Code
import blog.transformers_loggingWord sense induction is the process of clustering words according to their specific meaning. As an example we can consider the word bass. This can be used in several different ways:
The word is the same but the meaning differs. Word sense induction is the process of clustering such that 1. and 3. are in the same cluster, and 2. is in a different cluster.
This process has been studied before and Word Sense Induction with Neural biLM and Symmetric Patterns {% cite amrami-goldberg-2018-word %} used prompting to extract vectors that could be clustered. Since I’ve investigated prompts before I’m quite keen to try this approach. I’m hopeful that this could be applied to my wikipedia clustering attempt from last year.
import blog.transformers_loggingSince the aim is to internalize a prompt that relates to a word, I’m actually interested in just taking random words from an utterance and then trying to work out the prompted word vector from them. Since the prompt can only refer to the word and not it’s position in the text I need the word to be unique. It would also be good to restrict the word to a noun as that should provide a more interesting vector to cluster. All of this can be done using spacy.
import en_core_web_sm
from spacy.matcher import Matcher
nlp = en_core_web_sm.load()
matcher = Matcher(nlp.vocab)
matcher.add("nouns", [
[{"POS": {"IN": ["NOUN", "PROPN"]}, "OP": "+"}],
])text = "I went back to my house and my cat was there"
doc = nlp(text)
words = matcher(doc, as_spans=True)
words[house, cat]text[words[0].start_char : words[0].end_char]'house'With this we should be able to pull out the tokens associated with the nouns.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("roberta-base")tokens = tokenizer(text, return_offsets_mapping=True)
[
token
for token, offset in zip(tokens.input_ids, tokens.offset_mapping)
if offset == (words[0].start_char, words[0].end_char)
][790]tokenizer.decode(790)' house'A little bit of care is needed to get multi token spans.
text = "The sand castle has shells"
doc = nlp(text)
words = matcher(doc, as_spans=True)
words[sand, sand castle, castle, shells]from itertools import takewhile
start, end = words[1].start_char, words[1].end_char
tokens = tokenizer(text, return_offsets_mapping=True)
[
[
token
for token, _ in takewhile(
lambda pair: pair[1][1] <= end,
zip(tokens.input_ids[index:], tokens.offset_mapping[index:])
)
]
for index, (token_start, _) in enumerate(tokens.offset_mapping)
if token_start == start
][[6255, 22637]]To be able to work with this I need to have the start and end indicies of the tokens for each word of interest. With that I can create the prompt as well as measure the output from the unprompted model.
from typing import List
import en_core_web_sm
from spacy.tokens import Span
from spacy.matcher import Matcher
class NounExtractor:
def __init__(self) -> None:
self.nlp = en_core_web_sm.load()
self.matcher = Matcher(self.nlp.vocab)
self.matcher.add("nouns", [
[{"POS": {"IN": ["NOUN", "PROPN"]}, "OP": "+"}],
])
def get_nouns(self, text: str) -> List[Span]:
doc = self.nlp(text)
nouns = self.matcher(doc, as_spans=True)
return self.unique(text, nouns=nouns)
def unique(self, text: str, nouns: List[Span]) -> List[Span]:
text = text.casefold()
return [
noun
for noun in nouns
if text.count(noun.text.casefold()) == 1
]from typing import Any, Dict, Tuple
from spacy.tokens import Span
from transformers import AutoTokenizer
class Encoder:
def __init__(self, name: str = "roberta-base") -> None:
self.tokenizer = AutoTokenizer.from_pretrained(name)
self.extractor = NounExtractor()
def encode(self, text: str) -> Dict[str, Any]:
nouns = self.extractor.get_nouns(text)
tokens = self.tokenizer(text, truncation=True, return_offsets_mapping=True)
labels = self.find(tokens.offset_mapping, nouns)
return {
"input_ids": tokens.input_ids,
"attention_mask": tokens.attention_mask,
"labels": labels
}
def find(self, offsets: List[Tuple[int, int]], nouns: List[Span]) -> List[Tuple[int, int]]:
starts = {
start: index
for index, (start, end) in enumerate(offsets)
if start != end
}
ends = {
end: index
for index, (start, end) in enumerate(offsets)
if start != end
}
return [
(starts[noun.start_char], 1 + ends[noun.end_char] - starts[noun.start_char])
for noun in nouns
if noun.start_char in starts and noun.end_char in ends
]encoder = Encoder()text = "The sand castle has shells"
encoder.encode(text){'input_ids': [0, 133, 6255, 22637, 34, 23647, 2],
'attention_mask': [1, 1, 1, 1, 1, 1, 1],
'labels': [(2, 1), (2, 2), (3, 1), (5, 1)]}import pandas as pd
sentiment_df = pd.read_parquet("/data/sentiment/sentiment140/sentiment.gz.parquet")
sentiment_df| sentiment | text | |
|---|---|---|
| 0 | negative | @switchfoot http://twitpic.com/2y1zl - Awww, t... |
| 1 | negative | is upset that he can't update his Facebook by ... |
| 2 | negative | @Kenichan I dived many times for the ball. Man... |
| 3 | negative | my whole body feels itchy and like its on fire |
| 4 | negative | @nationwideclass no, it's not behaving at all.... |
| ... | ... | ... |
| 1599995 | positive | Just woke up. Having no school is the best fee... |
| 1599996 | positive | TheWDB.com - Very cool to hear old Walt interv... |
| 1599997 | positive | Are you ready for your MoJo Makeover? Ask me f... |
| 1599998 | positive | Happy 38th Birthday to my boo of alll time!!! ... |
| 1599999 | positive | happy #charitytuesday @theNSPCC @SparksCharity... |
1600000 rows × 2 columns
from tqdm.auto import tqdm
tqdm.pandas()%%time
sentiment_df = pd.read_parquet("/data/sentiment/sentiment140/sentiment.gz.parquet")
sentiment_df = sentiment_df.drop(columns="sentiment")
sentiment_df = sentiment_df.sample(n=100_000)
sentiment_df = sentiment_df.merge(
pd.DataFrame(
sentiment_df.text.apply(encoder.encode).tolist(),
index=sentiment_df.index
),
left_index=True,
right_index=True,
)
sentiment_df = sentiment_df.explode("labels")
sentiment_df = sentiment_df.dropna()CPU times: user 5min 11s, sys: 124 ms, total: 5min 11s
Wall time: 5min 11ssentiment_df.to_parquet("/data/blog/2022-05-02-prompt-internalization-word-sense/tweets.gz.parquet", compression="gzip")import datasets
sentiment_ds = datasets.Dataset.from_pandas(sentiment_df)sentiment_ds.save_to_disk("/data/blog/2022-05-02-prompt-internalization-word-sense/tweets.dataset")sentiment_dsDataset({
features: ['text', 'input_ids', 'attention_mask', 'labels', '__index_level_0__'],
num_rows: 425149
})The next thing is to be able to add the prompt to the end. Roberta adds special characters to the output.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("roberta-base")
tokens = tokenizer("hello").input_ids
{token: tokenizer.decode(token) for token in tokens}{0: '<s>', 42891: 'hello', 2: '</s>'}tokenizer.mask_token_id50264It should be easy enough to add the prompt, I just need to ensure that the prompt doesn’t have the starting special token.
