Code
import blog.transformers_loggingThe XLM-RoBERTa models appear to perform very well at this task. One thing that has not changed is the habit of over predicting some words. This post is concerned with finding the most common words for XLM-RoBERTa base and then trying to train in a way that reduces them.
import blog.transformers_loggingWe calculated the common tokens before for the RoBERTa model. The same code can be used again.
The token aggregator just runs every test row through the model and calculates the tokens that the teacher predicts. These predictions are run through softmax so they are comparable and the mean of the predictions is calculated. Tokens that tend to dominate the predictions will have a larger value than average (the average being \(\frac{1}{250,002}\) or about 0.000004).
It’s worth pointing out that every English word should have a larger value than average as we are training the model to output English tokens.
from pathlib import Path
import datasets
MODEL_NAME = "xlm-roberta-base"
DATA_FOLDER = Path("/data/tatoeba/2022-06-18/dataset")
train_ds = datasets.load_from_disk(DATA_FOLDER / "xlm-roberta-train.dataset")# from src/main/python/blog/prompt_internalization/multilingual/tokens.py
from typing import List
import numpy as np
import torch
from tqdm.auto import tqdm
from transformers import AutoModelForMaskedLM, AutoTokenizer
class PromptedFeatureAggregator:
def __init__(self, model_name: str = "xlm-roberta-base") -> None:
self.model = AutoModelForMaskedLM.from_pretrained(model_name)
self.model.eval()
self.model.cuda()
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
@torch.inference_mode()
def __call__(self, rows: List[List[int]], batch_size: int) -> np.array:
result = torch.zeros(
self.tokenizer.vocab_size,
dtype=torch.float,
device=self.model.device,
requires_grad=False,
)
for index in tqdm(range(0, len(rows), batch_size)):
batch = rows[index : index + batch_size]
result += self.infer_batch(batch)
result = result / len(rows)
return result.cpu().numpy()
@torch.inference_mode()
def infer_batch(self, rows: List[List[int]]) -> torch.Tensor:
padded_inputs = self.tokenizer.pad(
[{"input_ids": input_ids} for input_ids in rows],
padding=True,
return_tensors="pt",
)
padded_inputs = padded_inputs.to(self.model.device)
mask_index = padded_inputs.input_ids == self.tokenizer.mask_token_id
outputs = self.model(**padded_inputs)
predictions = outputs.logits[mask_index]
predictions = predictions.softmax(dim=-1)
predictions = torch.sum(predictions, dim=0)
return predictionspredictor = PromptedFeatureAggregator(model_name=MODEL_NAME)
token_weights = predictor(train_ds["teacher_input_ids"], batch_size=64)import numpy as np
np.save(DATA_FOLDER / "xlm-roberta-base-tokens.npy", token_weights)What are the most common tokens? Do they seem reasonable?
import numpy as np
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
token_weights = np.load(DATA_FOLDER / "xlm-roberta-base-tokens.npy", allow_pickle=True)top_n = np.argsort(token_weights)[::-1]
top_10 = top_n[:10]
print(
f"The top 10 tokens (of {token_weights.shape[0]:,} tokens) "
f"have {token_weights[top_10].sum():0.3f} of total probability mass"
)
for token, probability in zip(
tokenizer.batch_decode(top_10[:, None]),
token_weights[top_10],
):
print(f" {token: >11}: {probability:0.3f}")The top 10 tokens (of 250,002 tokens) have 0.366 of total probability mass
Owner: 0.107
Name: 0.065
Description: 0.048
Type: 0.035
Location: 0.029
Status: 0.024
Country: 0.017
Material: 0.015
Age: 0.014
Language: 0.012If we quickly review the output of the model trained in the previous post we can see:
First Phrase is: We spotted a large bass in the ocean. Target is: bass
Description is: Location, Description, Area, Type, Name, View, Color, Material, Position, Size
Filtering this list of tokens by the top 10 common tokens would’ve removed half of them. This is a strong output (and reviewing the output for bass I think that the model did poorly - something to look into separately).
top_p50 = top_n[token_weights[top_n].cumsum() <= 0.5]
print(
f"top {len(top_p50)} tokens (of {token_weights.shape[0]:,} tokens) "
f"have {token_weights[top_p50].sum():0.3f} of total probability mass"
)
for token, probability in zip(
tokenizer.batch_decode(top_p50[:, None]),
token_weights[top_p50],
):
print(f" {token: >11}: {probability:0.3f}")top 29 tokens (of 250,002 tokens) have 0.496 of total probability mass
Owner: 0.107
Name: 0.065
Description: 0.048
Type: 0.035
Location: 0.029
Status: 0.024
Country: 0.017
Material: 0.015
Age: 0.014
Language: 0.012
Weight: 0.011
Title: 0.009
Size: 0.009
Color: 0.009
Date: 0.007
Photo: 0.007
Tags: 0.007
Product: 0.007
Tag: 0.007
Details: 0.006
Keyword: 0.006
Position: 0.006
Address: 0.006
ID: 0.006
Contact: 0.006
Phone: 0.006
Brand: 0.005
Time: 0.005
Land: 0.005Once again reviewing this with the first output from the model:
First Phrase is: We spotted a large bass in the ocean. Target is: bass
Description is: Location, Description, Area, Type, Name, View, Color, Material, Position, Size
Filtering this list of tokens by the 0.5 total weight common tokens would’ve removed \(\frac{8}{10}\) of them. This would only leave Area and View, which are poor descriptions of a fish.
import pandas as pd
pd.Series(token_weights[top_n]).plot(logy=True) ; None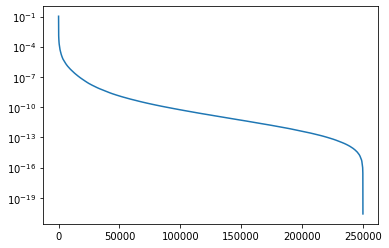
We can see that the majority of the probability mass is found in a very small number of tokens. It’s interesting that the XLM-RoBERTa base model has more probability mass assigned to these early tokens than plain RoBERTa base. You can see this because the XLM model has 5x as many tokens but fewer tokens are needed to accumulate half of the total prediction weight.
It would be good to suppress these tokens as they are predicted more than they should. These tokens are used to determine the word sense, and if the tokens are predicted too often then they lose discriminative value.
With this data I have three options:
Ideally a train time alteration would be performed as this would make inference easier later on. Any overall alteration of probability needs a little bit of care as there are tokens with extremely low probabilities which are best left alone.
We can try retraining the model with the teacher outputs altered to suppress the common tokens.
The alteration to the training code is relatively simple. A list of token ids to ignore is passed in and the values of these are set to the minimum of the output. Since this is done prior to softmax that will effectively set the value of those indices to zero.
