Code
import blog.transformers_loggingI’ve looked into prompt training before. It’s a neat way to get a general purpose language model to perform a specific task by adding a special prompt to the input and then inspecting certain tokens in the output.
import blog.transformers_loggingWe might make a sentiment classifier by adding the prompt I feel after some text and then using the good and bad tokens to see if it is positive or negative:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("gpt2") # eos_token_id
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained("gpt2")
model.eval() ; None
good_token = tokenizer.vocab["good"] # 11274
bad_token = tokenizer.vocab["bad"] # 14774Could not locate the tokenizer configuration file, will try to use the model config instead.text = "My friend was mean to me. I feel"
with torch.no_grad():
output = model(**tokenizer(text, return_tensors="pt"))
logits = output.logits[0, -1, [good_token, bad_token]].softmax(dim=0)
dict(zip(["good", "bad"], logits.tolist())){'good': 0.3731224536895752, 'bad': 0.6268775463104248}text = "I won the competition today! I feel"
with torch.no_grad():
output = model(**tokenizer(text, return_tensors="pt"))
logits = output.logits[0, -1, [good_token, bad_token]].softmax(dim=0)
dict(zip(["good", "bad"], logits.tolist())){'good': 0.961336076259613, 'bad': 0.03866392746567726}This works reasonably well, and we can even train the prompt as if it were a part of the model to increase the accuracy.
The benefit of doing this is the ability to use different prompts for different tasks. Having to prompt every time is inconvenient though as we have to perform inference over the prompt in addition to the input, and if we want per-token output we may have to run inference many times.
We can try to produce a per-token classifier by training a “student” model from the prompted “teacher”.
Before we train any student we need data to work with. I already have a copy of the sentiment140 [@go2009twitter] dataset to work with. Preparing this just involves tokenizing it and mapping the sentiment column to the target token id.
import pandas as pd
sentiment_df = pd.read_parquet("/data/sentiment/sentiment140/sentiment.gz.parquet")
sentiment_df| sentiment | text | |
|---|---|---|
| 0 | negative | @switchfoot http://twitpic.com/2y1zl - Awww, t... |
| 1 | negative | is upset that he can't update his Facebook by ... |
| 2 | negative | @Kenichan I dived many times for the ball. Man... |
| 3 | negative | my whole body feels itchy and like its on fire |
| 4 | negative | @nationwideclass no, it's not behaving at all.... |
| ... | ... | ... |
| 1599995 | positive | Just woke up. Having no school is the best fee... |
| 1599996 | positive | TheWDB.com - Very cool to hear old Walt interv... |
| 1599997 | positive | Are you ready for your MoJo Makeover? Ask me f... |
| 1599998 | positive | Happy 38th Birthday to my boo of alll time!!! ... |
| 1599999 | positive | happy #charitytuesday @theNSPCC @SparksCharity... |
1600000 rows × 2 columns
from typing import Any, Dict, List
import datasets
def process(row: Dict[str, Any]) -> Dict[str, List[int]]:
label = good_token if row["sentiment"] == "positive" else bad_token
return {
**tokenizer(row["text"], truncation=True, max_length=512),
"labels": label
}
sentiment_ds = datasets.Dataset.from_pandas(sentiment_df)
sentiment_ds = sentiment_ds.map(process)
sentiment_ds.save_to_disk("/data/blog/2022-04-25-prompt-internalization/sentiment.dataset")I need to add the prompt at the end of each utterance. The problem is that the batch of utterances will have different lengths, so I need to add the prompt to the correct place in each utterance. This is just a quick investigation of how to do that.
The first thing is to check if the GPT2 tokenizer adds any special tokens.
import datasets
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2") # eos_token_id
tokenizer.pad_token = tokenizer.eos_token
sentiment_ds = datasets.load_from_disk("/data/blog/2022-04-25-prompt-internalization/sentiment.dataset")tokenizer.decode(sentiment_ds[0]["input_ids"])"@switchfoot http://twitpic.com/2y1zl - Awww, that's a bummer. You shoulda got David Carr of Third Day to do it. ;D"tokenizer.decode(sentiment_ds[0]["input_ids"][-1])'D'It looks like there are no special tokens that are added by default.
