1),
)
* (self.args.temperature ** 2)
)
# Return weighted student loss
loss = self.args.alpha * student_loss + (1.0 - self.args.alpha) * loss_logits
return (loss, outputs_student) if return_outputs else lossfrom pathlib import Path
# the parameters here are copied from the settings, above, and from the defaults in the script.
distill(
teacher_id="optimum/roberta-large-finetuned-clinc",
student_id="nreimers/MiniLMv2-L12-H384-distilled-from-RoBERTa-Large",
dataset_id="clinc_oos",
dataset_name="plus",
output_dir=Path("/data/blog/2022-04-13-huggingface-distillation-workshop"),
epochs=10,
per_device_train_batch_size=64,
per_device_eval_batch_size=64,
fp16=True,
# distillation parameter
learning_rate=1e-4,
alpha=0.055199695773231194,
temperature=19,
)2022-04-26 10:09:07,068 - datasets.builder - WARNING - Reusing dataset clinc_oos (/home/matthew/.cache/huggingface/datasets/clinc_oos/plus/1.0.0/abcc41d382f8137f039adc747af44714941e8196e845dfbdd8ae7a7e020e6ba1)
2022-04-26 10:09:07,086 - datasets.arrow_dataset - WARNING - Loading cached processed dataset at /home/matthew/.cache/huggingface/datasets/clinc_oos/plus/1.0.0/abcc41d382f8137f039adc747af44714941e8196e845dfbdd8ae7a7e020e6ba1/cache-87263ad3bb40db18.arrow
2022-04-26 10:09:07,102 - datasets.arrow_dataset - WARNING - Loading cached processed dataset at /home/matthew/.cache/huggingface/datasets/clinc_oos/plus/1.0.0/abcc41d382f8137f039adc747af44714941e8196e845dfbdd8ae7a7e020e6ba1/cache-16acf3948860a75f.arrow| Epoch | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| 1 | 0.827000 | 0.704925 | 0.376129 |
| 2 | 0.612300 | 0.492485 | 0.799355 |
| 3 | 0.431400 | 0.348086 | 0.893548 |
| 4 | 0.308900 | 0.254955 | 0.938065 |
| 5 | 0.233900 | 0.202458 | 0.945161 |
| 6 | 0.188300 | 0.170242 | 0.947097 |
| 7 | 0.160000 | 0.150101 | 0.948710 |
| 8 | 0.141900 | 0.136279 | 0.950000 |
| 9 | 0.130800 | 0.128748 | 0.952581 |
| 10 | 0.125000 | 0.126360 | 0.950323 |
The settings from the workshop have achieved an accuracy of 95.2%. This compares very well to the teacher accuracy of 97%.
What is interesting is that I have run this training with a few other settings. When the fp16 setting was not used then the student model failed to train at all. This might be worth further investigation.
The workshop described the temperature parameter as smoothing the output of the teacher model. This is because the teacher can be very confident in it’s prediction, which means that there is little additional information for the student compared to just training against the gold label.
The teacher is there to show where suitable decision boundaries are to be found, so the teacher shows the other classes which are close to the target class. By smoothing the probabilities it should increase the probabilies of the classes other than the target.
Let’s see how that looks in practice.
We are going to load the teacher, get it’s output for an example from the test set (available here), and then see how changing the temperature changes that output.
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from datasets import load_dataset
tokenizer = AutoTokenizer.from_pretrained("optimum/roberta-large-finetuned-clinc")
model = AutoModelForSequenceClassification.from_pretrained("optimum/roberta-large-finetuned-clinc")
model.eval()
model.cuda()
dataset = load_dataset("clinc_oos", "plus")
id2label = dict(enumerate(dataset["train"].features["intent"].names))Reusing dataset clinc_oos (/home/matthew/.cache/huggingface/datasets/clinc_oos/plus/1.0.0/abcc41d382f8137f039adc747af44714941e8196e845dfbdd8ae7a7e020e6ba1)import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import pandas as pd
def top_and_bottom(
text: str,
tokenizer: AutoTokenizer,
model: AutoModelForSequenceClassification,
temperature: float,
) -> pd.DataFrame:
logits = get_logits(
text,
tokenizer=tokenizer,
model=model
)[0]
logits = logits / temperature
logits = logits.softmax(dim=-1)
logit_indices = logits.argsort(descending=True)[:10].tolist()
top_5_labels = [
id2label[label_id]
for label_id in logit_indices[:5]
]
bottom_4_labels = [
id2label[label_id]
for label_id in logit_indices[-4:]
]
df = pd.DataFrame(
{
"label": top_5_labels + ["..."] + bottom_4_labels,
"probability": (
logits[logit_indices[:5]].tolist()
+ [0.]
