Code
import blog.transformers_loggingI’ve been doing this with the wrong model all this time :cry:. The results so far have been achieved with a model which doesn’t understand languages other than English. This is quite surprising.
Anyway this post is going to redo the multilingual prompt internalization technique using an actual multilingual model. I’m using XLM-RoBERTa (Conneau et al. 2019) as that is the model I meant to use in the first place. It is suitable for this as it doesn’t require markers to indicate the specific language being used, instead it determines the language from the input.
import blog.transformers_loggingMODEL_NAME = "xlm-roberta-base"The encoded dataset that I have been using till now was encoded for RoBERTa and is incompatible. I can reuse the same code to encode it for XLM-RoBERTa.
from pathlib import Path
TATOEBA_FOLDER = Path("/data/tatoeba/2022-06-18")
SENTENCES_FILE = TATOEBA_FOLDER / "sentences.tar.bz2"
LINKS_FILE = TATOEBA_FOLDER / "links.tar.bz2"
DATA_FOLDER = Path("/data/tatoeba/2022-06-18/dataset")
DATA_FOLDER.mkdir(exist_ok=True, parents=True)# from src/main/python/blog/prompt_internalization/tatoeba.py
import tarfile
from pathlib import Path
from typing import List
import pandas as pd
def read_tarfile(path: Path, names: List[str]) -> pd.DataFrame:
"""
The Tatoeba files are provided as bz2 compressed tarfiles.
This will correctly load them into pandas.
"""
# there is one file in each tarfile
with tarfile.open(path, "r:*") as handle:
tar_path = handle.getnames()[0]
return pd.read_csv(
handle.extractfile(tar_path),
delimiter="\t",
names=names,
)
# from src/main/python/blog/prompt_internalization/multilingual/dataset.py
from typing import Any, Dict, List, Tuple
import pandas as pd
import spacy
from spacy.matcher import Matcher
from spacy.tokens import Span
from tqdm.auto import tqdm
from transformers import AutoTokenizer
NLP_NAMES = {
"eng": "en_core_web_md",
"deu": "de_core_news_md",
"fra": "fr_core_news_md",
"ita": "it_core_news_md",
"jpn": "ja_core_news_md",
"por": "pt_core_news_md",
"rus": "ru_core_news_md",
"spa": "es_core_news_md",
}
def encode(
translations_df: pd.DataFrame,
model_name: str = "xlm-roberta-base",
# prompt uses str.format to add in the target, so {} will be replaced
prompt: str = " Pet: Dog, Color: Yellow, Vehicle: Tractor, Fruit: Banana,<mask>: {}",
) -> pd.DataFrame:
tqdm.pandas()
encoder = Encoder(model_name=model_name)
prompt_expander = InputPromptExpander(model_name=model_name, prompt=prompt)
teacher_df = pd.DataFrame(
translations_df.progress_apply(
lambda row: encoder.encode(text=row.text, language=row.language),
axis="columns",
).tolist(),
index=translations_df.index,
)
teacher_df = teacher_df[teacher_df.labels.apply(len) == 1]
teacher_df = pd.DataFrame(
teacher_df.progress_apply(
prompt_expander,
axis="columns",
).tolist(),
index=teacher_df.index,
)
teacher_df = teacher_df[["input_ids"]].rename(
columns={"input_ids": "teacher_input_ids"}
)
df = pd.merge(translations_df, teacher_df, left_index=True, right_index=True)
student_df = pd.DataFrame(
df.progress_apply(
lambda row: encoder.encode(
text=row.translation_text, language=row.translation_language
),
axis="columns",
).tolist(),
index=df.index,
)
student_df = student_df[student_df.labels.apply(len) == 1]
df = pd.merge(df, student_df, left_index=True, right_index=True)
df = df.reset_index(drop=True)
return df
class Encoder:
def __init__(self, model_name: str) -> None:
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.extractors = {
language: NounExtractor(spacy_name)
for language, spacy_name in NLP_NAMES.items()
}
def encode(self, text: str, language: str) -> Dict[str, Any]:
nouns = self.extractors[language].get_nouns(text)
tokens = self.tokenizer(text, truncation=True, return_offsets_mapping=True)
labels = self.find(tokens.offset_mapping, nouns)
return {
"input_ids": tokens.input_ids,
"attention_mask": tokens.attention_mask,
"labels": labels,
}
def find(
self, offsets: List[Tuple[int, int]], nouns: List[Span]
) -> List[Tuple[int, int]]:
starts = {
start: index for index, (start, end) in enumerate(offsets) if start != end
}
ends = {
end: index for index, (start, end) in enumerate(offsets) if start != end
}
spans = [
(starts[noun.start_char], 1 + ends[noun.end_char] - starts[noun.start_char])
for noun in nouns
if noun.start_char in starts and noun.end_char in ends
]
return [(start, length) for start, length in spans if length > 0]
class NounExtractor:
def __init__(self, spacy_name: str) -> None:
self.nlp = spacy.load(spacy_name)
self.matcher = Matcher(self.nlp.vocab)
self.matcher.add(
"nouns",
[
[{"POS": {"IN": ["NOUN", "PROPN"]}, "OP": "+"}],
],
)
def get_nouns(self, text: str) -> List[Span]:
doc = self.nlp(text)
return self.matcher(doc, as_spans=True)
class InputPromptExpander:
def __init__(
self,
model_name: str,
prompt: str,
) -> None:
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.prompt = prompt
def __call__(self, row: pd.Series) -> List[int]:
return self.add_prompt(input_ids=row.input_ids, noun=row.labels[0])
def add_prompt(self, input_ids: List[int], noun: Tuple[int, int]) -> List[int]:
input_text = self.tokenizer.decode(input_ids, skip_special_tokens=True)
input_text = input_text.strip()
if not input_text[-1] in {".", "?", "!"}:
input_text = input_text + "."
noun_start, noun_length = noun
noun = self.tokenizer.decode(input_ids[noun_start : noun_start + noun_length])
noun = noun.strip()
# capitalize is a string function, but that lowercases the rest of the word
# if we have an acronym or similar then it might all be capital letters already
noun = noun[0].upper() + noun[1:]
prompt = self.prompt.format(noun)
return self.tokenizer(input_text + prompt)Once the data is encoded the longest noun by token count can be found. When encoding the dataset for RoBERTa there was a Russian noun which took 20 tokens to encode. That should’ve been a red flag.