The next thing to figure out is a general torch thing. What I need to do is to add the token prompt onto the end of each row. It can’t just be right at the end because a batch is formed out of different length sequences. If the prompt is added at the very end then there will be a lot of unattended tokens inbetween.
To show this let’s have a look at some of the data.
import torch
rows = sentiment_ds[:5]["input_ids"]
max_length = max(len(row) for row in rows)
input_ids = torch.tensor(
[
row + [0]*(max_length - len(row))
for row in rows
],
dtype=torch.long
)
attention = torch.tensor(
[
row + [0]*(max_length - len(row))
for row in sentiment_ds[:5]["attention_mask"]
],
dtype=torch.long
)
# show the last few tokens for the batch
input_ids[:, -10:]tensor([[20765, 286, 10467, 3596, 284, 466, 340, 13, 2162, 35],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 13, 220, 0, 0, 0, 0, 0, 0, 0, 0]])If I want to add the I feel tokens to this, I need to extend the tensor and then write the tokens to the end.
prompt = tokenizer(" I feel", return_tensors="pt").input_ids[0]
prompttensor([ 314, 1254])extended_input_ids = torch.cat(
[
input_ids,
torch.zeros(
input_ids.shape[0],
prompt.shape[0],
dtype=torch.long
)
],
dim=1
)
extended_input_ids[:, -10:]tensor([[10467, 3596, 284, 466, 340, 13, 2162, 35, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])To write the tokens to the end I’ve found it’s easiest to flatten out the tensor and then index it. Indexing multiple points in a n-d tensor is tricky to do correctly. If it’s flat then I can just use a list of indices to identify the correct places to alter.
The prompt needs to be written to the positions following the attended tokens. This can be easily calculated by summing the attention, as that is the count of attended tokens.
batch_size, row_size = extended_input_ids.shape
prompt_size = prompt.shape[0]
end_indices = attention.sum(dim=1)
indices = torch.tensor([
row*row_size + index + offset
for row, offset in zip(range(batch_size), end_indices)
for index in range(prompt_size)
])
indicestensor([ 41, 42, 70, 71, 112, 113, 141, 142, 205, 206])With this it’s now possible to write the prompt to the end of each input.
extended_input_ids.flatten()[indices] = prompt.repeat(5)
tokenizer.batch_decode(extended_input_ids)["@switchfoot http://twitpic.com/2y1zl - Awww, that's a bummer. You shoulda got David Carr of Third Day to do it. ;D I feel",
"is upset that he can't update his Facebook by texting it... and might cry as a result School today also. Blah! I feel!!!!!!!!!!!!!!",
'@Kenichan I dived many times for the ball. Managed to save 50% The rest go out of bounds I feel!!!!!!!!!!!!!!!',
'my whole body feels itchy and like its on fire I feel!!!!!!!!!!!!!!!!!!!!!!!!!!!!!',
"@nationwideclass no, it's not behaving at all. i'm mad. why am i here? because I can't see you all over there. I feel!!!!!!!!"]It looks like the padding token has become an exclamation mark. Otherwise this looks fine.
The flattening of the tensor just reshapes how you index it, the underlying data does not change. So if you start writing to it, you also write to the original tensor. This makes it quite easy to add the prompt at the appropriate place.
This adapts the distillation trainer code from before to use it to compare the student output to the prompted teacher output.