The next thing to do is to come up with a suitable prompt. It would be much easier to work with this if I add a prompt to the end. Since the existing prompt from the paper is trying to elicit an alternative description of the word maybe I can come up with a similar approach.
The roberta model is masked so I can come up with two appropriate forms:
We can try this out with the three examples from before.
from transformers import AutoTokenizer, AutoModelForMaskedLM
import torch
@torch.no_grad()
def get_word_signature(
tokenizer: AutoTokenizer,
model: AutoModelForMaskedLM,
text: str,
word: str,
prompt: str
) -> List[str]:
prompt = prompt.format(word)
text = text.strip()
if not text.endswith("."):
text = text + "."
text = f"{text} {prompt.strip()}"
tokens = tokenizer(text, return_tensors="pt")
tokens = tokens.to(model.device)
mask_index = tokens.input_ids[0] == tokenizer.mask_token_id
output = model(**tokens)
predictions = output.logits[0, mask_index].mean(dim=0)
predicted_tokens = predictions.argsort(descending=True)[:10]
return tokenizer.batch_decode(predicted_tokens[:, None])from transformers import AutoTokenizer, AutoModelForMaskedLM
model = AutoModelForMaskedLM.from_pretrained("roberta-base")
model.eval()
model.cuda()
tokenizer = AutoTokenizer.from_pretrained("roberta-base")The next thing is to work out a good prompt. A good prompt will trigger the model to describe the word. The description is the distribution of the prediction for the masked token. Clustering this description is how we will perform word sense induction.
A good prompt will produce predicted tokens which describe the word well.
<mask> is a WORDFor example, We spotted a large bass in the ocean. The <mask> is a bass. I’m hopeful that this will produce words like fish or creature.
for text in [
"We spotted a large bass in the ocean.",
"The bass player did not receive the acknowledgment she deserves.",
"The black sea bass, is a member of the wreckfish family.",
]:
print(text)
print(get_word_signature(
tokenizer=tokenizer,
model=model,
text=text,
word="bass",
prompt="The <mask> is a {}.",
))
print()We spotted a large bass in the ocean.
[' fish', ' animal', ' photo', ' picture', ' species', ' creature', ' bird', ' shark', ' bass', ' specimen']
The bass player did not receive the acknowledgment she deserves.
[' player', ' woman', ' bass', ' girl', ' singer', ' man', ' culprit', ' song', ' musician', ' guitar']
The black sea bass, is a member of the wreckfish family.
[' fish', ' male', ' female', ' shark', ' adult', ' second', ' other', ' species', ' bottom', ' head']
<mask>For example, We spotted a large bass in the ocean. The bass is a <mask>. Again fish and creature would fit fine here.
for text in [
"We spotted a large bass in the ocean.",
"The bass player did not receive the acknowledgment she deserves.",
"The black sea bass, is a member of the wreckfish family.",
]:
print(text)
print(get_word_signature(
tokenizer=tokenizer,
model=model,
text=text,
word="bass",
prompt="The {} is a <mask>.",
))
print()We spotted a large bass in the ocean.
[' male', ' female', ' juvenile', ' fish', ' dolphin', ' shark', ' salmon', ' rainbow', ' bass', ' sub']
The bass player did not receive the acknowledgment she deserves.
[' legend', ' genius', ' monster', ' bitch', ' joke', ' god', ' hero', ' liability', ' star', ' failure']
The black sea bass, is a member of the wreckfish family.
[' juvenile', ' male', ' female', ' sub', ' hybrid', ' fish', ' species', ' bass', ' rainbow', ' carp']
The first prompt (The <mask> is a bass) seems to work well. The first word of each set of predictions is highly relevant to the different groups (fish for a and c vs player for b).
The second prompt (The bass is a <mask>) appears worse than the first. The predictions for the b sentence seem poorly related to the actual class, seemingly more related to emotive aspects of being a musician. The a and c sentence are also mixed up as they have the same top 3 predictions but in a different order.
There are other prompts that could be used. Coming up with a good prompt is tricky and I am more interested in seeing if the prompt internalization technique works at all.