sentences_df = read_tarfile(SENTENCES_FILE, names=["id", "language", "text"])
sentences_df = sentences_df.set_index("id", drop=True)
# example is [1, 77]
# sentence 77 is a translation of sentence 1
links_df = read_tarfile(LINKS_FILE, names=["sentence_id", "translation_id"])
print(f"Read {len(sentences_df):,} sentences and {len(links_df):,} links")
# join the sentences together via the links to get the translations
translation_map = links_df.set_index("sentence_id").translation_id.to_dict()
translation_df = sentences_df.copy()
translation_df["translation_id"] = sentences_df.index.map(translation_map)
translation_df = translation_df.dropna()
translation_df["translation_language"] = translation_df.translation_id.map(sentences_df.language)
translation_df["translation_text"] = translation_df.translation_id.map(sentences_df.text)
translation_df = translation_df.drop(columns="translation_id")
translation_df
# restrict the translations to a source of english and a translation of non-english
english_df = translation_df[(translation_df.language == "eng") & (translation_df.translation_language != "eng")]
english_df
# further restrict the translations to the 7 languages we have spacy models for
restricted_df = english_df[
english_df.translation_language.isin({
"deu",
"fra",
"ita",
"jpn",
"por",
"rus",
"spa",
})
].copy()Read 10,467,414 sentences and 21,259,444 linksdf = encode(
translations_df=restricted_df,
model_name=MODEL_NAME,
prompt=" Pet: Dog, Color: Yellow, Vehicle: Tractor, Fruit: Banana,<mask>: {}",
)df.to_parquet(DATA_FOLDER / "xlm-roberta.gz.parquet", compression="gzip")from typing import Tuple
import datasets
import pandas as pd
train_languages = {
"rus",
"deu",
"ita",
"fra",
"jpn",
}
test_languages = {
"por",
"spa",
}
def to_datasets(df: pd.DataFrame) -> Tuple[datasets.Dataset, datasets.Dataset]:
train_ds = datasets.Dataset.from_pandas(
df[df.translation_language.isin(train_languages)]
)
test_ds = datasets.Dataset.from_pandas(
df[df.translation_language.isin(test_languages)]
)
return train_ds, test_dstrain_ds, test_ds = to_datasets(df)
train_ds.save_to_disk(DATA_FOLDER / "xlm-roberta-train.dataset")
test_ds.save_to_disk(DATA_FOLDER / "xlm-roberta-test.dataset")
print(f"the train dataset is {len(train_ds):,} rows")
print(f"the test dataset is {len(test_ds):,} rows")the train dataset is 97,752 rows
the test dataset is 23,157 rowsPreviously there were 96,680 training rows and 23,310 test rows. The difference is likely down to the noun extraction code which isn’t perfect.
Now that we have the encoded data we can quickly look at the difference in the prompt:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.decode(df.iloc[0].teacher_input_ids)'<s> I was in the mountains. Pet: Dog, Color: Yellow, Vehicle: Tractor, Fruit: Banana,<mask> : Mountains</s>'There is a stray space before the colon that separates the type from the example. It may well be that the mask token forces this, so let’s test it.
tokenizer.decode(tokenizer("<mask>: Mountains").input_ids)'<s><mask> : Mountains</s>'Based on this it’s not possible to remove that space.
The length of the matched nouns should’ve been a red flag before. I want to review the length of the nouns to check that there are not any similar problems.
import pandas as pd
df = pd.read_parquet("/data/tatoeba/2022-06-18/dataset/xlm-roberta.gz.parquet")df| language | text | translation_language | translation_text | teacher_input_ids | input_ids | attention_mask | labels | |
|---|---|---|---|---|---|---|---|---|
| 0 | eng | I was in the mountains. | fra | J'étais à la montagne. | [0, 87, 509, 23, 70, 101120, 7, 5, 26516, 12, ... | [0, 821, 25, 67749, 253, 21, 129836, 5, 2] | [1, 1, 1, 1, 1, 1, 1, 1, 1] | [[6, 1]] |
| 1 | eng | I told them to send me another ticket. | deu | Ich sagte ihnen, sie sollen mir eine neue Fahr... | [0, 87, 30745, 2856, 47, 25379, 163, 15700, 99... | [0, 2484, 37519, 37616, 4, 1329, 40344, 2296, ... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] | [[10, 2]] |
| 2 | eng | It depends on the context. | deu | Das hängt vom Kontext ab. | [0, 1650, 56566, 7, 98, 70, 43701, 5, 26516, 1... | [0, 1858, 161677, 4858, 3692, 22829, 1563, 5, 2] | [1, 1, 1, 1, 1, 1, 1, 1, 1] | [[4, 2]] |
| 3 | eng | The Germans are very crafty. | ita | I tedeschi sono molto furbi. | [0, 581, 30839, 7, 621, 4552, 131346, 53, 5, 2... | [0, 87, 120, 988, 1861, 1389, 5802, 16387, 964... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] | [[2, 3]] |
| 4 | eng | But the universe is infinite. | rus | Однако Вселенная бесконечна. | [0, 4966, 70, 14997, 13, 83, 54241, 13, 5, 265... | [0, 21199, 417, 68713, 2233, 11271, 1417, 336,... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] | [[2, 3]] |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 120904 | eng | These batteries can be recharged. | deu | Diese Batterien sind wiederaufladbar. | [0, 32255, 103683, 7, 831, 186, 456, 69674, 71... | [0, 13829, 163153, 33, 1276, 4077, 18876, 6616... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] | [[2, 2]] |
| 120905 | eng | It still works? "Yup, all it needs is new batt... | spa | ¿Eso todavía funciona? "Si, solo necesita pila... | [0, 1650, 7464, 43240, 32, 44, 1723, 2037, 4, ... | [0, 3936, 16474, 31, 73957, 26558, 32, 44, 885... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ... | [[12, 2]] |
| 120906 | eng | I can write kanji. | jpn | 私は漢字が書けます。 | [0, 87, 831, 33022, 203, 658, 5, 26516, 12, 41... | [0, 65579, 39353, 7234, 281, 4525, 13871, 5574... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1] | [[2, 2]] |