from pathlib import Path
RUN_DIRECTORY = Path("/data/blog/2022-04-25-prompt-internalization/runs")
RUN_DIRECTORY.mkdir(parents=True, exist_ok=True)
BATCH_SIZE = 16 # 64
LEARNING_RATE = 1e-4
ALPHA = 0.5
TEMPERATURE = 2
# EPOCHS = 1
MAX_STEPS = 5_000
EVALUATION_STEPS = 500
GOOD_TOKEN = 11274 # tokenizer.vocab["good"]
BAD_TOKEN = 14774 # tokenizer.vocab["bad"]Loading cached split indices for dataset at /data/blog/2022-04-25-prompt-internalization/sentiment.dataset/cache-eddfd78295c274f6.arrow and /data/blog/2022-04-25-prompt-internalization/sentiment.dataset/cache-c708e874f443409f.arrow# from src/main/python/blog/prompt_internalization/gpt2/trainer.py
from typing import Any, Dict, Tuple, Union
import torch
import torch.nn.functional as F
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
from transformers.modeling_outputs import CausalLMOutputWithCrossAttentions
class CausalPromptInternalizationTrainingArguments(TrainingArguments):
def __init__(
self, *args, alpha: float = 0.5, temperature: float = 2.0, **kwargs
) -> None:
super().__init__(*args, **kwargs)
self.alpha = alpha
self.temperature = temperature
class CausalPromptInternalizationTrainer(Trainer):
def __init__(
self,
*args,
teacher_model: AutoModelForCausalLM = None,
prompt: str = " I feel",
tokenizer: AutoTokenizer = None,
**kwargs,
) -> None:
super().__init__(*args, **kwargs)
self.teacher = teacher_model
self._move_model_to_device(self.teacher, self.model.device)
self.teacher.eval()
# no special tokens are handled by this
prompt = tokenizer(prompt, return_tensors="pt").input_ids[0]
self.prompt = prompt.to(self.model.device)
self.prompt_size = prompt.shape[0]
self.prompt_indices = torch.tensor(
range(self.prompt_size), device=self.model.device
)
def compute_loss(
self,
model: AutoModelForCausalLM,
inputs: Dict[str, Union[torch.Tensor, Any]],
return_outputs: bool = False,
) -> Union[Tuple[torch.Tensor, torch.Tensor], torch.Tensor]:
outputs_student = model(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"]
)
logits_student = self.student_logits(
outputs=outputs_student, attention_mask=inputs["attention_mask"]
)
loss_student = self.student_loss(logits=logits_student, labels=inputs["labels"])
logits_teacher = self.teacher_logits(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"]
)
loss_teacher = self.teacher_loss(
logits_student=logits_student, logits_teacher=logits_teacher
)
# Return weighted student loss
loss = self.args.alpha * loss_student + (1.0 - self.args.alpha) * loss_teacher
return (loss, outputs_student) if return_outputs else loss
@staticmethod
def student_logits(
outputs: CausalLMOutputWithCrossAttentions,
attention_mask: torch.Tensor,
) -> torch.Tensor:
# can't just get the last token, as that might be unattended
# need to get the index to attend to from the attention mask
batch_size = attention_mask.shape[0]
last_logit_index = attention_mask.sum(dim=1)
return outputs.logits[range(batch_size), last_logit_index - 1, :]
@staticmethod
def student_loss(logits: torch.Tensor, labels: torch.Tensor) -> torch.Tensor:
return F.cross_entropy(logits, labels)
@torch.no_grad()
def teacher_logits(
self, input_ids: torch.Tensor, attention_mask: torch.Tensor
) -> torch.Tensor:
batch_size = input_ids.shape[0]
last_logit_index = attention_mask.sum(dim=1)
# have to extend the size as the longest input will fill the current shape
extension = torch.zeros(
batch_size,
self.prompt_size,
dtype=torch.long,
device=input_ids.device,
)
input_ids = torch.cat([input_ids, extension], dim=1)
attention_mask = torch.cat([attention_mask, extension], dim=1)
input_size = input_ids.shape[1]
# now we can add the prompt to the end of each input, and make those tokens attended
indices = [
row * input_size + index
for row in range(batch_size)
for index in self.prompt_indices + last_logit_index[row]
]
input_ids.flatten()[indices] = self.prompt.repeat(batch_size)
attention_mask.flatten()[indices] = 1
# then we get the prompted logits from the teacher for the final token after the prompt
outputs = self.teacher(input_ids=input_ids, attention_mask=attention_mask)
return outputs.logits[range(batch_size), attention_mask.sum(dim=1) - 1, :]
def teacher_loss(
self, logits_student: torch.Tensor, logits_teacher: torch.Tensor
) -> torch.Tensor:
# Soften probabilities and compute distillation loss
kl_loss = F.kl_div(
input=F.log_softmax(logits_student / self.args.temperature, dim=-1),
target=F.softmax(logits_teacher / self.args.temperature, dim=-1),
reduction="batchmean",
log_target=False,
)
return kl_loss * (self.args.temperature ** 2)Computing the metrics is slightly complicated as the full model output for the entire sequence is recorded. This includes the padding so to find the prediction we need to get the index of the last attended token for each row in the validation set. Luckily the validation is not shuffled.