# from src/main/python/blog/prompt_internalization/multilingual/roberta/trainer.py
from itertools import starmap
from typing import Any, Dict, List, Optional, Tuple, Union
import torch
import torch.nn.functional as F
from transformers import AutoModelForMaskedLM, AutoTokenizer, Trainer, TrainingArguments
from transformers.modeling_outputs import MaskedLMOutput
class MultilingualMaskedPromptInternalizationTrainingArguments(TrainingArguments):
def __init__(
self,
*args,
temperature: float = 2.0,
mean_prediction: bool = True,
ignore_tokens: Optional[List[int]] = None,
**kwargs,
) -> None:
super().__init__(*args, **kwargs)
self.temperature = temperature
self.mean_prediction = mean_prediction
if ignore_tokens is not None:
self.ignore_tokens = ignore_tokens
else:
self.ignore_tokens = []
class MultilingualMaskedPromptInternalizationTrainer(Trainer):
def __init__(
self,
*args,
teacher_model: AutoModelForMaskedLM = None,
tokenizer: AutoTokenizer = None,
**kwargs,
) -> None:
super().__init__(*args, **kwargs)
self.teacher = teacher_model
self._move_model_to_device(self.teacher, self.model.device)
self.teacher.eval()
self.mask_token_id = tokenizer.mask_token_id
def compute_loss(
self,
model: AutoModelForMaskedLM,
inputs: Dict[str, Union[torch.Tensor, Any]],
return_outputs: bool = False,
) -> Union[Tuple[torch.Tensor, torch.Tensor], torch.Tensor]:
outputs: MaskedLMOutput = model(
input_ids=inputs["input_ids"], attention_mask=inputs["attention_mask"]
)
if self.args.mean_prediction:
predictions = self._student_predictions_mean(
outputs=outputs, labels=inputs["labels"]
)
else:
predictions = self._student_predictions_first(
outputs=outputs, labels=inputs["labels"]
)
targets = self._teacher_predictions(
input_ids=inputs["teacher_input_ids"],
attention_mask=inputs["teacher_attention_mask"],
)
loss = self._loss(predictions=predictions, targets=targets)
if not return_outputs:
return loss
# This directly calculates the kl_div and overlap metrics.
# It's much faster to do this using CUDA operations instead of waiting for cpu numpy.
with torch.inference_mode():
kl_div = F.kl_div(
input=F.log_softmax(predictions.to(torch.float32), dim=-1),
target=F.softmax(targets.to(torch.float32), dim=-1),
reduction="none",
log_target=False,
)
kl_div = kl_div.sum(dim=1)
overlap = starmap(
torch.isin,
zip(
predictions.argsort(descending=True)[:, :10],
targets.argsort(descending=True)[:, :10],
),
)
overlap = map(torch.sum, overlap)
overlap = torch.tensor(list(overlap), device=self.model.device)
overlap = overlap / 10
# This will reshape the metrics to be [batch_size, 2] which will then
# get correctly passed to the metric calculation
metric_output = torch.cat([kl_div[:, None], overlap[:, None]], dim=1)
return loss, metric_output
@torch.inference_mode()
def _teacher_predictions(
self, input_ids: torch.Tensor, attention_mask: torch.Tensor
) -> torch.Tensor:
outputs_teacher = self.teacher(
input_ids=input_ids,
attention_mask=attention_mask,
)
mask_indices = input_ids == self.mask_token_id
teacher_predictions = outputs_teacher.logits[mask_indices]
teacher_predictions[:, self.args.ignore_tokens] = teacher_predictions.min()
return teacher_predictions
def _student_predictions_mean(
self, outputs: MaskedLMOutput, labels: torch.Tensor
) -> torch.Tensor:
# When calculating this it is very important to avoid breaking back propagation.
# torch.cat will break back propagation, so the prediction is added per row to a holder
logits = outputs.logits
predictions = torch.zeros(logits.shape[0], device=logits.device)
for index, (start, length) in enumerate(labels):
prediction = logits[index, start : start + length]
prediction = prediction.mean(dim=0)
predictions[index] += prediction
return predictions
def _student_predictions_first(
self,
outputs: MaskedLMOutput,
labels: torch.Tensor,
) -> torch.Tensor:
return outputs.logits[range(outputs.logits.shape[0]), labels[:, 0]]
def _loss(self, predictions: torch.Tensor, targets: torch.Tensor) -> torch.Tensor:
predictions = F.log_softmax(
predictions.to(torch.float32) / self.args.temperature, dim=-1
)
targets = F.softmax(targets.to(torch.float32) / self.args.temperature, dim=-1)
loss = F.kl_div(
input=predictions,
target=targets,
reduction="batchmean",
log_target=False,
)
return loss * (self.args.temperature**2)
# from src/main/python/blog/prompt_internalization/multilingual/roberta/collator.py
from typing import Any, Dict, List
from transformers import AutoTokenizer
class TeacherStudentCollator:
"""
The teacher inputs need to be padded and have an associated attention mask.
"""
def __init__(self, tokenizer: AutoTokenizer) -> None:
self.tokenizer = tokenizer
def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:
teacher_inputs = self._teacher_inputs(features)
student_inputs = self._student_inputs(features)
batch = {**teacher_inputs, **student_inputs}
if "label" in batch:
batch["labels"] = batch["label"]
del batch["label"]
if "label_ids" in batch:
batch["labels"] = batch["label_ids"]
del batch["label_ids"]
return batch
def _teacher_inputs(self, features: List[Dict[str, Any]]) -> Dict[str, List[Any]]:
teacher_inputs = [{"input_ids": row["teacher_input_ids"]} for row in features]
teacher_batch = self.tokenizer.pad(
teacher_inputs,
padding=True,
return_tensors="pt",
)
return {
"teacher_input_ids": teacher_batch["input_ids"],
"teacher_attention_mask": teacher_batch["attention_mask"],
}
def _student_inputs(self, features: List[Dict[str, Any]]) -> Dict[str, List[Any]]:
student_inputs = [
{
"input_ids": row["input_ids"],
"labels": row["labels"][0], # known to have a single entry
}
for row in features
]
return self.tokenizer.pad(
student_inputs,
padding=True,
return_tensors="pt",
)
# from src/main/python/blog/prompt_internalization/multilingual/roberta/metrics.py
from typing import Dict
from transformers import EvalPrediction
def compute_metrics(model_output: EvalPrediction) -> Dict[str, float]:
kl_div = model_output.predictions[:, 0].mean()
overlap = model_output.predictions[:, 1].mean()
return {
"kl_div": kl_div,
"overlap": overlap,
}
# from src/main/python/blog/prompt_internalization/multilingual/roberta/train.py
from pathlib import Path
from typing import List, Optional
import datasets
from transformers import AutoModelForMaskedLM, AutoTokenizer
from .collator import TeacherStudentCollator
from .metrics import compute_metrics
from .trainer import (
MultilingualMaskedPromptInternalizationTrainer,
MultilingualMaskedPromptInternalizationTrainingArguments,
)
DATASET_FOLDER = Path("/data/tatoeba/2022-06-18/dataset/")
MODEL_FOLDER = Path("/data/prompt-internalization/multilingual/")
RUN_FOLDER = Path("/tmp/runs")
MODEL_FOLDER.mkdir(parents=True, exist_ok=True)