| 120907 | eng | They ran to the scene. | jpn | 現場へと走った。 | [0, 10660, 13028, 47, 70, 28302, 5, 26516, 12,... | [0, 6, 24345, 135563, 3469, 6219, 30, 2] | [1, 1, 1, 1, 1, 1, 1, 1] | [[2, 1]] |
| 120908 | eng | Where exactly did you meet Tom? | jpn | そもそも、どこでトムと会ったの? | [0, 78662, 66161, 6777, 398, 23356, 8352, 32, ... | [0, 6, 140851, 37, 55325, 507, 5522, 13091, 61... | [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1] | [[6, 2]] |
120909 rows × 8 columns
from typing import Tuple
def get_noun_length(label: Tuple[int, int]) -> int:
return label[0][1]df.labels.apply(get_noun_length).describe()count 120909.000000
mean 1.407017
std 0.695037
min 1.000000
25% 1.000000
50% 1.000000
75% 2.000000
max 11.000000
Name: labels, dtype: float64(
df.labels
.apply(get_noun_length)
.sort_values()
.reset_index(drop=True)
.plot()
) ; None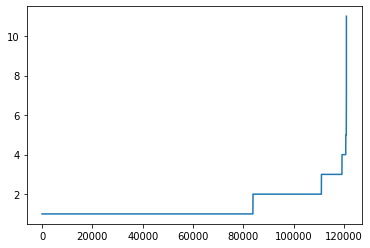
This looks more encouraging as we can see that only a very small number of nouns have a lot of tokens. We can review the top end of the noun token count to check that it looks reasonable.
import pandas as pd
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
def get_noun(row: pd.Series) -> str:
input_ids = row.input_ids
start, length = row.labels[0]
noun = input_ids[start:start+length]
return tokenizer.decode(noun)mask = df.labels.apply(get_noun_length) >= 7
for row in df[mask].iloc:
text = row.translation_text
noun = get_noun(row)
print(f"{noun}: {text}")Postnasal-Drip-Syndrom: Ich habe oft ein Postnasal-Drip-Syndrom.
Mackintosh-Jungen: Sie hilft dem Mackintosh-Jungen.
Siebzigerjahremusik: Ich mag keine Siebzigerjahremusik.
Die-letzten-Sein: Wir sind die ersten beim Die-letzten-Sein.
Japanisch-Chinesisch-Wörterbuch: Ich hätte gerne dieses Japanisch-Chinesisch-Wörterbuch.
super-duper-misil: Lo llamo el super-duper-misil.
Französischwörterbuch: Brauche ich ein Französischwörterbuch?
Holzwäscheklammern: Ich habe Holzwäscheklammern.There are only 8 nouns out of 120,909 rows that have 7 or more tokens and hyphenated onee dominate the list. This seems reasonable.
The training code from before should continue to work. Previous posts used the wrong model, not the wrong code!
# from src/main/python/blog/prompt_internalization/multilingual/roberta/trainer.py
from itertools import starmap
from typing import Any, Dict, List, Optional, Tuple, Union
import torch
import torch.nn.functional as F
from transformers import AutoModelForMaskedLM, AutoTokenizer, Trainer, TrainingArguments
from transformers.modeling_outputs import MaskedLMOutput
class MultilingualMaskedPromptInternalizationTrainingArguments(TrainingArguments):
def __init__(
self,
*args,
temperature: float = 2.0,
mean_prediction: bool = True,
ignore_tokens: Optional[List[int]] = None,
**kwargs,
) -> None:
super().__init__(*args, **kwargs)
self.temperature = temperature
self.mean_prediction = mean_prediction
if ignore_tokens is not None:
self.ignore_tokens = ignore_tokens
else:
self.ignore_tokens = []
class MultilingualMaskedPromptInternalizationTrainer(Trainer):
def __init__(
self,
*args,
teacher_model: AutoModelForMaskedLM = None,
tokenizer: AutoTokenizer = None,
**kwargs,
) -> None:
super().__init__(*args, **kwargs)
self.teacher = teacher_model
self._move_model_to_device(self.teacher, self.model.device)
self.teacher.eval()
self.mask_token_id = tokenizer.mask_token_id
def compute_loss(
self,
model: AutoModelForMaskedLM,
inputs: Dict[str, Union[torch.Tensor, Any]],
return_outputs: bool = False,
) -> Union[Tuple[torch.Tensor, torch.Tensor], torch.Tensor]:
outputs: MaskedLMOutput = model(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"]
)
if self.args.mean_prediction:
predictions = self._student_predictions_mean(
outputs=outputs, labels=inputs["labels"]
)
else:
predictions = self._student_predictions_first(
outputs=outputs, labels=inputs["labels"]
)
targets = self._teacher_predictions(
input_ids=inputs["teacher_input_ids"],
attention_mask=inputs["teacher_attention_mask"],
)
loss = self._loss(predictions=predictions, targets=targets)
if not return_outputs:
return loss
# This directly calculates the kl_div and overlap metrics.
# It's much faster to do this using CUDA operations instead of waiting for cpu numpy.
with torch.inference_mode():
kl_div = F.kl_div(
input=F.log_softmax(predictions.to(torch.float32), dim=-1),
target=F.softmax(targets.to(torch.float32), dim=-1),
reduction="none",
log_target=False,
)
kl_div = kl_div.sum(dim=1)
overlap = starmap(
torch.isin,
zip(
predictions.argsort(descending=True)[:, :10],
targets.argsort(descending=True)[:, :10],
),
)
overlap = map(torch.sum, overlap)
overlap = torch.tensor(list(overlap), device=self.model.device)
overlap = overlap / 10
# This will reshape the metrics to be [batch_size, 2] which will then
# get correctly passed to the metric calculation
metric_output = torch.cat([kl_div[:, None], overlap[:, None]], dim=1)
return loss, metric_output
@torch.inference_mode()
def _teacher_predictions(
self, input_ids: torch.Tensor, attention_mask: torch.Tensor
) -> torch.Tensor:
outputs_teacher = self.teacher(
input_ids=input_ids,
attention_mask=attention_mask,
)
mask_indices = input_ids == self.mask_token_id
teacher_predictions = outputs_teacher.logits[mask_indices]
teacher_predictions[:, self.args.ignore_tokens] = teacher_predictions.min()
return teacher_predictions
def _student_predictions_mean(
self, outputs: MaskedLMOutput, labels: torch.Tensor
) -> torch.Tensor:
# When calculating this it is very important to avoid breaking back propagation.
# torch.cat will break back propagation, so the prediction is added per row to a holder
logits = outputs.logits
predictions = torch.zeros(logits.shape[0], device=logits.device)
for index, (start, length) in enumerate(labels):
prediction = logits[index, start : start + length]
prediction = prediction.mean(dim=0)
predictions[index] += prediction
return predictions
def _student_predictions_first(
self,
outputs: MaskedLMOutput,
labels: torch.Tensor,
) -> torch.Tensor:
return outputs.logits[range(outputs.logits.shape[0]), labels[:, 0]]
def _loss(self, predictions: torch.Tensor, targets: torch.Tensor) -> torch.Tensor:
predictions = F.log_softmax(
predictions.to(torch.float32) / self.args.temperature, dim=-1
)
targets = F.softmax(targets.to(torch.float32) / self.args.temperature, dim=-1)
loss = F.kl_div(
input=predictions,
target=targets,
reduction="batchmean",
log_target=False,
)
return loss * (self.args.temperature**2)
# from src/main/python/blog/prompt_internalization/multilingual/roberta/collator.py
from typing import Any, Dict, List
from transformers import AutoTokenizer
class TeacherStudentCollator:
"""
The teacher inputs need to be padded and have an associated attention mask.
"""
def __init__(self, tokenizer: AutoTokenizer) -> None:
self.tokenizer = tokenizer
def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:
teacher_inputs = self._teacher_inputs(features)
student_inputs = self._student_inputs(features)
batch = {**teacher_inputs, **student_inputs}
if "label" in batch:
batch["labels"] = batch["label"]
del batch["label"]
if "label_ids" in batch:
batch["labels"] = batch["label_ids"]
del batch["label_ids"]
return batch
def _teacher_inputs(self, features: List[Dict[str, Any]]) -> Dict[str, List[Any]]:
teacher_inputs = [{"input_ids": row["teacher_input_ids"]} for row in features]
teacher_batch = self.tokenizer.pad(
teacher_inputs,
padding=True,
return_tensors="pt",
)
return {
"teacher_input_ids": teacher_batch["input_ids"],
"teacher_attention_mask": teacher_batch["attention_mask"],
}
def _student_inputs(self, features: List[Dict[str, Any]]) -> Dict[str, List[Any]]:
student_inputs = [
{
"input_ids": row["input_ids"],
"labels": row["labels"][0], # known to have a single entry
}
for row in features
]
return self.tokenizer.pad(
student_inputs,
padding=True,
return_tensors="pt",
)
# from src/main/python/blog/prompt_internalization/multilingual/roberta/metrics.py
from typing import Dict
from transformers import EvalPrediction
def compute_metrics(model_output: EvalPrediction) -> Dict[str, float]:
kl_div = model_output.predictions[:, 0].mean()
overlap = model_output.predictions[:, 1].mean()
return {
"kl_div": kl_div,
"overlap": overlap,
}
# from src/main/python/blog/prompt_internalization/multilingual/roberta/train.py
from pathlib import Path
from typing import List, Optional
import datasets
from transformers import AutoModelForMaskedLM, AutoTokenizer
from .collator import TeacherStudentCollator
from .metrics import compute_metrics
from .trainer import (
MultilingualMaskedPromptInternalizationTrainer,
MultilingualMaskedPromptInternalizationTrainingArguments,
)
DATASET_FOLDER = Path("/data/tatoeba/2022-06-18/dataset/")
MODEL_FOLDER = Path("/data/prompt-internalization/multilingual/")
RUN_FOLDER = Path("/tmp/runs")
MODEL_FOLDER.mkdir(parents=True, exist_ok=True)
RUN_FOLDER.mkdir(parents=True, exist_ok=True)
def train(
*,
model_name: str = "xlm-roberta-base",
dataset_name: str = "xlm-roberta",
batch_size: int = 64,
learning_rate: float = 1e-4,
temperature: float = 2,
fp16: bool = False,
mean_prediction: bool = False,
ignore_tokens: Optional[List[int]] = None,
epochs: Optional[float] = 2,
max_steps: int = -1,
evaluation_steps: int = 500,
) -> Path:
run_name = "-".join(
[
f"{model_name}",
f"e{epochs}" if max_steps == -1 else f"ms{max_steps}",
f"bs{batch_size}",
f"lr{learning_rate}",
f"t{temperature}",
]
+ (["fp16"] if fp16 else [])
+ (["mean"] if mean_prediction else [])
+ ([f"it{len(ignore_tokens)}"] if ignore_tokens else [])
)
print(f"Starting {run_name}")
train_ds = datasets.load_from_disk(DATASET_FOLDER / f"{dataset_name}-train.dataset")
test_ds = datasets.load_from_disk(DATASET_FOLDER / f"{dataset_name}-test.dataset")
training_args = MultilingualMaskedPromptInternalizationTrainingArguments(
report_to="none",
output_dir=RUN_FOLDER,
num_train_epochs=epochs,
max_steps=max_steps,
seed=33,
# number of steps before moving evaluation results from GPU to CPU see
# https://discuss.huggingface.co/t/cuda-out-of-memory-when-using-trainer-with-compute-metrics/2941
eval_accumulation_steps=5,
#
# hyperparameters
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
fp16=fp16,
temperature=temperature,
mean_prediction=mean_prediction,
ignore_tokens=ignore_tokens,
learning_rate=learning_rate,
#
# evaluation settings
evaluation_strategy="steps",
logging_steps=evaluation_steps,
eval_steps=evaluation_steps,
save_steps=evaluation_steps,
#
# checkpoint settings
logging_dir=RUN_FOLDER / "logs",
save_total_limit=2,
load_best_model_at_end=True,
metric_for_best_model="overlap",