Now we can work on internalizing the prompt. There isn’t really a metric for training that is better than the loss function. The KL Divergence that forms the loss is a measure of the difference between the prompted teacher and the unprompted student.
from pathlib import Path
RUN_DIRECTORY = Path("/data/blog/2022-05-02-prompt-internalization-word-sense/runs")
RUN_DIRECTORY.mkdir(parents=True, exist_ok=True)
MODEL_NAME = "roberta-base"
BATCH_SIZE = 16 # 64
LEARNING_RATE = 1e-4
TEMPERATURE = 2
EPOCHS = 2
# MAX_STEPS = 5_000
# MAX_STEPS = 50
EVALUATION_STEPS = 1_000
# EVALUATION_STEPS = 10import datasets
tweet_ds = datasets.load_from_disk("/data/blog/2022-05-02-prompt-internalization-word-sense/tweets.dataset")
tweet_split_ds = tweet_ds.train_test_split(test_size=10_000)Loading cached split indices for dataset at /data/blog/2022-05-02-prompt-internalization-word-sense/tweets.dataset/cache-dd3837117c50dc2a.arrow and /data/blog/2022-05-02-prompt-internalization-word-sense/tweets.dataset/cache-41027af85f6371d6.arrow# from src/main/python/blog/prompt_internalization/roberta/trainer.py
import string
from typing import Any, Dict, Tuple, Union
import torch
import torch.nn.functional as F
from transformers import AutoModelForMaskedLM, AutoTokenizer, Trainer, TrainingArguments
from transformers.modeling_outputs import MaskedLMOutput
from transformers.tokenization_utils_base import BatchEncoding
class MaskedPromptInternalizationTrainingArguments(TrainingArguments):
def __init__(self, *args, temperature: float = 2.0, **kwargs) -> None:
super().__init__(*args, **kwargs)
self.temperature = temperature
class MaskedPromptInternalizationTrainer(Trainer):
def __init__(
self,
*args,
teacher_model: AutoModelForMaskedLM = None,
prompt: str = "The <mask> is a {}.",
tokenizer: AutoTokenizer = None,
**kwargs,
) -> None:
super().__init__(*args, **kwargs)
self.teacher = teacher_model
self._move_model_to_device(self.teacher, self.model.device)
self.teacher.eval()
self.prompt = prompt
self.tokenizer = tokenizer
self.punctuation = set(string.punctuation)
def compute_loss(
self,
model: AutoModelForMaskedLM,
inputs: Dict[str, Union[torch.Tensor, Any]],
return_outputs: bool = False,
) -> Union[Tuple[torch.Tensor, torch.Tensor], torch.Tensor]:
student_output = model(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"]
)
teacher_input = self._prompted_text(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
labels=inputs["labels"],
)
teacher_predictions = self._teacher_predictions(teacher_input)
loss = self._student_loss(
student_output=student_output,
teacher_predictions=teacher_predictions,
labels=inputs["labels"],
)
return (loss, student_output) if return_outputs else loss
def _prompted_text(
self,
input_ids: torch.Tensor,
attention_mask: torch.Tensor,
labels: torch.Tensor,
) -> BatchEncoding:
"""
This decodes all of the inputs, adds the prompt to the end, and then encodes them again.
This is very inefficient.
"""
prompted_text = [
self._add_prompt(
input_ids=input_ids,
attention_mask=attention_mask,
start=start,
length=length,
)
for input_ids, attention_mask, (start, length) in zip(
input_ids,
attention_mask,
labels,
)
]
prompted_tokens = self.tokenizer(
prompted_text, return_tensors="pt", padding=True
)
return prompted_tokens.to(input_ids.device)
def _add_prompt(
self,
input_ids: torch.Tensor,
attention_mask: torch.Tensor,
start: int,
length: int,
) -> torch.Tensor:
input_length = attention_mask.sum()
text = self.tokenizer.decode(input_ids[:input_length], skip_special_tokens=True)
text = text.strip()
if text[-1] not in self.punctuation:
text = text + "."
word = self.tokenizer.decode(input_ids[start : start + length])
word = word.strip()
return text + " " + self.prompt.format(word)
@torch.no_grad()
def _teacher_predictions(self, inputs: BatchEncoding) -> torch.Tensor:
outputs_teacher = self.teacher(**inputs)
mask_indices = inputs.input_ids == self.tokenizer.mask_token_id
return outputs_teacher.logits[mask_indices]
def _student_loss(
self,
student_output: MaskedLMOutput,
teacher_predictions: torch.Tensor,
labels: torch.Tensor,
) -> torch.Tensor:
# Calculating the student prediction is tricky.
# Is the output for a multi token target the mean of the output for each token?
# Should the loss instead be measured per token?
# When calculating this it is very important to avoid breaking back propagation.
# torch.cat will break back propagation, so the loss is calculated per row.
losses = []
for target, output, (start, length) in zip(
teacher_predictions, student_output.logits, labels
):
prediction = output[start : start + length]
prediction = prediction.mean(dim=0)
prediction = F.log_softmax(prediction / self.args.temperature, dim=-1)
target = F.softmax(target / self.args.temperature, dim=-1)
loss = F.kl_div(
input=prediction[None, :],
target=target[None, :],
reduction="batchmean",
log_target=False,
)
loss = loss * (self.args.temperature ** 2)
losses.append(loss)
return sum(losses) / len(losses)from transformers import AutoModelForMaskedLM, DataCollatorWithPadding, AutoTokenizer
training_args = MaskedPromptInternalizationTrainingArguments(
report_to="none",
output_dir=RUN_DIRECTORY,
num_train_epochs=EPOCHS,
# max_steps=MAX_STEPS,
evaluation_strategy="steps",
logging_steps=EVALUATION_STEPS,
eval_steps=EVALUATION_STEPS,
save_steps=EVALUATION_STEPS,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE,
fp16=False,
learning_rate=LEARNING_RATE,
seed=33,
logging_dir=RUN_DIRECTORY / "logs",
save_total_limit=2,
load_best_model_at_end=True,
metric_for_best_model="loss",
greater_is_better=False,
temperature=TEMPERATURE,
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
teacher_model = AutoModelForMaskedLM.from_pretrained(MODEL_NAME)
student_model = AutoModelForMaskedLM.from_pretrained(MODEL_NAME)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
trainer = MaskedPromptInternalizationTrainer(
model=student_model,
args=training_args,
teacher_model=teacher_model,
train_dataset=tweet_split_ds["train"],
eval_dataset=tweet_split_ds["test"],
data_collator=data_collator,
tokenizer=tokenizer,
)
trainer.train()| Step | Training Loss | Validation Loss |
|---|---|---|
| 1000 | 0.816900 | 0.653776 |
| 2000 | 0.666800 | 0.592557 |
| 3000 | 0.624500 | 0.555341 |
| 4000 | 0.602500 | 0.539190 |
| 5000 | 0.571100 | 0.521284 |
| 6000 | 0.552200 | 0.504296 |
| 7000 | 0.542400 | 0.488887 |
| 8000 | 0.527300 | 0.483320 |
| 9000 | 0.511100 | 0.468313 |
| 10000 | 0.504900 | 0.458751 |
| 11000 | 0.498700 | 0.451415 |
| 12000 | 0.484500 | 0.439299 |
| 13000 | 0.478300 | 0.442260 |
| 14000 | 0.466700 | 0.439036 |
| 15000 | 0.462900 | 0.419386 |
| 16000 | 0.457700 | 0.415736 |
| 17000 | 0.451500 | 0.414230 |
| 18000 | 0.442000 | 0.404812 |
| 19000 | 0.435000 | 0.394529 |
| 20000 | 0.425800 | 0.389718 |
| 21000 | 0.422400 | 0.390572 |
| 22000 | 0.422700 | 0.382137 |
| 23000 | 0.412800 | 0.382509 |
| 24000 | 0.411900 | 0.377646 |
| 25000 | 0.406900 | 0.363590 |
| 26000 | 0.397500 | 0.365397 |
| 27000 | 0.353800 | 0.358085 |
| 28000 | 0.354000 | 0.354499 |
| 29000 | 0.348200 | 0.349619 |
| 30000 | 0.348600 | 0.346917 |
| 31000 | 0.343600 | 0.346731 |
| 32000 | 0.340500 | 0.342117 |
| 33000 | 0.336800 | 0.339344 |
| 34000 | 0.336500 | 0.337132 |
| 35000 | 0.333000 | 0.331645 |
| 36000 | 0.329300 | 0.326415 |
| 37000 | 0.328100 | 0.329346 |
| 38000 | 0.328400 | 0.323757 |
| 39000 | 0.322600 | 0.323505 |
| 40000 | 0.317800 | 0.313984 |
| 41000 | 0.320900 | 0.312605 |
| 42000 | 0.316600 | 0.311725 |
| 43000 | 0.311300 | 0.308437 |
| 44000 | 0.307500 | 0.306327 |
| 45000 | 0.304900 | 0.303245 |
| 46000 | 0.303800 | 0.301074 |
| 47000 | 0.301700 | 0.297794 |
| 48000 | 0.298000 | 0.294003 |
| 49000 | 0.298100 | 0.293498 |
| 50000 | 0.295400 | 0.291945 |
| 51000 | 0.294500 | 0.290203 |
TrainOutput(global_step=51894, training_loss=0.4110746412703209, metrics={'train_runtime': 9900.5662, 'train_samples_per_second': 83.864, 'train_steps_per_second': 5.242, 'total_flos': 2.4962527857415496e+16, 'train_loss': 0.4110746412703209, 'epoch': 2.0})student_model.save_pretrained(RUN_DIRECTORY / "best-model")With a trained model we can review some of the outputs that it produces for different nouns.
Let’s see how it does on the sample sentences from earlier:
from transformers import AutoModelForMaskedLM, AutoTokenizer
student_model = AutoModelForMaskedLM.from_pretrained(RUN_DIRECTORY / "best-model")
student_model.eval()
tokenizer = AutoTokenizer.from_pretrained("roberta-base")Could not locate the tokenizer configuration file, will try to use the model config instead.We spotted a large bass in the ocean.
[' fish', ' animal', ' photo', ' picture', ' species', ' creature', ' bird', ' shark', ' bass', ' specimen']
The bass player did not receive the acknowledgment she deserves.
[' player', ' woman', ' bass', ' girl', ' singer', ' man', ' culprit', ' song', ' musician', ' guitar']
The black sea bass, is a member of the wreckfish family.
[' fish', ' male', ' female', ' shark', ' adult', ' second', ' other', ' species', ' bottom', ' head']import torch
@torch.no_grad()
def get_predictions(text: str, start: int, end: int):
print(f"Phrase is: {text}")
tokens = tokenizer(text, return_tensors="pt")
print(f"Target is: {tokenizer.decode(tokens.input_ids[0, start:end])}")
output = student_model(**tokens)
predictions = output.logits[0, start:end].mean(dim=0)
predicted_tokens = predictions.argsort(descending=True)[:10]
predicted_words = tokenizer.batch_decode(predicted_tokens)
print(f"Description is: {predicted_words}")for text, start, end in [
["We spotted a large bass in the ocean.", 5, 6],
["The bass player did not receive the acknowledgment she deserves.", 2, 3],
["The black sea bass, is a member of the wreckfish family.", 4, 5],
]:
get_predictions(text, start, end)
print()Phrase is: We spotted a large bass in the ocean.
Target is: bass
Description is: [' fish', ' picture', ' bass', ' photo', ' animal', ' image', ' creature', ' bird', ' species', ' culprit']
Phrase is: The bass player did not receive the acknowledgment she deserves.
Target is: bass
Description is: [' player', ' singer', ' woman', ' bass', ' musician', ' man', ' guitarist', ' drummer', ' guitar', ' girl']
Phrase is: The black sea bass, is a member of the wreckfish family.