+ logits[logit_indices[-4:]].tolist()
),
}
)
return df
@torch.no_grad()
def get_logits(
text: str,
tokenizer: AutoTokenizer,
model: AutoModelForSequenceClassification
) -> torch.Tensor:
tokens = tokenizer(text, return_tensors="pt")
tokens = tokens.to(model.device)
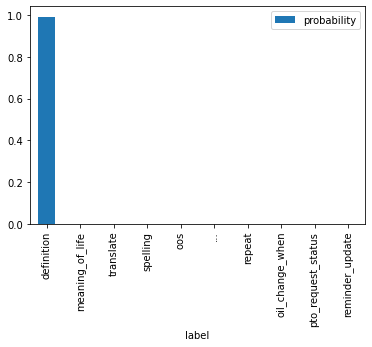
return model(**tokens).logitsHere we can see that 99% of the probability has been assigned to the correct class, definition.
import pandas as pd
df = top_and_bottom(
"what is the definiton of auspicious",
tokenizer=tokenizer,
model=model,
temperature=1,
)
df.plot(x="label", y="probability", kind="bar")
df.iloc[[0,1,9]]| label | probability | |
|---|---|---|
| 0 | definition | 0.991237 |
| 1 | meaning_of_life | 0.000330 |
| 9 | reminder_update | 0.000106 |
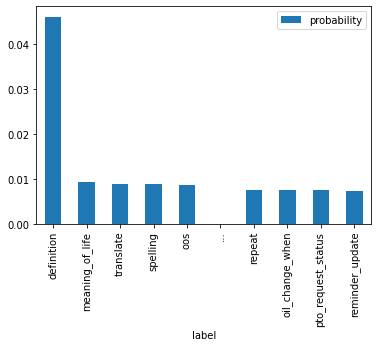
A temperature of 5 was suggested as a good starting point for distillation. Now the most confident label only has ~5% of the probability.
import pandas as pd
df = top_and_bottom(
"what is the definiton of auspicious",
tokenizer=tokenizer,
model=model,
temperature=5,
)
df.plot(x="label", y="probability", kind="bar")
df.iloc[[0,1,9]]| label | probability | |
|---|---|---|
| 0 | definition | 0.046073 |
| 1 | meaning_of_life | 0.009290 |
| 9 | reminder_update | 0.007396 |
A temperature of 19 was used in the workshop. Now the most confident label only has ~1% of the probability, and the second label is ~70% of the most confident.
import pandas as pd
df = top_and_bottom(
"what is the definiton of auspicious",
tokenizer=tokenizer,
model=model,
temperature=19,
)
df.plot(x="label", y="probability", kind="bar")
df.iloc[[0,1,9]]| label | probability | |
|---|---|---|
| 0 | definition | 0.011118 |
| 1 | meaning_of_life | 0.007295 |
| 9 | reminder_update | 0.006870 |
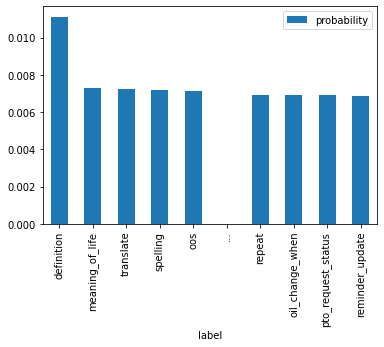
The original model is so confident that the difference between the second best prediction and the worst prediction is not that great.
There are two ways in which I would be interested in taking this new technique. The first is to consider if temperature is the best way to transmit the boundary information. The second is to consider if the KL Divergence approach could be used to internalize prompted tasks into a student.