greater_is_better=True,
remove_unused_columns=False,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
teacher_model = AutoModelForMaskedLM.from_pretrained(model_name)
student_model = AutoModelForMaskedLM.from_pretrained(model_name)
data_collator = TeacherStudentCollator(tokenizer=tokenizer)
trainer = MultilingualMaskedPromptInternalizationTrainer(
model=student_model,
args=training_args,
teacher_model=teacher_model,
train_dataset=train_ds,
eval_dataset=test_ds,
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
student_model.save_pretrained(MODEL_FOLDER / run_name)
return MODEL_FOLDER / run_name
# from src/main/python/blog/prompt_internalization/multilingual/roberta/evaluate.py
from pathlib import Path
from typing import List, Optional, Tuple
import torch
from transformers import AutoModelForMaskedLM, AutoTokenizer
def evaluate(
model_name: str, model_path: Path, ignore_tokens: Optional[List[int]] = None
) -> None:
if ignore_tokens is None:
ignore_tokens = []
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForMaskedLM.from_pretrained(model_path)
model.eval()
bass_evaluation(model=model, tokenizer=tokenizer, ignore_tokens=ignore_tokens)
friday_evaluation(model=model, tokenizer=tokenizer, ignore_tokens=ignore_tokens)
malibu_evaluation(model=model, tokenizer=tokenizer, ignore_tokens=ignore_tokens)
football_evaluation(model=model, tokenizer=tokenizer, ignore_tokens=ignore_tokens)
def bass_evaluation(
model: AutoModelForMaskedLM, tokenizer: AutoTokenizer, ignore_tokens: List[int]
) -> None:
first_phrase = "We spotted a large bass in the ocean."
second_phrase = "The bass player did not receive the acknowledgment she deserves."
third_phrase = "The black sea bass, is a member of the wreckfish family."
first_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=first_phrase,
noun="bass",
ignore_tokens=ignore_tokens,
)
second_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=second_phrase,
noun="bass",
ignore_tokens=ignore_tokens,
)
third_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=third_phrase,
noun="bass",
ignore_tokens=ignore_tokens,
)
print("=== BASS EVALUATION ===")
print(f"First Phrase is: {first_phrase} Target is: bass")
print(f"Description is: {', '.join(first_predicted_words)}")
print()
print(f"Second Phrase is: {second_phrase} Target is: bass")
print(f"Description is: {', '.join(second_predicted_words)}")
print()
print(f"Third Phrase is: {third_phrase} Target is: bass")
print(f"Description is: {', '.join(third_predicted_words)}")
print()
print(
f"First & Second: {sorted(set(first_predicted_words) & set(second_predicted_words))}"
)
print(
f"First & Third: {sorted(set(first_predicted_words) & set(third_predicted_words))}"
)
print(
f"Second & Third: {sorted(set(second_predicted_words) & set(third_predicted_words))}"
)
print()
def friday_evaluation(
model: AutoModelForMaskedLM, tokenizer: AutoTokenizer, ignore_tokens: List[int]
) -> None:
spanish_text = "Friday es mi canción favorita."
english_text = "Friday is my favourite song."
spanish_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=spanish_text,
noun="Friday",
ignore_tokens=ignore_tokens,
)
english_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=english_text,
noun="Friday",
ignore_tokens=ignore_tokens,
)
overlap = set(spanish_predicted_words) & set(english_predicted_words)
difference = set(spanish_predicted_words) ^ set(english_predicted_words)
print("=== FRIDAY EVALUATION ===")
print(f"Spanish Phrase is: {spanish_text}")
print(f"Spanish Description is: {', '.join(spanish_predicted_words)}")
print(f"English Phrase is: {english_text}")
print(f"English Description is: {', '.join(english_predicted_words)}")
print()
print(f"Description Overlap is: {', '.join(sorted(overlap))}")
print(f"Description Difference is: {', '.join(sorted(difference))}")
print()
def malibu_evaluation(
model: AutoModelForMaskedLM, tokenizer: AutoTokenizer, ignore_tokens: List[int]
) -> None:
text = "I like to drive my Malibu while drinking Malibu."
first_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=text,
noun="Malibu",
ignore_tokens=ignore_tokens,
)
second_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=text,
noun="Malibu",
index=1,
ignore_tokens=ignore_tokens,
)
print("=== MALIBU EVALUATION ===")
print(f"Phrase is: {text}")
print(f"First Malibu (car) Description is: {', '.join(first_predicted_words)}")
print(f"Second Malibu (drink) Description is: {', '.join(second_predicted_words)}")
print()
print(
f"First & Second: {sorted(set(first_predicted_words) & set(second_predicted_words))}"
)
print(
f"First ^ Second: {sorted(set(first_predicted_words) ^ set(second_predicted_words))}"
)
print()
def football_evaluation(
model: AutoModelForMaskedLM, tokenizer: AutoTokenizer, ignore_tokens: List[int]
) -> None:
spanish_phrase = (
"Retiremos el equipo de la cancha, "
"Boca no merece jugar esta copa que "
"hace tiempo viene siendo desprestigiada.\n"
"Ya no se juega al futbol."
)
english_phrase = (
"Let's remove the team from the field, "
"Boca does not deserve to play this cup that "
"has long been discredited. "
"Football is no longer played."