RUN_FOLDER.mkdir(parents=True, exist_ok=True)
def train(
*,
model_name: str = "xlm-roberta-base",
dataset_name: str = "xlm-roberta",
batch_size: int = 64,
learning_rate: float = 1e-4,
temperature: float = 2,
fp16: bool = False,
mean_prediction: bool = False,
ignore_tokens: Optional[List[int]] = None,
epochs: Optional[float] = 2,
max_steps: int = -1,
evaluation_steps: int = 500,
) -> Path:
run_name = "-".join(
[
f"{model_name}",
f"e{epochs}" if max_steps == -1 else f"ms{max_steps}",
f"bs{batch_size}",
f"lr{learning_rate}",
f"t{temperature}",
]
+ (["fp16"] if fp16 else [])
+ (["mean"] if mean_prediction else [])
+ ([f"it{len(ignore_tokens)}"] if ignore_tokens else [])
)
print(f"Starting {run_name}")
train_ds = datasets.load_from_disk(DATASET_FOLDER / f"{dataset_name}-train.dataset")
test_ds = datasets.load_from_disk(DATASET_FOLDER / f"{dataset_name}-test.dataset")
training_args = MultilingualMaskedPromptInternalizationTrainingArguments(
report_to="none",
output_dir=RUN_FOLDER,
num_train_epochs=epochs,
max_steps=max_steps,
seed=33,
# number of steps before moving evaluation results from GPU to CPU see
# https://discuss.huggingface.co/t/cuda-out-of-memory-when-using-trainer-with-compute-metrics/2941
eval_accumulation_steps=5,
#
# hyperparameters
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
fp16=fp16,
temperature=temperature,
mean_prediction=mean_prediction,
ignore_tokens=ignore_tokens,
learning_rate=learning_rate,
#
# evaluation settings
evaluation_strategy="steps",
logging_steps=evaluation_steps,
eval_steps=evaluation_steps,
save_steps=evaluation_steps,
#
# checkpoint settings
logging_dir=RUN_FOLDER / "logs",
save_total_limit=2,
load_best_model_at_end=True,
metric_for_best_model="overlap",
greater_is_better=True,
remove_unused_columns=False,
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
teacher_model = AutoModelForMaskedLM.from_pretrained(model_name)
student_model = AutoModelForMaskedLM.from_pretrained(model_name)
data_collator = TeacherStudentCollator(tokenizer=tokenizer)
trainer = MultilingualMaskedPromptInternalizationTrainer(
model=student_model,
args=training_args,
teacher_model=teacher_model,
train_dataset=train_ds,
eval_dataset=test_ds,
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
student_model.save_pretrained(MODEL_FOLDER / run_name)
return MODEL_FOLDER / run_name
# from src/main/python/blog/prompt_internalization/multilingual/roberta/evaluate.py
from pathlib import Path
from typing import List, Optional, Tuple
import torch
from transformers import AutoModelForMaskedLM, AutoTokenizer
def evaluate(
model_name: str, model_path: Path, ignore_tokens: Optional[List[int]] = None
) -> None:
if ignore_tokens is None:
ignore_tokens = []
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForMaskedLM.from_pretrained(model_path)
model.eval()
bass_evaluation(model=model, tokenizer=tokenizer, ignore_tokens=ignore_tokens)
friday_evaluation(model=model, tokenizer=tokenizer, ignore_tokens=ignore_tokens)
malibu_evaluation(model=model, tokenizer=tokenizer, ignore_tokens=ignore_tokens)
football_evaluation(model=model, tokenizer=tokenizer, ignore_tokens=ignore_tokens)
def bass_evaluation(
model: AutoModelForMaskedLM, tokenizer: AutoTokenizer, ignore_tokens: List[int]
) -> None:
first_phrase = "We spotted a large bass in the ocean."
second_phrase = "The bass player did not receive the acknowledgment she deserves."
third_phrase = "The black sea bass, is a member of the wreckfish family."
first_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=first_phrase,
noun="bass",
ignore_tokens=ignore_tokens,
)
second_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=second_phrase,
noun="bass",
ignore_tokens=ignore_tokens,
)
third_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=third_phrase,
noun="bass",
ignore_tokens=ignore_tokens,
)
print("=== BASS EVALUATION ===")
print(f"First Phrase is: {first_phrase} Target is: bass")
print(f"Description is: {', '.join(first_predicted_words)}")
print()
print(f"Second Phrase is: {second_phrase} Target is: bass")
print(f"Description is: {', '.join(second_predicted_words)}")
print()
print(f"Third Phrase is: {third_phrase} Target is: bass")
print(f"Description is: {', '.join(third_predicted_words)}")
print()
print(
f"First & Second: {sorted(set(first_predicted_words) & set(second_predicted_words))}"
)
print(
f"First & Third: {sorted(set(first_predicted_words) & set(third_predicted_words))}"
)
print(
f"Second & Third: {sorted(set(second_predicted_words) & set(third_predicted_words))}"
)
print()
def friday_evaluation(
model: AutoModelForMaskedLM, tokenizer: AutoTokenizer, ignore_tokens: List[int]
) -> None:
spanish_text = "Friday es mi canción favorita."
english_text = "Friday is my favourite song."
spanish_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=spanish_text,
noun="Friday",
ignore_tokens=ignore_tokens,
)
english_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=english_text,
noun="Friday",
ignore_tokens=ignore_tokens,
)
overlap = set(spanish_predicted_words) & set(english_predicted_words)
difference = set(spanish_predicted_words) ^ set(english_predicted_words)
print("=== FRIDAY EVALUATION ===")
print(f"Spanish Phrase is: {spanish_text}")
print(f"Spanish Description is: {', '.join(spanish_predicted_words)}")
print(f"English Phrase is: {english_text}")
print(f"English Description is: {', '.join(english_predicted_words)}")
print()
print(f"Description Overlap is: {', '.join(sorted(overlap))}")
print(f"Description Difference is: {', '.join(sorted(difference))}")
print()
def malibu_evaluation(
model: AutoModelForMaskedLM, tokenizer: AutoTokenizer, ignore_tokens: List[int]
) -> None:
text = "I like to drive my Malibu while drinking Malibu."
first_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=text,
noun="Malibu",
ignore_tokens=ignore_tokens,
)
second_predicted_words = get_predictions(
model=model,
tokenizer=tokenizer,
text=text,
noun="Malibu",
index=1,
ignore_tokens=ignore_tokens,
)
print("=== MALIBU EVALUATION ===")
print(f"Phrase is: {text}")
print(f"First Malibu (car) Description is: {', '.join(first_predicted_words)}")
print(f"Second Malibu (drink) Description is: {', '.join(second_predicted_words)}")
print()
print(
f"First & Second: {sorted(set(first_predicted_words) & set(second_predicted_words))}"
)
print(
f"First ^ Second: {sorted(set(first_predicted_words) ^ set(second_predicted_words))}"
)
print()
def football_evaluation(
model: AutoModelForMaskedLM, tokenizer: AutoTokenizer, ignore_tokens: List[int]
) -> None:
spanish_phrase = (
"Retiremos el equipo de la cancha, "
"Boca no merece jugar esta copa que "
"hace tiempo viene siendo desprestigiada.\n"
"Ya no se juega al futbol."