Target is: bass
Description is: [' fish', ' bass', ' shark', ' species', ' lobster', ' following', ' crab', ' animal', ' photo', ' picture']
The output of the prompted model for these inputs was:
We spotted a large bass in the ocean.
[' fish', ' animal', ' photo', ' picture', ' species', ' creature', ' bird', ' shark', ' bass', ' specimen']
The bass player did not receive the acknowledgment she deserves.
[' player', ' woman', ' bass', ' girl', ' singer', ' man', ' culprit', ' song', ' musician', ' guitar']
The black sea bass, is a member of the wreckfish family.
[' fish', ' male', ' female', ' shark', ' adult', ' second', ' other', ' species', ' bottom', ' head']We can compare these to the predictions to get a rough idea of how accurate the model is.
predictions_1 = [' fish', ' picture', ' bass', ' photo', ' animal', ' image', ' creature', ' bird', ' species', ' culprit']
original_1 = [' fish', ' animal', ' photo', ' picture', ' species', ' creature', ' bird', ' shark', ' bass', ' specimen']
predictions_2 = [' player', ' singer', ' woman', ' bass', ' musician', ' man', ' guitarist', ' drummer', ' guitar', ' girl']
original_2 = [' player', ' woman', ' bass', ' girl', ' singer', ' man', ' culprit', ' song', ' musician', ' guitar']
predictions_3 = [' fish', ' bass', ' shark', ' species', ' lobster', ' following', ' crab', ' animal', ' photo', ' picture']
original_3 = [' fish', ' male', ' female', ' shark', ' adult', ' second', ' other', ' species', ' bottom', ' head']len(set(predictions_1) & set(original_1))8len(set(predictions_2) & set(original_2))8len(set(predictions_3) & set(original_3))3len(set(predictions_1) & set(predictions_2))1len(set(predictions_1) & set(predictions_3))6set(predictions_1) & set(predictions_3){' animal', ' bass', ' fish', ' photo', ' picture', ' species'}This certainly is not working perfectly. I do think this is a strong performance with two of the sentences matching in 8 of the top 10 tokens. Furthermore the dissimilar sentences (1 and 2) only have an overlap of a single word, bass, while the similar sentences have 6 matches out of 10.
Even though I trained this for two epochs it could be trained more - the validation loss was still dropping. The settings that I used were also just the ones from the previous post, a hyperparameter search may well find better performing ones.
One of the tasks from SemEval 2013 is Word Sense Induction {% cite Jurgens_semeval-2013task %}. The original source for this dataset seems to be down but copies of it are available. I have found this one which I will be using for this evaluation.
Part of the problem with using this data is that the sentences are encoded in XML and the labels for the data are stored in a separate file. As such there will be a bit of data wrangling to do first.
import pandas as pd
pd.read_xml("/data/word_sense_induction/semeval/2013/13/raw/contexts/xml-format/board.n.xml")| id | lemma | partOfSpeech | token | tokenEnd | tokenStart | instance | |
|---|---|---|---|---|---|---|---|
| 0 | board.n.1 | board | n | board | 191 | 186 | Field Comm's two main functions were to relay ... |
| 1 | board.n.2 | board | n | board | 47 | 42 | . Sadly, he was forced to retire from the boar... |
| 2 | board.n.3 | board | n | board | 171 | 166 | Refinements of both activities have been made ... |
| 3 | board.n.4 | board | n | board | 17 | 12 | The library board had conducted a national sea... |
| 4 | board.n.5 | board | n | board | 87 | 82 | oh yes but but what i meant was why do people ... |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 90 | board.n.94 | board | n | board | 115 | 110 | uh the uh achievement for the let's see how ar... |
| 91 | board.n.95 | board | n | boards | 288 | 282 | This discussion was co-facilitated by Colleen ... |
| 92 | board.n.96 | board | n | boards | 55 | 49 | Most agencies in Texas are run by commissions ... |
| 93 | board.n.97 | board | n | board | 232 | 227 | Understanding how CIOs of leading organization... |
| 94 | board.n.98 | board | n | board | 283 | 278 | Having been through those huge postwar sci-fi ... |
95 rows × 7 columns
There is the more compact senseval2 format, however that is more deeply nested so pandas does not read it nicely. The plain xml format has everything that is required.
The structure of the labels is a space delimited csv file with a variable number of columns. As the column count is varied and the cluster labels are rich I have decided to write a custom bit of code to read it in.
The source data looks like:
board.n board.n.1 board%1:06:00::/4 board%1:06:03::/4
board.n board.n.2 board%1:14:00::/4
board.n board.n.3 board%1:06:00::/4The columns are word, id, word sense, … I want to map those word sense labels into ids as I am just going to cluster the outputs of the model as the evaluation.
from typing import Dict, List, Union
from pathlib import Path
import pandas as pd
class LabelReader:
def __init__(self) -> None:
self.next_id = 0
self.id_map = {}
def to_row(self, line: str) -> Dict[str, Union[str, List[int]]]:
_, row_id, *senses = line.split()
return {
"id": row_id,
"senses": list(map(self.to_id, senses))
}
def to_id(self, sense: str) -> int:
if sense not in self.id_map:
self.id_map[sense] = self.next_id
self.next_id += 1
return self.id_map[sense]
LABELS_FILE = Path("/data/word_sense_induction/semeval/2013/13/raw/keys/gold/nouns.key")
label_reader = LabelReader()
semeval_labels = pd.DataFrame(
map(
label_reader.to_row,
LABELS_FILE.read_text().splitlines()
)
)
semeval_labels| id | senses | |
|---|---|---|
| 0 | board.n.1 | [0, 1] |
| 1 | board.n.2 | [2] |
| 2 | board.n.3 | [0] |
| 3 | board.n.4 | [2] |
| 4 | board.n.5 | [2] |
| ... | ... | ... |
| 1843 | window.n.96 | [223] |
| 1844 | window.n.97 | [223] |
| 1845 | window.n.98 | [234] |
| 1846 | window.n.99 | [223] |
| 1847 | window.n.100 | [223] |
1848 rows × 2 columns
semeval_labels.senses.apply(max).max()234(
semeval_labels
.senses
.explode()
.value_counts()
.reset_index(drop=True)
.plot()
) ; None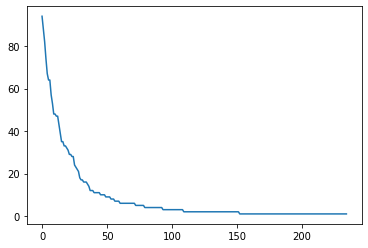
We can see that the label distribution is quite wide with 234 total labels where the most common label is used more than 80 times.