As we saw earlier the temperature parameter tends to just boost all of the non-correct answers.
I wonder what it would be like to feed in something that is not intententful. At a temperature of 19 the difference between the first wrong answer and the last wrong answer is only ~6% (0.007295 vs 0.006870). How much information is the model gaining from such a low relative difference?
The example we investigated was a clear cut answer. If we try an input where the teacher is uncertain how does temperature affect that?
import pandas as pd
df = top_and_bottom(
"Call me Ishmael. "
"Some years ago, never mind how long precisely, "
"having little or no money in my purse, "
"and nothing particular to interest me on shore, "
"I thought I would sail about a little and see the watery part of the world",
tokenizer=tokenizer,
model=model,
temperature=1,
)
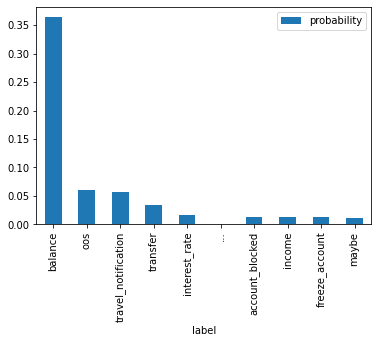
df.plot(x="label", y="probability", kind="bar")
df.iloc[[0,1,9]]| label | probability | |
|---|---|---|
| 0 | balance | 0.363756 |
| 1 | oos | 0.059927 |
| 9 | maybe | 0.010566 |
import pandas as pd
df = top_and_bottom(
"Call me Ishmael. "
"Some years ago, never mind how long precisely, "
"having little or no money in my purse, "
"and nothing particular to interest me on shore, "
"I thought I would sail about a little and see the watery part of the world",
tokenizer=tokenizer,
model=model,
temperature=19,
)
df.plot(x="label", y="probability", kind="bar")
df.iloc[[0,1,9]]| label | probability | |
|---|---|---|
| 0 | balance | 0.008549 |
| 1 | oos | 0.007775 |
| 9 | maybe | 0.007096 |
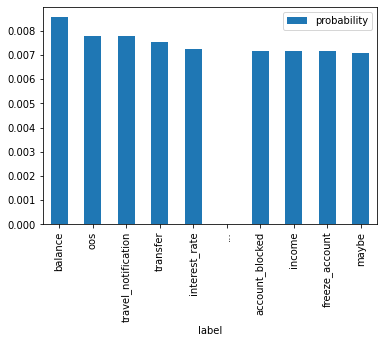
This is a poorly classified sequence and the original output is uncertain. After applying temperature all of the probabilities have been boosted, so the relative difference has been lost. You can see here that the difference between the second class and the last class has largely vanished. The uncertain answer retains more of this difference, but the difference has still become small.
| text | temperature | absolute second score | absolute last score | relative difference % |
|---|---|---|---|---|
| what is … | 1 | 0.000330 | 0.000106 | 211.3 |
| what is … | 5 | 0.009290 | 0.007396 | 25.6 |
| what is … | 19 | 0.007295 | 0.006870 | 6.1 |
| Call me … | 1 | 0.059927 | 0.010566 | 467.1 |
| Call me … | 19 | 0.007775 | 0.007096 | 9.5 |
Two things occur to me based on this.
The first is that the student is being informed of the correct answer already, so the loss of information about the correct class is acceptable, as that information is available through the other loss function.
The second is that this is intended to show the student appropriate decision boundaries. Does such a flat probability distribution do this well? I wonder if a more discriminitive process would be better for transmitting the boundary information.
KL Divergence is matching the distribution of the output of the two models. This could be used to alter a model to internalize the prompt.
The aim would be to have a token sensitive prompt (e.g. the sentiment of an utterance towards a specific mentioned entity) where the teacher output is interpreted according to that specific token. Then the student is evaluated on the raw output of the model for that specific token. This would train the student to predict entity sentiment for each token, allowing entity sentiment to be predicted for every entity in the utterance in one pass.
This would be an extension of my previous work in this area. I will call it prompt internalization.