)
english_phrase = (
"Let's remove the team from the field, "
"Boca does not deserve to play this cup that "
"has long been discredited. "
"Football is no longer played."
)
print("=== FOOTBALL EVALUATION ===")
print(f"Spanish Phrase is: {spanish_phrase}")
print(f"English Phrase is: {english_phrase}")
print()
for spanish_noun, english_noun in [
["equipo", "team"],
["Boca", "Boca"],
["copa", "cup"],
["tiempo", "long"],
["futbol", "Football"],
]:
spanish_description = get_predictions(
model=model,
tokenizer=tokenizer,
text=spanish_phrase,
noun=spanish_noun,
ignore_tokens=ignore_tokens,
)
english_description = get_predictions(
model=model,
tokenizer=tokenizer,
text=english_phrase,
noun=english_noun,
ignore_tokens=ignore_tokens,
)
overlap = set(spanish_description) & set(english_description)
difference = set(spanish_description) ^ set(english_description)
print(f"Spanish word is: {spanish_noun}, English word is: {english_noun}")
print(f"Spanish Description is: {', '.join(spanish_description)}")
print(f"English Description is: {', '.join(english_description)}")
print(f"Overlap is: {', '.join(sorted(overlap))} ({len(overlap)})")
print(f"Difference is: {', '.join(sorted(difference))} ({len(difference)})")
print()
@torch.inference_mode()
def get_predictions(
*,
model: AutoModelForMaskedLM,
tokenizer: AutoTokenizer,
text: str,
noun: str,
index: int = 0,
ignore_tokens: Optional[List[int]] = None,
) -> List[str]:
if ignore_tokens is None:
ignore_tokens = []
tokens = tokenizer(text, return_tensors="pt")
start, _end = get_noun(
tokenizer=tokenizer, tokens=tokens.input_ids[0], noun=noun, index=index
)
output = model(**tokens)
predictions = output.logits[0, start]
predictions[ignore_tokens] = predictions.min()
predicted_tokens = predictions.argsort(descending=True)[:10]
predicted_words = [
word.strip() for word in tokenizer.batch_decode(predicted_tokens)
]
return predicted_words
def get_noun(
tokenizer: AutoTokenizer, tokens: torch.Tensor, noun: str, index: int
) -> Tuple[int, int]:
length = tokens.shape[0]
current_index = index
for start_index in range(length):
word = tokenizer.decode(tokens[start_index]).strip()
if not noun.startswith(word):
continue
for end_index in range(start_index + 1, length):
word = tokenizer.decode(tokens[start_index:end_index]).strip()
if not noun == word:
continue
if current_index > 0:
current_index -= 1
else:
return start_index, end_index
raise AssertionError(f"Did not find {noun}[{index}] in {tokenizer.decode(tokens)}")We can try to train with the top .5 of tokens by weight manually minimized. This is likely to reduce the metrics during training as the task is now harder to replicate. The objective is to improve the final evaluation by providing more distinctive features for each word.
Once this is done we can evaluate this and then compare it to the regular model (trained in the previous post) with a post inference filter.
COMPARISON_MODEL = "/data/prompt-internalization/multilingual/xlm-roberta-base-e2-bs32-lr0.0001-t2"model_path = train(
model_name=MODEL_NAME,
batch_size=32,
learning_rate=1e-4,
temperature=2,
mean_prediction=False,
ignore_tokens=top_p50.tolist(),
epochs=2,
evaluation_steps=1_000,
)Starting xlm-roberta-base-e2-bs32-lr0.0001-t2-it29/home/matthew/.cache/pypoetry/virtualenvs/blog-HrtMnrOS-py3.10/lib/python3.10/site-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(| Step | Training Loss | Validation Loss | Kl Div | Overlap |
|---|---|---|---|---|
| 1000 | 0.397100 | 0.266930 | 0.252279 | 0.625872 |
| 2000 | 0.271100 | 0.240180 | 0.227941 | 0.646872 |
| 3000 | 0.239700 | 0.231941 | 0.220182 | 0.654821 |
| 4000 | 0.198700 | 0.214640 | 0.200232 | 0.669688 |
| 5000 | 0.186000 | 0.203934 | 0.192153 | 0.678712 |
| 6000 | 0.177000 | 0.197983 | 0.185556 | 0.683647 |
The comparison model achieved an overlap of 0.738468 after 6,000 steps. An overlap of 0.68 is what the comparison model achieved after 1,000 batches. This does show how much harder the task has become.
evaluate(model_name=MODEL_NAME, model_path=model_path)Could not locate the tokenizer configuration file, will try to use the model config instead.=== BASS EVALUATION ===
First Phrase is: We spotted a large bass in the ocean. Target is: bass
Description is: Area, View, Views, Cat, Application, Theme, Range, Storage, Feature, Ocean
Second Phrase is: The bass player did not receive the acknowledgment she deserves. Target is: bass
Description is: Feature, Model, Application, Item, Game, Rating, Image, Information, Service, Driver
Third Phrase is: The black sea bass, is a member of the wreckfish family. Target is: bass
Description is: Family, Animal, Cat, Group, Religion, Model, Image, Food, Company, Service
First & Second: ['Application', 'Feature']
First & Third: ['Cat']
Second & Third: ['Image', 'Model', 'Service']
=== FRIDAY EVALUATION ===
Spanish Phrase is: Friday es mi canción favorita.
Spanish Description is: Album, Theme, Music, Song, Video, Motto, Comments, Labels, Label, Category
English Phrase is: Friday is my favourite song.
English Description is: Album, Theme, Music, Song, Video, Motto, Labels, Comments, Label, Comment
Description Overlap is: Album, Comments, Label, Labels, Motto, Music, Song, Theme, Video
Description Difference is: Category, Comment
=== MALIBU EVALUATION ===
Phrase is: I like to drive my Malibu while drinking Malibu.
First Malibu (car) Description is: Food, Theme, Cat, Style, Motor, Animal, Drink, Tip, Category, Application
Second Malibu (drink) Description is: Food, Drink, Aroma, Theme, Wine, Music, Cat, Style, Animal, Tip
First & Second: ['Animal', 'Cat', 'Drink', 'Food', 'Style', 'Theme', 'Tip']
First ^ Second: ['Application', 'Aroma', 'Category', 'Motor', 'Music', 'Wine']
=== FOOTBALL EVALUATION ===
Spanish Phrase is: Retiremos el equipo de la cancha, Boca no merece jugar esta copa que hace tiempo viene siendo desprestigiada.
Ya no se juega al futbol.
English Phrase is: Let's remove the team from the field, Boca does not deserve to play this cup that has long been discredited. Football is no longer played.