from pathlib import Path
import pandas as pd
SENTENCES_FOLDER = Path("/data/word_sense_induction/semeval/2013/13/raw/contexts/xml-format/")
semeval_df = pd.merge(
pd.concat(map(pd.read_xml, sorted(SENTENCES_FOLDER.glob("*.n.xml")))),
semeval_labels,
left_on="id",
right_on="id",
)
semeval_df| id | lemma | partOfSpeech | token | tokenEnd | tokenStart | instance | senses | |
|---|---|---|---|---|---|---|---|---|
| 0 | board.n.1 | board | n | board | 191 | 186 | Field Comm's two main functions were to relay ... | [0, 1] |
| 1 | board.n.2 | board | n | board | 47 | 42 | . Sadly, he was forced to retire from the boar... | [2] |
| 2 | board.n.3 | board | n | board | 171 | 166 | Refinements of both activities have been made ... | [0] |
| 3 | board.n.4 | board | n | board | 17 | 12 | The library board had conducted a national sea... | [2] |
| 4 | board.n.5 | board | n | board | 87 | 82 | oh yes but but what i meant was why do people ... | [2] |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1843 | window.n.96 | window | n | windows | 73 | 66 | [When Violet and her sisters appeared] they th... | [223] |
| 1844 | window.n.97 | window | n | windows | 89 | 82 | This is certainly a challenging task, but the ... | [223] |
| 1845 | window.n.98 | window | n | window | 135 | 129 | The rationale for interventions in the emergen... | [234] |
| 1846 | window.n.99 | window | n | window | 128 | 122 | The bleak black and white of the scene in the ... | [223] |
| 1847 | window.n.100 | window | n | window | 116 | 110 | like i said i'm just a balcony kind of gardene... | [223] |
1848 rows × 8 columns
semeval_df.to_parquet("/data/word_sense_induction/semeval/2013/13/nouns.gz.parquet", compression="gzip")It looks like the text can be a bit mangled. There is a bracketted section in [When Violet and her sisters appeared] they and the sentence appears to start badly with . Sadly, he was forced to retire from.
The text must be encoded and the lemma turned into a token index to work with the model.
from typing import Any, Dict, Tuple
from spacy.tokens import Span
from transformers import AutoTokenizer
class SemEvalEncoder:
def __init__(self, name: str = "roberta-base") -> None:
self.tokenizer = AutoTokenizer.from_pretrained(name)
def __call__(self, row: pd.Series) -> Dict[str, Any]:
return self.encode(
text=row.instance,
start=row.tokenStart,
end=row.tokenEnd,
)
def encode(self, text: str, start: int, end: int) -> Dict[str, Any]:
tokens = self.tokenizer(text, truncation=True, return_offsets_mapping=True)
labels = self.find(tokens.offset_mapping, start=start, end=end)
return {
"input_ids": tokens.input_ids,
"attention_mask": tokens.attention_mask,
"labels": labels
}
def find(self, offsets: List[Tuple[int, int]], start: int, end: int) -> List[Tuple[int, int]]:
starts = {
start: index
for index, (start, end) in enumerate(offsets)
if start != end
}
ends = {
end: index
for index, (start, end) in enumerate(offsets)
if start != end
}
return starts[start], 1 + ends[end] - starts[start]encoder = SemEvalEncoder()
encoded_df = pd.DataFrame(semeval_df.apply(encoder, axis="columns").tolist(), index=semeval_df.index)
encoded_df| input_ids | attention_mask | labels | |
|---|---|---|---|
| 0 | [0, 27780, 9204, 18, 80, 1049, 8047, 58, 7, 12... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | (34, 1) |
| 1 | [0, 4, 18810, 6, 37, 21, 1654, 7, 7865, 31, 5,... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | (11, 1) |
| 2 | [0, 31842, 179, 11217, 9, 258, 1713, 33, 57, 1... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | (42, 1) |
| 3 | [0, 133, 5560, 792, 56, 2964, 10, 632, 1707, 1... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | (3, 1) |
| 4 | [0, 2678, 4420, 53, 53, 99, 939, 2425, 21, 596... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | (20, 1) |
| ... | ... | ... | ... |
| 1843 | [0, 10975, 1779, 31310, 8, 69, 7502, 1382, 742... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | (15, 1) |
| 1844 | [0, 713, 16, 1819, 10, 4087, 3685, 6, 53, 5, 1... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | (17, 1) |
| 1845 | [0, 133, 23437, 13, 15985, 11, 5, 1923, 2749, ... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | (21, 1) |
| 1846 | [0, 133, 23530, 909, 8, 1104, 9, 5, 1310, 11, ... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | (26, 1) |
| 1847 | [0, 3341, 939, 26, 939, 437, 95, 10, 19988, 76... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | (26, 1) |
1848 rows × 3 columns
This is aligned to the original semeval dataframe so the predictions can be joined back to the original.