)
print("=== FOOTBALL EVALUATION ===")
print(f"Spanish Phrase is: {spanish_phrase}")
print(f"English Phrase is: {english_phrase}")
print()
for spanish_noun, english_noun in [
["equipo", "team"],
["Boca", "Boca"],
["copa", "cup"],
["tiempo", "long"],
["futbol", "Football"],
]:
spanish_description = get_predictions(
model=model,
tokenizer=tokenizer,
text=spanish_phrase,
noun=spanish_noun,
ignore_tokens=ignore_tokens,
)
english_description = get_predictions(
model=model,
tokenizer=tokenizer,
text=english_phrase,
noun=english_noun,
ignore_tokens=ignore_tokens,
)
overlap = set(spanish_description) & set(english_description)
difference = set(spanish_description) ^ set(english_description)
print(f"Spanish word is: {spanish_noun}, English word is: {english_noun}")
print(f"Spanish Description is: {', '.join(spanish_description)}")
print(f"English Description is: {', '.join(english_description)}")
print(f"Overlap is: {', '.join(sorted(overlap))} ({len(overlap)})")
print(f"Difference is: {', '.join(sorted(difference))} ({len(difference)})")
print()
@torch.inference_mode()
def get_predictions(
*,
model: AutoModelForMaskedLM,
tokenizer: AutoTokenizer,
text: str,
noun: str,
index: int = 0,
ignore_tokens: Optional[List[int]] = None,
) -> List[str]:
if ignore_tokens is None:
ignore_tokens = []
tokens = tokenizer(text, return_tensors="pt")
start, _end = get_noun(
tokenizer=tokenizer, tokens=tokens.input_ids[0], noun=noun, index=index
)
output = model(**tokens)
predictions = output.logits[0, start]
predictions[ignore_tokens] = predictions.min()
predicted_tokens = predictions.argsort(descending=True)[:10]
predicted_words = [
word.strip() for word in tokenizer.batch_decode(predicted_tokens)
]
return predicted_words
def get_noun(
tokenizer: AutoTokenizer, tokens: torch.Tensor, noun: str, index: int
) -> Tuple[int, int]:
length = tokens.shape[0]
current_index = index
for start_index in range(length):
word = tokenizer.decode(tokens[start_index]).strip()
if not noun.startswith(word):
continue
for end_index in range(start_index + 1, length):
word = tokenizer.decode(tokens[start_index:end_index]).strip()
if not noun == word:
continue
if current_index > 0:
current_index -= 1
else:
return start_index, end_index
raise AssertionError(f"Did not find {noun}[{index}] in {tokenizer.decode(tokens)}")Now we get to see how well the correct model performs at this task.
model_path = train(
model_name=MODEL_NAME,
batch_size=32,
learning_rate=1e-4,
temperature=2,
mean_prediction=False,
epochs=2,
evaluation_steps=1_000,
)/home/matthew/.cache/pypoetry/virtualenvs/blog-HrtMnrOS-py3.10/lib/python3.10/site-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(| Step | Training Loss | Validation Loss |
|---|
It’s running out of memory! I need to recreate the test dataset with a sample of the current rows. The change from roberta, at 50k tokens to xlm-roberta at 250k tokens is the problem.
I can get around the memory problems by reducing the size of the test dataset.
from pathlib import Path
import pandas as pd
DATA_FOLDER = Path("/data/tatoeba/2022-06-18/dataset")from typing import Tuple
import datasets
import pandas as pd
train_languages = {
"rus",
"deu",
"ita",
"fra",
"jpn",
}
test_languages = {
"por",
"spa",
}
def to_datasets_sample(df: pd.DataFrame, test_size: int) -> Tuple[datasets.Dataset, datasets.Dataset]:
train_ds = datasets.Dataset.from_pandas(
df[df.translation_language.isin(train_languages)]
)
test_df = df[df.translation_language.isin(test_languages)]
if len(test_df) > test_size:
test_df = test_df.sample(n=test_size)
test_ds = datasets.Dataset.from_pandas(test_df)
return train_ds, test_dsdf = pd.read_parquet(DATA_FOLDER / "xlm-roberta.gz.parquet")
# 10k was still problematic
train_ds, test_ds = to_datasets_sample(df, 5_000)
train_ds.save_to_disk(DATA_FOLDER / "xlm-roberta-train.dataset")
test_ds.save_to_disk(DATA_FOLDER / "xlm-roberta-test.dataset")
print(f"the train dataset is {len(train_ds):,} rows")
print(f"the test dataset is {len(test_ds):,} rows")the train dataset is 97,687 rows
the test dataset is 5,000 rowsWith this I can train the correct model.
model_path = train(
model_name=MODEL_NAME,
batch_size=32, # could go to 64?
learning_rate=1e-4,
temperature=2,
mean_prediction=False,
epochs=2,
evaluation_steps=1_000,
)/home/matthew/.cache/pypoetry/virtualenvs/blog-HrtMnrOS-py3.10/lib/python3.10/site-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(| Step | Training Loss | Validation Loss | Kl Div | Overlap |
|---|---|---|---|---|
| 1000 | 0.403100 | 0.275264 | 0.250485 | 0.686971 |
| 2000 | 0.277600 | 0.245149 | 0.222516 | 0.706484 |
| 3000 | 0.245900 | 0.238975 | 0.220361 | 0.712637 |
| 4000 | 0.203500 | 0.221864 | 0.199035 | 0.726285 |
| 5000 | 0.190600 | 0.210916 | 0.193627 | 0.733698 |
| 6000 | 0.181100 | 0.204709 | 0.186144 | 0.738468 |
evaluate(model_name=MODEL_NAME, model_path=model_path)Could not locate the tokenizer configuration file, will try to use the model config instead.=== BASS EVALUATION ===
First Phrase is: We spotted a large bass in the ocean. Target is: bass
Description is: Location, Description, Area, Type, Name, View, Color, Material, Position, Size
Second Phrase is: The bass player did not receive the acknowledgment she deserves. Target is: bass
Description is: Description, Name, Type, Title, Status, Owner, Position, Details, Location, Material
Third Phrase is: The black sea bass, is a member of the wreckfish family. Target is: bass
Description is: Owner, Type, Description, Name, Family, Status, Animal, Color, Cat, Country
First & Second: ['Description', 'Location', 'Material', 'Name', 'Position', 'Type']
First & Third: ['Color', 'Description', 'Name', 'Type']
Second & Third: ['Description', 'Name', 'Owner', 'Status', 'Type']
=== FRIDAY EVALUATION ===
Spanish Phrase is: Friday es mi canción favorita.
Spanish Description is: Description, Album, Title, Tags, Tag, Status, Location, Name, Theme, Music
English Phrase is: Friday is my favourite song.
