Code
import blog.transformers_loggingThe predictions of the model for the different nouns are dominated by specific tokens. These correspond to words like Name, Location and Person which could apply to almost any noun.
In this post I am going to calculate the most common tokens that the teacher predicts. With these it should be possible to adjust the model predictions or the training process to improve the quality of the predictions.
import blog.transformers_loggingThe common tokens will be calculated by taking the softmax teacher output for every single training row in the dataset. This is almost 100k rows and should provide a good average
from pathlib import Path
import datasets
DATA_FOLDER = Path("/data/tatoeba/2022-06-18/dataset")
train_ds = datasets.load_from_disk(DATA_FOLDER / "roberta-train.dataset")from typing import List
import numpy as np
import torch
from transformers import AutoModelForMaskedLM, AutoTokenizer
from tqdm.auto import tqdm
MODEL_NAME = "roberta-base"
class PromptedFeatureAggregator:
def __init__(self, model_name: str = MODEL_NAME) -> None:
self.model = AutoModelForMaskedLM.from_pretrained(model_name)
self.model.eval()
self.model.cuda()
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
@torch.inference_mode()
def __call__(self, rows: List[List[int]], batch_size: int) -> np.array:
result = torch.zeros(
self.tokenizer.vocab_size,
dtype=torch.float,
device=self.model.device,
)
for index in tqdm(range(0, len(rows), batch_size)):
batch = rows[index : index+batch_size]
result += self.infer_batch(batch)
result = result / len(rows)
return result.cpu().numpy()
@torch.inference_mode()
def infer_batch(self, rows: List[List[int]]) -> torch.Tensor:
padded_inputs = self.tokenizer.pad(
[{"input_ids": input_ids} for input_ids in rows],
padding=True,
return_tensors="pt"
)
padded_inputs = padded_inputs.to(self.model.device)
mask_index = padded_inputs.input_ids == self.tokenizer.mask_token_id
outputs = self.model(**padded_inputs)
predictions = outputs.logits[mask_index]
predictions = predictions.softmax(dim=-1)
predictions = torch.sum(predictions, dim=0)
return predictionsWith this the most common tokens can be calculated.
predictor = PromptedFeatureAggregator()
results = predictor(train_ds["teacher_input_ids"], batch_size=64)from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)import numpy as np
top_n = np.argsort(results)[::-1]
top_10 = top_n[:10]
print(f"The top 10 tokens (of {results.shape[0]:,} tokens) have {results[top_10].sum():0.3f} of total probability mass")
for token, probability in zip(
tokenizer.batch_decode(top_10[:, None]),
results[top_10],
):
print(f" {token: >12}: {probability:0.3f}")The top 10 tokens (of 50,265 tokens) have 0.271 of total probability mass
Name: 0.092
Location: 0.036
Owner: 0.034
Time: 0.028
Color: 0.017
Age: 0.016
Subject: 0.015
Destination: 0.012
Person: 0.012
Date: 0.011top_p50 = top_n[results[top_n].cumsum() <= 0.5]
print(f"top {len(top_p50)} tokens (of {results.shape[0]:,} tokens) have {results[top_p50].sum():0.3f} of total probability mass")
for token, probability in zip(
tokenizer.batch_decode(top_p50[:, None]),
results[top_p50],
):
print(f" {token: >12}: {probability:0.3f}")top 49 tokens (of 50,265 tokens) have 0.497 of total probability mass
Name: 0.092
Location: 0.036
Owner: 0.034
Time: 0.028
Color: 0.017
Age: 0.016
Subject: 0.015
Destination: 0.012
Person: 0.012
Date: 0.011
Item: 0.010
Source: 0.010
Place: 0.009
Purpose: 0.009
Weather: 0.008
Reason: 0.008
Size: 0.007
Type: 0.007
Drink: 0.007
Language: 0.007
People: 0.007
Neighbor: 0.007
Product: 0.006
Vehicle: 0.006
Food: 0.006
Race: 0.006
Job: 0.006
Year: 0.006
Number: 0.006
Course: 0.005
Day: 0.005
Activity: 0.005
Country: 0.005
Category: 0.005
Phone: 0.005
Season: 0.005
Function: 0.005
Other: 0.005
Rider: 0.005
City: 0.004
Species: 0.004
Driver: 0.004
Gender: 0.004
Personality: 0.004
Address: 0.004
Message: 0.004
Event: 0.004
Friend: 0.004
Note: 0.004import pandas as pd
pd.Series(results[top_n]).plot(logy=True) ; None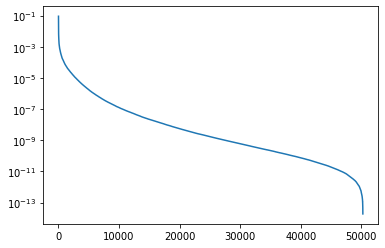
These values are lower than I was expecting, however the probability mass is still heavily clustered over a small number of tokens. Excluding them from use could be a way to improve the model output.
The multilingual RoBERTa model has 250,002 tokens, but the aggregator only worked over 50,265 tokens.
…
This is the English Only Model.
NOOO NOOO IVE BEEN USING THE WRONG MODEL NOO!