What we want now is to run this through the model to get the signature for each row. Then plotting the signature in PCA or something to see if the model output clusters appropriately.
import torch
from transformers import AutoModelForMaskedLM
@torch.no_grad()
def get_predictions(
model: AutoModelForMaskedLM,
input_ids: List[int],
attention_mask: List[int],
labels: Tuple[int, int]
) -> List[float]:
start, length = labels
input_ids = torch.tensor(input_ids, dtype=torch.long, device=model.device)
attention_mask = torch.tensor(attention_mask, dtype=torch.long, device=model.device)
output = model(
input_ids=input_ids[None, :],
attention_mask=attention_mask[None, :]
).logits
prediction = output[0, start:start+length].mean(dim=0)
prediction = prediction.softmax(dim=0)
return prediction.tolist()df = semeval_df.copy()
df["prediction"] = encoded_df.apply(
lambda row: get_predictions(model=student_model, **row),
axis="columns"
)
df| id | lemma | partOfSpeech | token | tokenEnd | tokenStart | instance | senses | prediction | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | board.n.1 | board | n | board | 191 | 186 | Field Comm's two main functions were to relay ... | [0, 1] | [1.2305063634698854e-08, 5.040778461307127e-09... |
| 1 | board.n.2 | board | n | board | 47 | 42 | . Sadly, he was forced to retire from the boar... | [2] | [2.0327217686855192e-09, 2.6563975463744782e-0... |
| 2 | board.n.3 | board | n | board | 171 | 166 | Refinements of both activities have been made ... | [0] | [2.0365833464097705e-08, 4.597210168100219e-09... |
| 3 | board.n.4 | board | n | board | 17 | 12 | The library board had conducted a national sea... | [2] | [2.2280894906856474e-09, 2.0251571530849333e-0... |
| 4 | board.n.5 | board | n | board | 87 | 82 | oh yes but but what i meant was why do people ... | [2] | [2.2438069180452658e-09, 1.0182827914206882e-0... |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 1843 | window.n.96 | window | n | windows | 73 | 66 | [When Violet and her sisters appeared] they th... | [223] | [1.2446962571743825e-08, 4.409422160733811e-09... |
| 1844 | window.n.97 | window | n | windows | 89 | 82 | This is certainly a challenging task, but the ... | [223] | [1.8099743925859002e-08, 6.042446543119695e-09... |
| 1845 | window.n.98 | window | n | window | 135 | 129 | The rationale for interventions in the emergen... | [234] | [5.634586841551936e-08, 5.296822092049069e-09,... |
| 1846 | window.n.99 | window | n | window | 128 | 122 | The bleak black and white of the scene in the ... | [223] | [1.991478537632929e-09, 7.5159434231864e-10, 1... |
| 1847 | window.n.100 | window | n | window | 116 | 110 | like i said i'm just a balcony kind of gardene... | [223] | [6.050367318266581e-09, 2.603556259472839e-09,... |