# from src/main/python/blog/prompt_internalization/gpt2/metrics.py
from typing import Dict
import datasets
import numpy as np
from transformers import EvalPrediction
class CausalAccuracyMetric:
def __init__(self, dataset: datasets.Dataset) -> None:
self.indicies = np.array([len(row) - 1 for row in dataset["attention_mask"]])
def __call__(self, eval_pred: EvalPrediction) -> Dict[str, float]:
predictions, labels = eval_pred
predictions = predictions[range(len(self.indicies)), self.indicies]
predictions = predictions.argmax(axis=1)
accuracy = (predictions == labels).mean()
return {"accuracy": accuracy}from transformers import AutoModelForCausalLM, DataCollatorWithPadding
training_args = CausalPromptInternalizationTrainingArguments(
report_to="none",
output_dir=RUN_DIRECTORY,
# num_train_epochs=EPOCHS,
max_steps=MAX_STEPS,
evaluation_strategy="steps",
logging_steps=EVALUATION_STEPS,
eval_steps=EVALUATION_STEPS,
save_steps=EVALUATION_STEPS,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE,
fp16=False,
learning_rate=LEARNING_RATE,
seed=33,
logging_dir=RUN_DIRECTORY / "logs",
save_total_limit=2,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
alpha=ALPHA,
temperature=TEMPERATURE,
)
compute_metrics = CausalAccuracyMetric(validation_ds)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
teacher_model = AutoModelForCausalLM.from_pretrained("gpt2")
student_model = AutoModelForCausalLM.from_pretrained("gpt2")
trainer = CausalPromptInternalizationTrainer(
model=student_model,
args=training_args,
teacher_model=teacher_model,
train_dataset=train_ds,
eval_dataset=validation_ds,
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()| Step | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| 500 | 0.652000 | 0.555368 | 0.734375 |
| 1000 | 0.536600 | 0.498783 | 0.804688 |
| 1500 | 0.503400 | 0.504917 | 0.796875 |
| 2000 | 0.488700 | 0.473174 | 0.835938 |
| 2500 | 0.476600 | 0.488516 | 0.835938 |
| 3000 | 0.467300 | 0.460504 | 0.851562 |
| 3500 | 0.451000 | 0.453815 | 0.843750 |
| 4000 | 0.446000 | 0.447202 | 0.859375 |
| 4500 | 0.443900 | 0.422696 | 0.835938 |
| 5000 | 0.429400 | 0.419842 | 0.859375 |
TrainOutput(global_step=5000, training_loss=0.4895012969970703, metrics={'train_runtime': 566.693, 'train_samples_per_second': 141.17, 'train_steps_per_second': 8.823, 'total_flos': 1683823011840000.0, 'train_loss': 0.4895012969970703, 'epoch': 0.05})student_model.save_pretrained(RUN_DIRECTORY / "best-model")The student trains almost immediately and doesn’t really get better than 0.86 accuracy. Let’s see what that looks like.
I’m just going to look at a few utterances to see how the model assessed sentiment changes.
Could not locate the tokenizer configuration file, will try to use the model config instead.from transformers import AutoModelForCausalLM
import torch
import pandas as pd
@torch.no_grad()
def show_sentiment(text: str, model: AutoModelForCausalLM) -> pd.DataFrame:
tokens = tokenizer(text, return_tensors="pt").input_ids
output = model(tokens)
logits = output.logits[0, :, [GOOD_TOKEN, BAD_TOKEN]].softmax(dim=-1)
df = pd.DataFrame({
"token": tokenizer.batch_decode(tokens[0, :, None]),
"good": logits[:, 0],
"bad": logits[:, 1],
}).set_index("token")
# force all words to be shown
ax = df.plot(figsize=(len(df),4), style={'bad': 'r', 'good': 'g'}, ylim=(0, 1))
ax.set_xticks(range(len(df.index)))
ax.set_xticklabels(df.index)
return dfI’ve got this code to show the good and bad sentiment for each token in turn. Then you can see how the model assessment changes as the sentence progresses.