Spanish word is: equipo, English word is: team
Spanish Description is: Game, Sponsor, Rating, Logo, Organization, Team, Theme, Application, Category, Company
English Description is: Game, Theme, Sponsor, Application, Sport, Category, Sports, Organization, Logo, Team
Overlap is: Application, Category, Game, Logo, Organization, Sponsor, Team, Theme (8)
Difference is: Company, Rating, Sport, Sports (4)
Spanish word is: Boca, English word is: Boca
Spanish Description is: Game, Sponsor, Company, Team, Logo, Organization, Sport, Theme, Sports, Application
English Description is: Game, Sport, Sports, Sponsor, Theme, Company, Team, Application, Organization, Logo
Overlap is: Application, Company, Game, Logo, Organization, Sponsor, Sport, Sports, Team, Theme (10)
Difference is: (0)
Spanish word is: copa, English word is: cup
Spanish Description is: Game, Sports, Theme, Sport, Category, Series, Application, Style, Games, Football
English Description is: Game, Sports, Sport, Category, Theme, Series, Application, Football, Style, Games
Overlap is: Application, Category, Football, Game, Games, Series, Sport, Sports, Style, Theme (10)
Difference is: (0)
Spanish word is: tiempo, English word is: long
Spanish Description is: Game, Rating, Year, Series, Application, Games, Category, Style, Race, Sports
English Description is: Game, Sport, Application, Series, Sports, Games, Category, Rating, Theme, Style
Overlap is: Application, Category, Game, Games, Rating, Series, Sports, Style (8)
Difference is: Race, Sport, Theme, Year (4)
Spanish word is: futbol, English word is: Football
Spanish Description is: Game, Sport, Sports, Style, Theme, Football, Games, Application, Category, Series
English Description is: Sport, Game, Sports, Football, Theme, Style, Category, Application, Games, Series
Overlap is: Application, Category, Football, Game, Games, Series, Sport, Sports, Style, Theme (10)
Difference is: (0)
evaluate(
model_name=MODEL_NAME,
model_path=COMPARISON_MODEL,
ignore_tokens=top_p50.tolist(),
)=== BASS EVALUATION ===
First Phrase is: We spotted a large bass in the ocean. Target is: bass
Description is: Area, View, Views, Theme, Cat, Application, Source, Ocean, Weather, Range
Second Phrase is: The bass player did not receive the acknowledgment she deserves. Target is: bass
Description is: Application, Item, Feature, Rating, Information, Service, Model, Driver, Image, Comment
Third Phrase is: The black sea bass, is a member of the wreckfish family. Target is: bass
Description is: Family, Animal, Cat, Category, Group, Food, Subject, Race, Gen, Service
First & Second: ['Application']
First & Third: ['Cat']
Second & Third: ['Service']
=== FRIDAY EVALUATION ===
Spanish Phrase is: Friday es mi canción favorita.
Spanish Description is: Album, Theme, Music, Song, Video, Comments, Labels, Comment, Label, Motto
English Phrase is: Friday is my favourite song.
English Description is: Album, Theme, Song, Music, Video, Labels, Comments, Label, Motto, Category
Description Overlap is: Album, Comments, Label, Labels, Motto, Music, Song, Theme, Video
Description Difference is: Category, Comment
=== MALIBU EVALUATION ===
Phrase is: I like to drive my Malibu while drinking Malibu.
First Malibu (car) Description is: Food, Aroma, Cat, Theme, Style, Animal, Plant, Tip, Drink, Application
Second Malibu (drink) Description is: Food, Aroma, Drink, Wine, Theme, Fruit, Snack, Cat, Plant, Recipe
First & Second: ['Aroma', 'Cat', 'Drink', 'Food', 'Plant', 'Theme']
First ^ Second: ['Animal', 'Application', 'Fruit', 'Recipe', 'Snack', 'Style', 'Tip', 'Wine']
=== FOOTBALL EVALUATION ===
Spanish Phrase is: Retiremos el equipo de la cancha, Boca no merece jugar esta copa que hace tiempo viene siendo desprestigiada.
Ya no se juega al futbol.
English Phrase is: Let's remove the team from the field, Boca does not deserve to play this cup that has long been discredited. Football is no longer played.
Spanish word is: equipo, English word is: team
Spanish Description is: Game, Sponsor, Rating, Organization, Theme, Team, Category, Sport, Application, Logo
English Description is: Game, Category, Organization, Sponsor, Sport, Application, Sports, Theme, Team, Rating
Overlap is: Application, Category, Game, Organization, Rating, Sponsor, Sport, Team, Theme (9)
Difference is: Logo, Sports (2)
Spanish word is: Boca, English word is: Boca
Spanish Description is: Game, Sponsor, Company, Organization, Team, Sport, Logo, Family, Theme, Sports
English Description is: Game, Sport, Sponsor, Sports, Organization, Company, Application, Theme, Category, Team
Overlap is: Company, Game, Organization, Sponsor, Sport, Sports, Team, Theme (8)
Difference is: Application, Category, Family, Logo (4)
Spanish word is: copa, English word is: cup
Spanish Description is: Game, Sports, Sport, Category, Theme, Series, Application, Style, Games, Race
English Description is: Game, Category, Sports, Sport, Series, Application, Theme, Football, Sponsor, Organization
Overlap is: Application, Category, Game, Series, Sport, Sports, Theme (7)
Difference is: Football, Games, Organization, Race, Sponsor, Style (6)
Spanish word is: tiempo, English word is: long
Spanish Description is: Game, Rating, Year, Application, Series, Race, Category, Games, Sport, Sports
English Description is: Game, Rating, Application, Year, Series, Category, Sport, Organization, Race, Games
Overlap is: Application, Category, Game, Games, Race, Rating, Series, Sport, Year (9)
Difference is: Organization, Sports (2)
Spanish word is: futbol, English word is: Football
Spanish Description is: Game, Sport, Sports, Style, Theme, Category, Application, Football, Games, Series
English Description is: Game, Sport, Sports, Football, Category, Theme, Style, Application, Series, Games
Overlap is: Application, Category, Football, Game, Games, Series, Sport, Sports, Style, Theme (10)
Difference is: (0)
When looking at these results I see:
Now we can try training with the exclusion of the top 10 tokens and then compare that to a post inference filter.
model_path = train(
model_name=MODEL_NAME,
batch_size=32,
learning_rate=1e-4,
temperature=2,
mean_prediction=False,
ignore_tokens=top_10.tolist(),
epochs=2,
evaluation_steps=1_000,
)PyTorch: setting up devicesStarting xlm-roberta-base-e2-bs32-lr0.0001-t2-it10Could not locate the tokenizer configuration file, will try to use the model config instead.