English Description is: Description, Album, Title, Tag, Tags, Status, Location, Name, Theme, Song
Description Overlap is: Album, Description, Location, Name, Status, Tag, Tags, Theme, Title
Description Difference is: Music, Song
=== MALIBU EVALUATION ===
Phrase is: I like to drive my Malibu while drinking Malibu.
First Malibu (car) Description is: Food, Type, Color, Material, Name, Aroma, Product, Cat, Description, Theme
Second Malibu (drink) Description is: Food, Material, Aroma, Color, Drink, Type, Name, Wine, Product, Theme
First & Second: ['Aroma', 'Color', 'Food', 'Material', 'Name', 'Product', 'Theme', 'Type']
First ^ Second: ['Cat', 'Description', 'Drink', 'Wine']
=== FOOTBALL EVALUATION ===
Spanish Phrase is: Retiremos el equipo de la cancha, Boca no merece jugar esta copa que hace tiempo viene siendo desprestigiada.
Ya no se juega al futbol.
English Phrase is: Let's remove the team from the field, Boca does not deserve to play this cup that has long been discredited. Football is no longer played.
Spanish word is: equipo, English word is: team
Spanish Description is: Type, Name, Title, Description, Game, Owner, Status, Location, Brand, Sponsor
English Description is: Type, Title, Name, Description, Game, Status, Location, Owner, Category, Brand
Overlap is: Brand, Description, Game, Location, Name, Owner, Status, Title, Type (9)
Difference is: Category, Sponsor (2)
Spanish word is: Boca, English word is: Boca
Spanish Description is: Name, Owner, Title, Type, Description, Game, Brand, Status, Location, Sponsor
English Description is: Name, Title, Type, Game, Description, Owner, Brand, Status, Sport, Sponsor
Overlap is: Brand, Description, Game, Name, Owner, Sponsor, Status, Title, Type (9)
Difference is: Location, Sport (2)
Spanish word is: copa, English word is: cup
Spanish Description is: Type, Title, Game, Description, Name, Status, Sports, Sport, Category, Theme
English Description is: Type, Title, Game, Description, Status, Name, Category, Sports, Sport, Series
Overlap is: Category, Description, Game, Name, Sport, Sports, Status, Title, Type (9)
Difference is: Series, Theme (2)
Spanish word is: tiempo, English word is: long
Spanish Description is: Description, Age, Title, Type, Game, Status, Location, Name, Rating, Year
English Description is: Title, Type, Description, Age, Status, Game, Rating, Name, Application, Country
Overlap is: Age, Description, Game, Name, Rating, Status, Title, Type (8)
Difference is: Application, Country, Location, Year (4)
Spanish word is: futbol, English word is: Football
Spanish Description is: Type, Game, Sport, Sports, Title, Description, Style, Theme, Category, Application
English Description is: Type, Game, Sport, Sports, Title, Description, Football, Category, Theme, Style
Overlap is: Category, Description, Game, Sport, Sports, Style, Theme, Title, Type (9)
Difference is: Application, Football (2)
The bass and Malibu evaluations are rather poor, however the others are good. I think that the football evaluation is very strong with really good overlap for each pair of words.
This still predicts the same few words frequently. Working on that should be the next priority.
Expanding the model size was problematic with the roberta model type. Is it still difficult?
model_path = train(
model_name="xlm-roberta-large",
batch_size=32,
learning_rate=1e-4,
temperature=2,
mean_prediction=False,
epochs=2,
evaluation_steps=1_000,
)PyTorch: setting up devices
Could not locate the tokenizer configuration file, will try to use the model config instead.
https://huggingface.co/xlm-roberta-large/resolve/main/config.json not found in cache or force_download set to True, downloading to /home/matthew/.cache/huggingface/transformers/tmpa7brcludstoring https://huggingface.co/xlm-roberta-large/resolve/main/config.json in cache at /home/matthew/.cache/huggingface/transformers/4d7a1550c9ab8701667bc307a1213c040fcc06dc87a5e4994e72aecc0d7e0337.842c7737719967568f4691849854475018d6cf7ce21f52576bb6e0d10091bd3c
creating metadata file for /home/matthew/.cache/huggingface/transformers/4d7a1550c9ab8701667bc307a1213c040fcc06dc87a5e4994e72aecc0d7e0337.842c7737719967568f4691849854475018d6cf7ce21f52576bb6e0d10091bd3c
https://huggingface.co/xlm-roberta-large/resolve/main/sentencepiece.bpe.model not found in cache or force_download set to True, downloading to /home/matthew/.cache/huggingface/transformers/tmpy2_co20istoring https://huggingface.co/xlm-roberta-large/resolve/main/sentencepiece.bpe.model in cache at /home/matthew/.cache/huggingface/transformers/dc0198bb42e28700de2a550508894cf6c5202c38c7aff44b71a055950dfc2f99.00628a9eeb8baf4080d44a0abe9fe8057893de20c7cb6e6423cddbf452f7d4d8
creating metadata file for /home/matthew/.cache/huggingface/transformers/dc0198bb42e28700de2a550508894cf6c5202c38c7aff44b71a055950dfc2f99.00628a9eeb8baf4080d44a0abe9fe8057893de20c7cb6e6423cddbf452f7d4d8
https://huggingface.co/xlm-roberta-large/resolve/main/tokenizer.json not found in cache or force_download set to True, downloading to /home/matthew/.cache/huggingface/transformers/tmpxaxm5hg6storing https://huggingface.co/xlm-roberta-large/resolve/main/tokenizer.json in cache at /home/matthew/.cache/huggingface/transformers/7766c86e10505ed9b39af34e456480399bf06e35b36b8f2b917460a2dbe94e59.a984cf52fc87644bd4a2165f1e07e0ac880272c1e82d648b4674907056912bd7
creating metadata file for /home/matthew/.cache/huggingface/transformers/7766c86e10505ed9b39af34e456480399bf06e35b36b8f2b917460a2dbe94e59.a984cf52fc87644bd4a2165f1e07e0ac880272c1e82d648b4674907056912bd7