df = show_sentiment(
text="My friend was mean to me.",
model=student_model,
)
df.tail(n=1)| good | bad | |
|---|---|---|
| token | ||
| . | 0.038568 | 0.961432 |
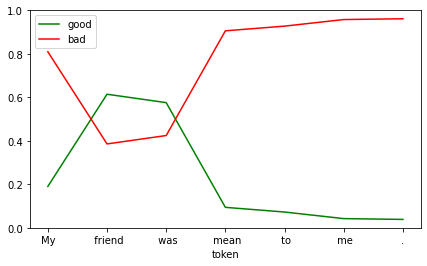
Here it looks like the model starts out with a negative bias and thinks that you will say nice things about your friend.
df = show_sentiment(
text="My friend was so kind the other day.",
model=student_model,
)
df.tail(n=1)| good | bad | |
|---|---|---|
| token | ||
| . | 0.582697 | 0.417303 |
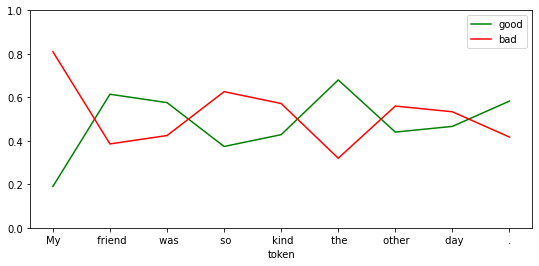
The negative bias is easy to see here, even kind isn’t yet positive. It’s all over the place however it does work out as positive when the end of the sentence is reached.
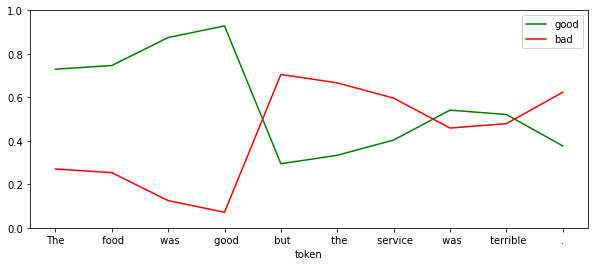
df = show_sentiment(
text="The food was good but the service was terrible.",
model=student_model,
)
df.iloc[[3,-1]]| good | bad | |
|---|---|---|
| token | ||
| good | 0.775578 | 0.224422 |
| . | 0.006431 | 0.993569 |
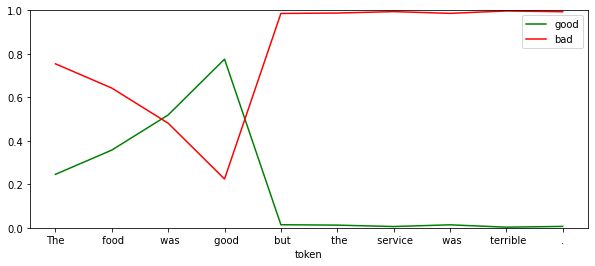
This is really interesting. The utterance mixes two sentiments towards different things (food and service). We can see that the model can assign positive sentiment to the good near food and negative to the service.
This is close to an entity sentiment system. I think this technique could be refined with per entity sentiment to make something even better.
With per word sentiment I would be able to refine this system quite a bit too, as that should allow a bi-directional model.
How does this compare to the same model trained without the teacher input? I actually expect the plain model to perform better as the teacher can get some of the responses wrong in this setup. This technique will be more useful for more complex training.
Here we turn the alpha up to 1 which means that all loss will be calculated against the labels and nothing will come from the teacher. Since this has become a binary classification problem I expect the accuracy to exceed that of the taught model.