/home/matthew/.cache/pypoetry/virtualenvs/blog-HrtMnrOS-py3.10/lib/python3.10/site-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(| Step | Training Loss | Validation Loss | Kl Div | Overlap |
|---|---|---|---|---|
| 1000 | 0.399800 | 0.272879 | 0.260504 | 0.631096 |
| 2000 | 0.273100 | 0.242890 | 0.234546 | 0.650857 |
| 3000 | 0.242300 | 0.234110 | 0.226200 | 0.662668 |
| 4000 | 0.200200 | 0.217349 | 0.206719 | 0.675841 |
| 5000 | 0.187900 | 0.208354 | 0.200929 | 0.682903 |
| 6000 | 0.178600 | 0.201711 | 0.192253 | 0.688581 |
This is a marginal improvement to the overlap metric compared to the .5 model. I am not surprised by this as we are now altering a smaller part of the model output.
evaluate(model_name=MODEL_NAME, model_path=model_path)Could not locate the tokenizer configuration file, will try to use the model config instead.=== BASS EVALUATION ===
First Phrase is: We spotted a large bass in the ocean. Target is: bass
Description is: Area, Color, View, Size, Land, Position, Views, Ocean, Cat, Theme
Second Phrase is: The bass player did not receive the acknowledgment she deserves. Target is: bass
Description is: Title, Details, Position, Feature, Application, Item, Model, Rating, Game, Brand
Third Phrase is: The black sea bass, is a member of the wreckfish family. Target is: bass
Description is: Family, Animal, Color, Cat, Title, Race, Subject, Group, Product, Food
First & Second: ['Position']
First & Third: ['Cat', 'Color']
Second & Third: ['Title']
=== FRIDAY EVALUATION ===
Spanish Phrase is: Friday es mi canción favorita.
Spanish Description is: Album, Tag, Tags, Title, Theme, Song, Music, Keyword, Video, Motto
English Phrase is: Friday is my favourite song.
English Description is: Album, Tag, Tags, Title, Theme, Song, Music, Motto, Keyword, Video
Description Overlap is: Album, Keyword, Motto, Music, Song, Tag, Tags, Theme, Title, Video
Description Difference is:
=== MALIBU EVALUATION ===
Phrase is: I like to drive my Malibu while drinking Malibu.
First Malibu (car) Description is: Food, Product, Brand, Color, Aroma, Animal, Plant, Cat, Land, Root
Second Malibu (drink) Description is: Food, Aroma, Product, Drink, Color, Brand, Wine, Plant, Snack, Animal
First & Second: ['Animal', 'Aroma', 'Brand', 'Color', 'Food', 'Plant', 'Product']
First ^ Second: ['Cat', 'Drink', 'Land', 'Root', 'Snack', 'Wine']
=== FOOTBALL EVALUATION ===
Spanish Phrase is: Retiremos el equipo de la cancha, Boca no merece jugar esta copa que hace tiempo viene siendo desprestigiada.
Ya no se juega al futbol.
English Phrase is: Let's remove the team from the field, Boca does not deserve to play this cup that has long been discredited. Football is no longer played.
Spanish word is: equipo, English word is: team
Spanish Description is: Title, Game, Organization, Brand, Sponsor, Team, Theme, Application, Sports, Sport
English Description is: Title, Game, Brand, Sponsor, Organization, Logo, Team, Category, Theme, Application
Overlap is: Application, Brand, Game, Organization, Sponsor, Team, Theme, Title (8)
Difference is: Category, Logo, Sport, Sports (4)
Spanish word is: Boca, English word is: Boca
Spanish Description is: Title, Game, Brand, Sponsor, Organization, Company, Team, Sport, Color, Sports
English Description is: Title, Game, Brand, Sponsor, Sports, Company, Sport, Organization, Theme, Tag
Overlap is: Brand, Company, Game, Organization, Sponsor, Sport, Sports, Title (8)
Difference is: Color, Tag, Team, Theme (4)
Spanish word is: copa, English word is: cup
Spanish Description is: Title, Game, Sports, Category, Theme, Sport, Series, Application, Sponsor, Football
English Description is: Title, Game, Sports, Category, Sport, Series, Theme, Application, Brand, Football
Overlap is: Application, Category, Football, Game, Series, Sport, Sports, Theme, Title (9)
Difference is: Brand, Sponsor (2)
Spanish word is: tiempo, English word is: long
Spanish Description is: Title, Game, Rating, Year, Series, Application, Sport, Sports, Category, Color
English Description is: Title, Game, Brand, Rating, Application, Color, Year, Series, Organization, Sport
Overlap is: Application, Color, Game, Rating, Series, Sport, Title, Year (8)
Difference is: Brand, Category, Organization, Sports (4)
Spanish word is: futbol, English word is: Football
Spanish Description is: Sport, Sports, Game, Title, Style, Theme, Application, Football, Category, Series
English Description is: Sports, Sport, Game, Title, Theme, Football, Style, Category, Application, Series
Overlap is: Application, Category, Football, Game, Series, Sport, Sports, Style, Theme, Title (10)
Difference is: (0)
evaluate(
model_name="xlm-roberta-base",
model_path=COMPARISON_MODEL,
ignore_tokens=top_10.tolist(),
)=== BASS EVALUATION ===
First Phrase is: We spotted a large bass in the ocean. Target is: bass
Description is: Area, View, Color, Position, Size, Views, Land, Theme, Cat, Title
Second Phrase is: The bass player did not receive the acknowledgment she deserves. Target is: bass
Description is: Title, Position, Details, Application, Item, Feature, Rating, Contact, Information, Photo
Third Phrase is: The black sea bass, is a member of the wreckfish family. Target is: bass
Description is: Family, Animal, Color, Cat, Title, Category, Product, Group, Food, Subject
First & Second: ['Position', 'Title']
First & Third: ['Cat', 'Color', 'Title']
Second & Third: ['Title']
=== FRIDAY EVALUATION ===
Spanish Phrase is: Friday es mi canción favorita.
Spanish Description is: Album, Title, Tags, Tag, Theme, Music, Song, Keyword, Video, Comments
English Phrase is: Friday is my favourite song.
English Description is: Album, Title, Tag, Tags, Theme, Song, Music, Keyword, Video, Labels
Description Overlap is: Album, Keyword, Music, Song, Tag, Tags, Theme, Title, Video
Description Difference is: Comments, Labels
=== MALIBU EVALUATION ===
Phrase is: I like to drive my Malibu while drinking Malibu.
First Malibu (car) Description is: Food, Color, Aroma, Product, Cat, Theme, Style, Brand, Animal, Plant
Second Malibu (drink) Description is: Food, Aroma, Color, Drink, Wine, Product, Theme, Fruit, Snack, Cat
First & Second: ['Aroma', 'Cat', 'Color', 'Food', 'Product', 'Theme']
First ^ Second: ['Animal', 'Brand', 'Drink', 'Fruit', 'Plant', 'Snack', 'Style', 'Wine']
=== FOOTBALL EVALUATION ===
Spanish Phrase is: Retiremos el equipo de la cancha, Boca no merece jugar esta copa que hace tiempo viene siendo desprestigiada.
Ya no se juega al futbol.
English Phrase is: Let's remove the team from the field, Boca does not deserve to play this cup that has long been discredited. Football is no longer played.