https://huggingface.co/xlm-roberta-large/resolve/main/pytorch_model.bin not found in cache or force_download set to True, downloading to /home/matthew/.cache/huggingface/transformers/tmprwlaa7vvstoring https://huggingface.co/xlm-roberta-large/resolve/main/pytorch_model.bin in cache at /home/matthew/.cache/huggingface/transformers/4b3ca85a63804fb7cd317765d9de19ce6208ee0fc9691b209384ee7cfd9cb3b9.64b4693d874c772310b8acda9a1193cfade77d56795a9b488e612f198b68f6f7
creating metadata file for /home/matthew/.cache/huggingface/transformers/4b3ca85a63804fb7cd317765d9de19ce6208ee0fc9691b209384ee7cfd9cb3b9.64b4693d874c772310b8acda9a1193cfade77d56795a9b488e612f198b68f6f7
/home/matthew/.cache/pypoetry/virtualenvs/blog-HrtMnrOS-py3.10/lib/python3.10/site-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(| Step | Training Loss | Validation Loss | Kl Div | Overlap |
|---|---|---|---|---|
| 1000 | 0.414100 | 0.280314 | 0.324477 | 0.697068 |
| 2000 | 0.288400 | 0.266837 | 0.307255 | 0.706091 |
| 3000 | 0.247300 | 0.242339 | 0.274493 | 0.722424 |
| 4000 | 0.193700 | 0.220238 | 0.248898 | 0.739748 |
| 5000 | 0.174000 | 0.200258 | 0.225176 | 0.750093 |
| 6000 | 0.160300 | 0.187177 | 0.210261 | 0.758435 |
evaluate(model_name="xlm-roberta-large", model_path=model_path)Could not locate the tokenizer configuration file, will try to use the model config instead.=== BASS EVALUATION ===
First Phrase is: We spotted a large bass in the ocean. Target is: bass
Description is: Type, Fish, Animal, Location, Object, Item, Category, Feature, Bird, Name
Second Phrase is: The bass player did not receive the acknowledgment she deserves. Target is: bass
Description is: Profession, Job, Position, Title, Type, Jobs, Experience, Status, Work, Skill
Third Phrase is: The black sea bass, is a member of the wreckfish family. Target is: bass
Description is: Type, Animal, Category, Fish, Food, Name, Description, Family, Item, Product
First & Second: ['Type']
First & Third: ['Animal', 'Category', 'Fish', 'Item', 'Name', 'Type']
Second & Third: ['Type']
=== FRIDAY EVALUATION ===
Spanish Phrase is: Friday es mi canción favorita.
Spanish Description is: Date, Day, Tag, Time, Year, Theme, Birthday, Tags, Type, Name
English Phrase is: Friday is my favourite song.
English Description is: Date, Day, Tag, Time, Year, Birthday, Theme, Tags, Type, Name
Description Overlap is: Birthday, Date, Day, Name, Tag, Tags, Theme, Time, Type, Year
Description Difference is:
=== MALIBU EVALUATION ===
Phrase is: I like to drive my Malibu while drinking Malibu.
First Malibu (car) Description is: Type, Brand, Bike, Car, Model, Motor, Name, Style, Vehicle, Company
Second Malibu (drink) Description is: Drink, Brand, Type, Beer, Product, Food, Style, Name, Wine, Company
First & Second: ['Brand', 'Company', 'Name', 'Style', 'Type']
First ^ Second: ['Beer', 'Bike', 'Car', 'Drink', 'Food', 'Model', 'Motor', 'Product', 'Vehicle', 'Wine']
=== FOOTBALL EVALUATION ===
Spanish Phrase is: Retiremos el equipo de la cancha, Boca no merece jugar esta copa que hace tiempo viene siendo desprestigiada.
Ya no se juega al futbol.
English Phrase is: Let's remove the team from the field, Boca does not deserve to play this cup that has long been discredited. Football is no longer played.
Spanish word is: equipo, English word is: team
Spanish Description is: Type, Team, Sports, Sport, Race, Game, Category, Description, Group, Name
English Description is: Type, Team, Race, Category, Sport, Sports, Game, Description, Name, Organization
Overlap is: Category, Description, Game, Name, Race, Sport, Sports, Team, Type (9)
Difference is: Group, Organization (2)
Spanish word is: Boca, English word is: Boca
Spanish Description is: Type, Team, Sport, Name, Sports, Location, Game, Company, Race, Title
English Description is: Team, Type, Sport, Name, Sports, Game, Race, Title, Company, Location
Overlap is: Company, Game, Location, Name, Race, Sport, Sports, Team, Title, Type (10)
Difference is: (0)
Spanish word is: copa, English word is: cup
Spanish Description is: Type, Game, Sport, Sports, Title, Category, Style, Team, Games, Description
English Description is: Type, Category, Title, Game, Sport, Sports, Race, Team, Description, Event
Overlap is: Category, Description, Game, Sport, Sports, Team, Title, Type (8)
Difference is: Event, Games, Race, Style (4)
Spanish word is: tiempo, English word is: long
Spanish Description is: Type, Age, Game, Location, Sports, Date, Category, Season, Sport, Description
English Description is: Type, Age, Category, Location, Game, Season, Title, Date, Race, Sports
Overlap is: Age, Category, Date, Game, Location, Season, Sports, Type (8)
Difference is: Description, Race, Sport, Title (4)
Spanish word is: futbol, English word is: Football
Spanish Description is: Sports, Sport, Game, Team, Hobby, Type, Football, Games, Soccer, Title
English Description is: Sport, Sports, Game, Team, Type, Football, Games, Title, Hobby, Category
Overlap is: Football, Game, Games, Hobby, Sport, Sports, Team, Title, Type (9)
Difference is: Category, Soccer (2)
This is great. The same training code works on xlm-roberta-base and xlm-roberta-large, and the large model has not suffered from the collapse we saw before.
The evaluation of xlm-roberta-large also looks really positive. It is able to distinguish between the two senses of Malibu in the sentence, and the overlap for the football evaluation remains excellent. Unfortunately it does loose the sense of Friday as a song.
There are still quite a few repeating words, so using the technique to find the most frequently predicted set and then exclude them from training/evaluation would be good.