training_args = CausalPromptInternalizationTrainingArguments(
report_to="none",
output_dir=RUN_DIRECTORY,
# num_train_epochs=EPOCHS,
max_steps=MAX_STEPS,
evaluation_strategy="steps",
logging_steps=EVALUATION_STEPS,
eval_steps=EVALUATION_STEPS,
save_steps=EVALUATION_STEPS,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE,
fp16=False,
learning_rate=LEARNING_RATE,
seed=33,
logging_dir=RUN_DIRECTORY / "logs",
save_total_limit=2,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
alpha=1, # CHANGED
temperature=2,
)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
teacher_model = AutoModelForCausalLM.from_pretrained("gpt2")
student_model = AutoModelForCausalLM.from_pretrained("gpt2")
trainer = CausalPromptInternalizationTrainer(
model=student_model,
args=training_args,
teacher_model=teacher_model,
train_dataset=train_ds,
eval_dataset=validation_ds,
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()| Step | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| 500 | 0.631900 | 0.363403 | 0.828125 |
| 1000 | 0.481900 | 0.297387 | 0.875000 |
| 1500 | 0.443100 | 0.322583 | 0.859375 |
| 2000 | 0.423800 | 0.310042 | 0.859375 |
| 2500 | 0.411900 | 0.268115 | 0.890625 |
| 3000 | 0.397900 | 0.310476 | 0.859375 |
| 3500 | 0.386000 | 0.259810 | 0.890625 |
| 4000 | 0.386000 | 0.279414 | 0.882812 |
| 4500 | 0.378700 | 0.254981 | 0.898438 |
| 5000 | 0.357900 | 0.245185 | 0.890625 |
TrainOutput(global_step=5000, training_loss=0.4299179443359375, metrics={'train_runtime': 555.8338, 'train_samples_per_second': 143.928, 'train_steps_per_second': 8.995, 'total_flos': 1683823011840000.0, 'train_loss': 0.4299179443359375, 'epoch': 0.05})student_model.save_pretrained(RUN_DIRECTORY / "no-teacher")This gets almost to 0.9 accuracy so quite an improvement over the taught version.
We can review how it predicts each word of the sequence again.
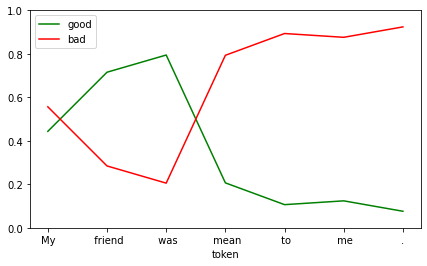
Could not locate the tokenizer configuration file, will try to use the model config instead.df = show_sentiment(
text="My friend was mean to me.",
model=student_model,
)
df.tail(n=1)| good | bad | |
|---|---|---|
| token | ||
| . | 0.076076 | 0.923924 |
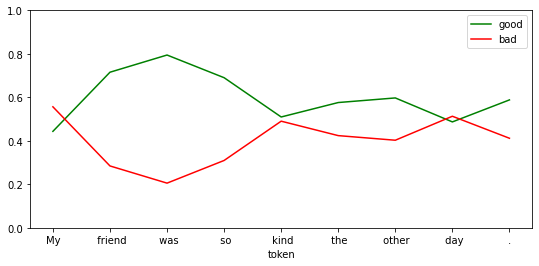
df = show_sentiment(
text="My friend was so kind the other day.",
model=student_model,
)
df.tail(n=1)| good | bad | |
|---|---|---|
| token | ||
| . | 0.588195 | 0.411805 |
df = show_sentiment(
text="The food was good but the service was terrible.",
model=student_model,
)
df.iloc[[3,-1]]| good | bad | |
|---|---|---|
| token | ||
| good | 0.740345 | 0.259655 |
| . | 0.018107 | 0.981893 |
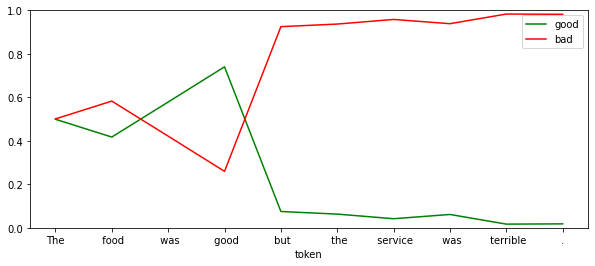
This model seems to be a more extreme version of the original.
Now we turn the alpha parameter down to zero. This means that there is no contribution to the loss from the label. The model will instead learn to mimic the prompted teacher.