Spanish word is: equipo, English word is: team
Spanish Description is: Title, Game, Brand, Sponsor, Rating, Organization, Theme, Team, Color, Category
English Description is: Title, Game, Category, Brand, Organization, Sponsor, Sport, Application, Sports, Theme
Overlap is: Brand, Category, Game, Organization, Sponsor, Theme, Title (7)
Difference is: Application, Color, Rating, Sport, Sports, Team (6)
Spanish word is: Boca, English word is: Boca
Spanish Description is: Title, Game, Brand, Sponsor, Color, Company, Tag, Organization, Team, Sport
English Description is: Title, Game, Brand, Sport, Sponsor, Sports, Organization, Company, Color, Tag
Overlap is: Brand, Color, Company, Game, Organization, Sponsor, Sport, Tag, Title (9)
Difference is: Sports, Team (2)
Spanish word is: copa, English word is: cup
Spanish Description is: Title, Game, Sports, Sport, Category, Theme, Series, Application, Tag, Brand
English Description is: Title, Game, Category, Sports, Sport, Series, Application, Theme, Brand, Football
Overlap is: Application, Brand, Category, Game, Series, Sport, Sports, Theme, Title (9)
Difference is: Football, Tag (2)
Spanish word is: tiempo, English word is: long
Spanish Description is: Title, Game, Rating, Year, Application, Series, Color, Race, Size, Category
English Description is: Title, Game, Rating, Application, Year, Series, Category, Brand, Sport, Color
Overlap is: Application, Category, Color, Game, Rating, Series, Title, Year (8)
Difference is: Brand, Race, Size, Sport (4)
Spanish word is: futbol, English word is: Football
Spanish Description is: Game, Sport, Sports, Title, Style, Theme, Category, Application, Football, Games
English Description is: Game, Sport, Sports, Title, Football, Category, Theme, Style, Application, Series
Overlap is: Application, Category, Football, Game, Sport, Sports, Style, Theme, Title (9)
Difference is: Games, Series (2)
When looking at these results I see:
How does the large model perform with these alterations?
The first thing is to recalculate the common tokens for this model. We can’t use the original tokens as they do not reflect the bias that the larger model has.
predictor = PromptedFeatureAggregator(model_name="xlm-roberta-large")
token_weights = predictor(train_ds["teacher_input_ids"], batch_size=64)import numpy as np
np.save(DATA_FOLDER / "xlm-roberta-large-tokens.npy", token_weights)We can review these in the same way to see how they differ.
import numpy as np
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("xlm-roberta-large")
token_weights = np.load(DATA_FOLDER / "xlm-roberta-large-tokens.npy", allow_pickle=True)top_n = np.argsort(token_weights)[::-1]
top_10 = top_n[:10]
print(
f"The top 10 tokens (of {token_weights.shape[0]:,} tokens) "
f"have {token_weights[top_10].sum():0.3f} of total probability mass"
)
for token, probability in zip(
tokenizer.batch_decode(top_10[:, None]),
token_weights[top_10],
):
print(f" {token: >11}: {probability:0.3f}")The top 10 tokens (of 250,002 tokens) have 0.371 of total probability mass
Name: 0.122
Type: 0.062
Owner: 0.046
Location: 0.045
Age: 0.023
Description: 0.016
Date: 0.014
Category: 0.014
Title: 0.014
Status: 0.013top_p50 = top_n[token_weights[top_n].cumsum() <= 0.5]
print(
f"top {len(top_p50)} tokens (of {token_weights.shape[0]:,} tokens) "
f"have {token_weights[top_p50].sum():0.3f} of total probability mass"
)
for token, probability in zip(
tokenizer.batch_decode(top_p50[:, None]),
token_weights[top_p50],
):
print(f" {token: >11}: {probability:0.3f}")top 23 tokens (of 250,002 tokens) have 0.497 of total probability mass
Name: 0.122
Type: 0.062
Owner: 0.046
Location: 0.045
Age: 0.023
Description: 0.016
Date: 0.014
Category: 0.014
Title: 0.014
Status: 0.013
Other: 0.012
Author: 0.012
Language: 0.012
Item: 0.011
Product: 0.011
Job: 0.010
Place: 0.010
Time: 0.009
Price: 0.009
Tags: 0.008
Service: 0.008
Country: 0.007
Material: 0.007import pandas as pd
pd.Series(token_weights[top_n]).plot(logy=True) ; None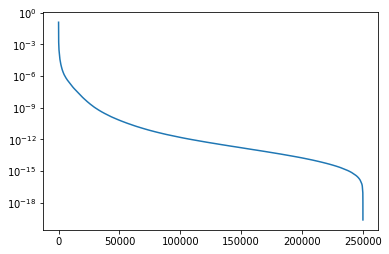
The most notable difference is that the larger model is more confident in it’s predictions, leading to a higher token weight. Instead of 29 tokens taking up half of the weight, we now have 23.
With the common tokens we can try training the model with the exclusions and comparing that to a post inference filter. Once again we will be comparing to the model that was trained in the previous post.
COMPARISON_LARGE_MODEL = "/data/prompt-internalization/multilingual/xlm-roberta-large-e2-bs32-lr0.0001-t2"model_path = train(
model_name="xlm-roberta-large",
batch_size=32,
learning_rate=1e-4,
temperature=2,
mean_prediction=False,
ignore_tokens=top_p50.tolist(),
epochs=2,
evaluation_steps=1_000,
)Starting xlm-roberta-large-e2-bs32-lr0.0001-t2-it23/home/matthew/.cache/pypoetry/virtualenvs/blog-HrtMnrOS-py3.10/lib/python3.10/site-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(| Step | Training Loss | Validation Loss | Kl Div | Overlap |
|---|---|---|---|---|
| 1000 | 1.075600 | 0.994239 | 1.282448 | 0.194869 |
| 2000 | 1.016800 | 0.985928 | 1.270552 | 0.202960 |
| 3000 | 1.006100 | 0.987125 | 1.275717 | 0.188642 |
| 4000 | 1.002900 | 0.984260 | 1.271753 | 0.205336 |
| 5000 | 1.007200 | 0.982975 | 1.270018 | 0.215388 |
| 6000 | 1.004500 | 0.980833 | 1.267651 | 0.205336 |
These training results are terrible. If the model is consistent with these metrics then it will be incomparably worse than the one trained without alteration. These overlap scores are consistent with a model that has collapsed to a fixed set of outputs.
evaluate(
model_name="xlm-roberta-large",
model_path=model_path,
)Could not locate the tokenizer configuration file, will try to use the model config instead.=== BASS EVALUATION ===
First Phrase is: We spotted a large bass in the ocean. Target is: bass
Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
Second Phrase is: The bass player did not receive the acknowledgment she deserves. Target is: bass
Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
Third Phrase is: The black sea bass, is a member of the wreckfish family. Target is: bass
Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
First & Second: ['Address', 'Color', 'Family', 'Model', 'Phone', 'Photo', 'Position', 'Size', 'Style', 'Subject']
First & Third: ['Address', 'Color', 'Family', 'Model', 'Phone', 'Photo', 'Position', 'Size', 'Style', 'Subject']
Second & Third: ['Address', 'Color', 'Family', 'Model', 'Phone', 'Photo', 'Position', 'Size', 'Style', 'Subject']
=== FRIDAY EVALUATION ===
Spanish Phrase is: Friday es mi canción favorita.