1848 rows × 9 columns
To cluster this I am going to use dimensionality reduction and then plot the predictions. By showing each lemma separately and coloring the different senses a good cluster would show the different senses separately.
from sklearn.decomposition import PCA
pca_output = PCA(n_components=2).fit_transform(df.prediction.tolist())
df["pca_x"] = pca_output[:, 0].tolist()
df["pca_y"] = pca_output[:, 1].tolist()df.explode("senses").plot.scatter(x="pca_x", y="pca_y", c="senses") ; None
This isn’t a great start, as the output seems to be quite grouped already. Getting clear clusters out of this will be difficult.
from sklearn.manifold import TSNE
tsne_output = TSNE(n_components=2).fit_transform(df.prediction.tolist())
df["tsne_x"] = tsne_output[:, 0].tolist()
df["tsne_y"] = tsne_output[:, 1].tolist()df.explode("senses").plot.scatter(x="tsne_x", y="tsne_y", c="senses") ; None
This visualization is slightly better. T-SNE can manipulate dimensions with the aim of keeping close points together and spreading out distant points. I can see some separate clusters in this output.
The next thing will be to show the clusters for each separate lemma.
def plot_lemma(df: pd.DataFrame, lemma: str, method: str) -> None:
plot_df = df.copy()
plot_df = plot_df[
(plot_df.lemma == lemma)
& (plot_df.senses.str.len() == 1)
]
plot_df = plot_df.explode("senses")
plot_df["senses"] -= plot_df.senses.min()
plot_df.plot.scatter(
x=f"{method}_x",
y=f"{method}_y",
c="senses",
colormap="viridis",
title=lemma
)
for label in sorted(df.lemma.unique()):
plot_lemma(df, lemma=label, method="tsne")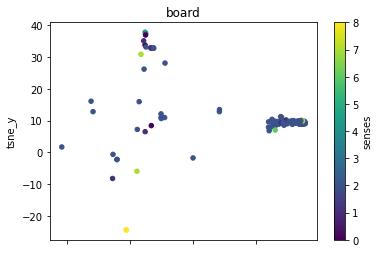
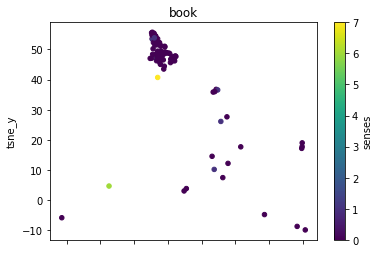
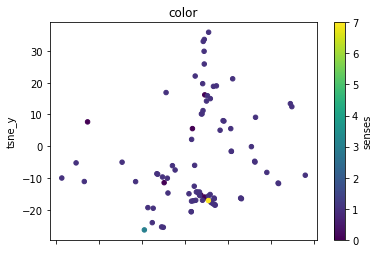
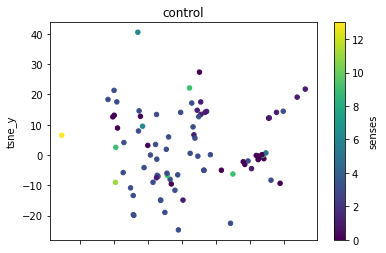
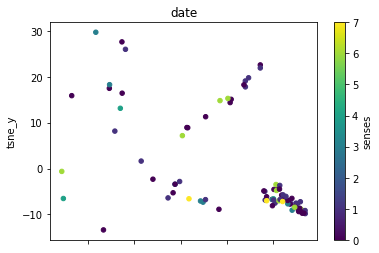
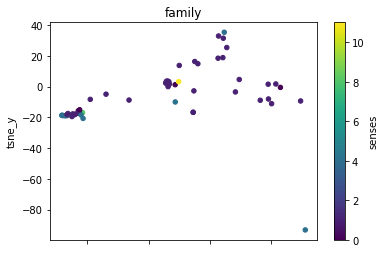
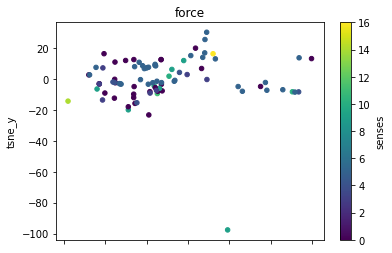
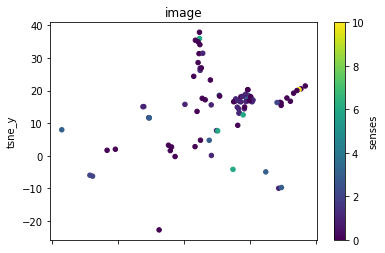
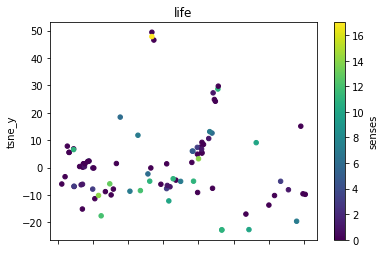
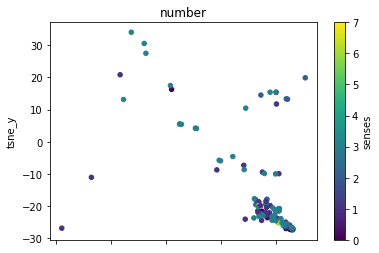
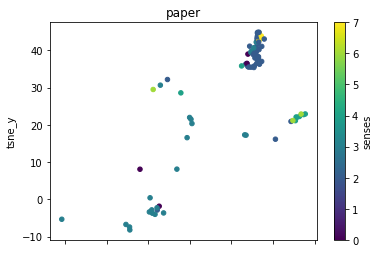
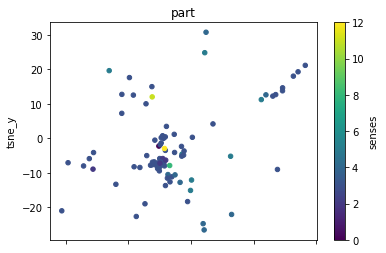
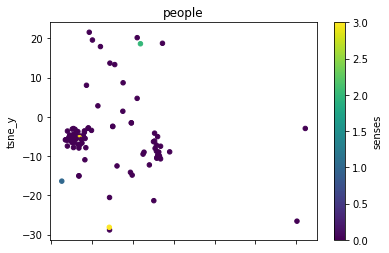
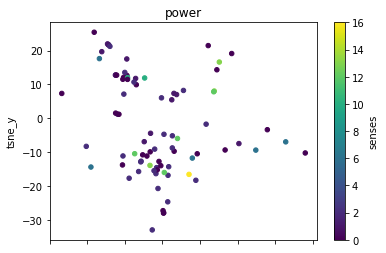
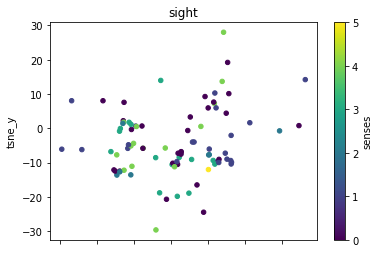
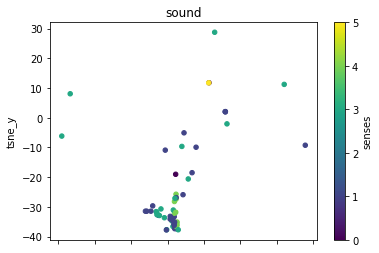
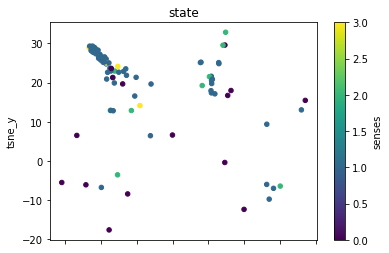
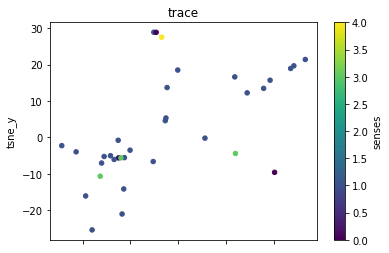
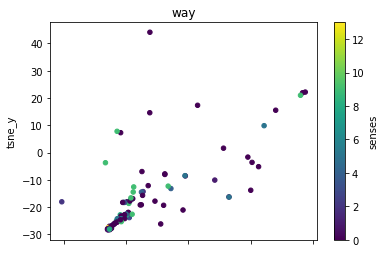
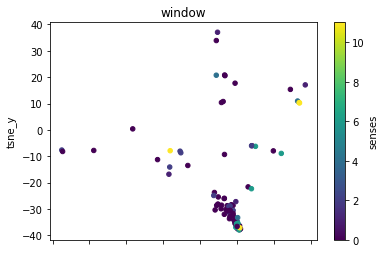
This is a bit disappointing. The model does not well distinguish between the different senses of the words. Using the PCA visualization does not significantly change this.
I wonder how much this is to do with the prompt that was chosen. The internalization of the prompt has worked to a degree at least.