The accuracy of this may be very low, and that is because the accuracy assessment is done against all the possible tokens. The student is not being guided to focus on the good and bad tokens so often times neither of those will be the strongest output.
training_args = CausalPromptInternalizationTrainingArguments(
report_to="none",
output_dir=RUN_DIRECTORY,
# num_train_epochs=EPOCHS,
max_steps=MAX_STEPS,
evaluation_strategy="steps",
logging_steps=EVALUATION_STEPS,
eval_steps=EVALUATION_STEPS,
save_steps=EVALUATION_STEPS,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE,
fp16=False,
learning_rate=LEARNING_RATE,
seed=33,
logging_dir=RUN_DIRECTORY / "logs",
save_total_limit=2,
load_best_model_at_end=True,
metric_for_best_model="accuracy",
alpha=0, # CHANGED
temperature=2,
)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
teacher_model = AutoModelForCausalLM.from_pretrained("gpt2")
student_model = AutoModelForCausalLM.from_pretrained("gpt2")
trainer = CausalPromptInternalizationTrainer(
model=student_model,
args=training_args,
teacher_model=teacher_model,
train_dataset=train_ds,
eval_dataset=validation_ds,
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()| Step | Training Loss | Validation Loss | Accuracy |
|---|---|---|---|
| 500 | 0.148400 | 0.082124 | 0.000000 |
| 1000 | 0.084300 | 0.060307 | 0.000000 |
| 1500 | 0.075000 | 0.054029 | 0.000000 |
| 2000 | 0.068700 | 0.050960 | 0.000000 |
| 2500 | 0.063400 | 0.046169 | 0.000000 |
| 3000 | 0.058700 | 0.043454 | 0.000000 |
| 3500 | 0.056800 | 0.040614 | 0.000000 |
| 4000 | 0.054400 | 0.040211 | 0.000000 |
| 4500 | 0.051700 | 0.037695 | 0.000000 |
| 5000 | 0.049700 | 0.036094 | 0.000000 |
TrainOutput(global_step=5000, training_loss=0.07111203346252441, metrics={'train_runtime': 551.3419, 'train_samples_per_second': 145.101, 'train_steps_per_second': 9.069, 'total_flos': 1683823011840000.0, 'train_loss': 0.07111203346252441, 'epoch': 0.05})student_model.save_pretrained(RUN_DIRECTORY / "no-target")We can review how it predicts each word of the sequence again. As this model hasn’t been trained to focus on the “good” and “bad” tokens it may well predict a different token as the best token. So this evaluation will also look at the top prediction for each token.
Could not locate the tokenizer configuration file, will try to use the model config instead.import torch
import pandas as pd
@torch.no_grad()
def show_top_token(text: str, model: AutoModelForCausalLM) -> pd.DataFrame:
tokens = tokenizer(text, return_tensors="pt").input_ids
output = model(tokens)
predicted = output.logits[0].argmax(dim=1)
df = pd.DataFrame({
"token": tokenizer.batch_decode(tokens[0, :, None]),
"predicted": tokenizer.batch_decode(predicted),
}).set_index("token")
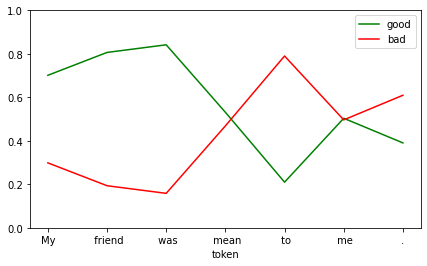
return dfdf = show_sentiment(
text="My friend was mean to me.",
model=student_model,
)
df.tail(n=1)| good | bad | |
|---|---|---|
| token | ||
| . | 0.39043 | 0.60957 |
show_top_token(
text="My friend was mean to me.",
model=student_model,
)| predicted | |
|---|---|
| token | |
| My | like |
| friend | like |
| was | like |
| mean | like |
| to | like |
| me | like |
| . | like |
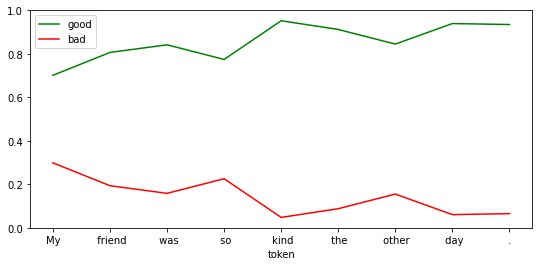
df = show_sentiment(
text="My friend was so kind the other day.",
model=student_model,
)
df.tail(n=1)| good | bad | |
|---|---|---|
| token | ||
| . | 0.934829 | 0.065171 |
show_top_token(
text="My friend was so kind the other day.",
model=student_model,
)| predicted | |
|---|---|
| token | |
| My | like |
| friend | like |
| was | like |
| so | like |
| kind | like |
| the | like |
| other | like |
| day | like |
| . | like |
df = show_sentiment(
text="The food was good but the service was terrible.",
model=student_model,
)
df.iloc[[3,-1]]| good | bad | |
|---|---|---|
| token | ||
| good | 0.928435 | 0.071565 |
| . | 0.376729 | 0.623271 |
show_top_token(
text="The food was good but the service was terrible.",
model=student_model,
)| predicted | |
|---|---|
| token | |
| The | like |
| food | like |
| was | like |
| good | like |
| but | like |
| the | bad |
| service | like |
| was | like |
| terrible | like |
| . | like |
This has reversed the bias, having a good starting opinion of the different utterances.
The top token is certainly illuminating. It does appear that for any sentence the prompt “I feel” has a follow on word of “like”.
It would be good to check if this is the case. We can do this by reviewing the output of the original model for each of these prompted inputs.
Could not locate the tokenizer configuration file, will try to use the model config instead.Does the model always predict like? It should not as the GPT2 model is a well trained language model, and like is not the only word in the English language.
show_top_token(
text="My friend was mean to me.",
model=model,
)| predicted | |
|---|---|
| token | |
| My | \n |
| friend | , |
| was | a |
| mean | to |
| to | me |
| me | , |
| . | I |
We see that the original GPT2 model always predicts like as the following word for the different prompted utterances:
@torch.no_grad()
def top_token(text: str) -> str:
output = model(**tokenizer(text, return_tensors="pt"))
return tokenizer.decode(output.logits[0, -1].argmax())top_token("My friend was mean to me. I feel")' like'top_token("My friend was so kind the other day. I feel")' like'top_token("The food was good but the service was terrible. I feel")' like'The problem here is that I feel is a poor prompt. Teaching the student to replicate the prompted output has worked though - it is always predicting like. Ha.
It would be good to try this out on a more complex task.
To what degree has the model internalized the prompt? We can measure the difference between the internalized model and the original prompted model to find out.
This measures the softmax difference as that is what KL divergence works with.
from typing import Dict
@torch.no_grad()
def output_difference(
text: str,
original_model: AutoModelForCausalLM,
internalized_model: AutoModelForCausalLM,
prompt: str = " I feel",
) -> Dict[str, float]:
prompted_output = original_model(**tokenizer(text + prompt, return_tensors="pt"))
prompted_logits = prompted_output.logits[0, -1].softmax(dim=0)
internalized_output = internalized_model(**tokenizer(text, return_tensors="pt"))
internalized_logits = internalized_output.logits[0, -1].softmax(dim=0)
difference = (prompted_logits - internalized_logits).abs()
return {"max": difference.max(), "mean": difference.mean(), "sum": difference.sum()}output_difference(
text="My friend was mean to me.",
original_model=model,
internalized_model=student_model,
){'max': tensor(0.0351), 'mean': tensor(4.0304e-06), 'sum': tensor(0.2026)}output_difference(
text="My friend was so kind the other day.",
original_model=model,
internalized_model=student_model,
){'max': tensor(0.0733), 'mean': tensor(4.3129e-06), 'sum': tensor(0.2168)}output_difference(
text="The food was good but the service was terrible.",
original_model=model,
internalized_model=student_model,
){'max': tensor(0.0764), 'mean': tensor(5.4345e-06), 'sum': tensor(0.2731)}This difference is still significant, but it has managed to get close with just 5,000 batches of training. We can see how well this has worked by comparing the untrained model to itself.
output_difference(
text="My friend was mean to me.",
original_model=model,
internalized_model=model,
){'max': tensor(0.2901), 'mean': tensor(3.9242e-05), 'sum': tensor(1.9722)}Here we can see how the addition of the prompt wildly changes the outputs. The sum of the absolute differences actually exceeds 1.
In conclusion I think that prompt internalization has worked and I’m keen to try it out on some more complex tasks.