Spanish Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
English Phrase is: Friday is my favourite song.
English Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
Description Overlap is: Address, Color, Family, Model, Phone, Photo, Position, Size, Style, Subject
Description Difference is:
=== MALIBU EVALUATION ===
Phrase is: I like to drive my Malibu while drinking Malibu.
First Malibu (car) Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
Second Malibu (drink) Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
First & Second: ['Address', 'Color', 'Family', 'Model', 'Phone', 'Photo', 'Position', 'Size', 'Style', 'Subject']
First ^ Second: []
=== FOOTBALL EVALUATION ===
Spanish Phrase is: Retiremos el equipo de la cancha, Boca no merece jugar esta copa que hace tiempo viene siendo desprestigiada.
Ya no se juega al futbol.
English Phrase is: Let's remove the team from the field, Boca does not deserve to play this cup that has long been discredited. Football is no longer played.
Spanish word is: equipo, English word is: team
Spanish Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
English Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
Overlap is: Address, Color, Family, Model, Phone, Photo, Position, Size, Style, Subject (10)
Difference is: (0)
Spanish word is: Boca, English word is: Boca
Spanish Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
English Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
Overlap is: Address, Color, Family, Model, Phone, Photo, Position, Size, Style, Subject (10)
Difference is: (0)
Spanish word is: copa, English word is: cup
Spanish Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
English Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
Overlap is: Address, Color, Family, Model, Phone, Photo, Position, Size, Style, Subject (10)
Difference is: (0)
Spanish word is: tiempo, English word is: long
Spanish Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
English Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
Overlap is: Address, Color, Family, Model, Phone, Photo, Position, Size, Style, Subject (10)
Difference is: (0)
Spanish word is: futbol, English word is: Football
Spanish Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
English Description is: Model, Color, Size, Subject, Position, Phone, Style, Photo, Address, Family
Overlap is: Address, Color, Family, Model, Phone, Photo, Position, Size, Style, Subject (10)
Difference is: (0)
Sure enough the model has collapsed.
evaluate(
model_name="xlm-roberta-large",
model_path=COMPARISON_LARGE_MODEL,
ignore_tokens=top_p50.tolist(),
)=== BASS EVALUATION ===
First Phrase is: We spotted a large bass in the ocean. Target is: bass
Description is: Fish, Animal, Object, Feature, Bird, Subject, Size, Game, Food, Color
Second Phrase is: The bass player did not receive the acknowledgment she deserves. Target is: bass
Description is: Profession, Position, Jobs, Experience, Work, Skill, Industry, Professional, Hobby, Artist
Third Phrase is: The black sea bass, is a member of the wreckfish family. Target is: bass
Description is: Animal, Fish, Food, Family, Cat, Race, Game, Group, Brand, Art
First & Second: []
First & Third: ['Animal', 'Fish', 'Food', 'Game']
Second & Third: []
=== FRIDAY EVALUATION ===
Spanish Phrase is: Friday es mi canción favorita.
Spanish Description is: Day, Tag, Year, Theme, Birthday, Today, Holiday, Season, Days, Topic
English Phrase is: Friday is my favourite song.
English Description is: Day, Tag, Year, Birthday, Theme, Holiday, Today, Season, Days, Event
Description Overlap is: Birthday, Day, Days, Holiday, Season, Tag, Theme, Today, Year
Description Difference is: Event, Topic
=== MALIBU EVALUATION ===
Phrase is: I like to drive my Malibu while drinking Malibu.
First Malibu (car) Description is: Brand, Bike, Car, Model, Motor, Style, Vehicle, Company, Truck, Business
Second Malibu (drink) Description is: Drink, Brand, Beer, Food, Style, Wine, Company, Bike, Music, Car
First & Second: ['Bike', 'Brand', 'Car', 'Company', 'Style']
First ^ Second: ['Beer', 'Business', 'Drink', 'Food', 'Model', 'Motor', 'Music', 'Truck', 'Vehicle', 'Wine']
=== FOOTBALL EVALUATION ===
Spanish Phrase is: Retiremos el equipo de la cancha, Boca no merece jugar esta copa que hace tiempo viene siendo desprestigiada.
Ya no se juega al futbol.
English Phrase is: Let's remove the team from the field, Boca does not deserve to play this cup that has long been discredited. Football is no longer played.
Spanish word is: equipo, English word is: team
Spanish Description is: Team, Sports, Sport, Race, Game, Group, Organization, Style, Company, Player
English Description is: Team, Race, Sport, Sports, Game, Organization, Group, Style, Company, Position
Overlap is: Company, Game, Group, Organization, Race, Sport, Sports, Style, Team (9)
Difference is: Player, Position (2)
Spanish word is: Boca, English word is: Boca
Spanish Description is: Team, Sport, Sports, Game, Company, Race, City, State, Organization, Brand
English Description is: Team, Sport, Sports, Game, Race, Company, Organization, State, Brand, League
Overlap is: Brand, Company, Game, Organization, Race, Sport, Sports, State, Team (9)
Difference is: City, League (2)
Spanish word is: copa, English word is: cup
Spanish Description is: Game, Sport, Sports, Style, Team, Games, Race, Action, Company, Hobby
English Description is: Game, Sport, Sports, Race, Team, Event, League, Style, Form, Categories
Overlap is: Game, Race, Sport, Sports, Style, Team (6)
Difference is: Action, Categories, Company, Event, Form, Games, Hobby, League (8)
Spanish word is: tiempo, English word is: long
Spanish Description is: Game, Sports, Season, Sport, Race, Event, Size, Style, Action, Team
English Description is: Game, Season, Race, Sports, Sport, Event, Team, Size, Year, Position
Overlap is: Event, Game, Race, Season, Size, Sport, Sports, Team (8)
Difference is: Action, Position, Style, Year (4)
Spanish word is: futbol, English word is: Football
Spanish Description is: Sports, Sport, Game, Team, Hobby, Football, Games, Soccer, Action, Style
English Description is: Sport, Sports, Game, Team, Football, Games, Hobby, Soccer, League, Race
Overlap is: Football, Game, Games, Hobby, Soccer, Sport, Sports, Team (8)
Difference is: Action, League, Race, Style (4)
The comparison of the two approaches is pointless. Training XLM-RoBERTa with the token alteration completely breaks the model.
Using the post inference token filter does seem like a strong choice. Fish even turns up in the top two tokens for the fish version of bass. The large model does lose the song sense of Friday though.
Unfortunately there are still signs of model collapse, as a review of the tiempo/long output shows.
For completeness more than anything, this is almost certain to be awful.
model_path = train(
model_name="xlm-roberta-large",
batch_size=32,
learning_rate=1e-4,
temperature=2,
mean_prediction=False,
ignore_tokens=top_10.tolist(),
epochs=2,
evaluation_steps=1_000,
)PyTorch: setting up devicesStarting xlm-roberta-large-e2-bs32-lr0.0001-t2-it10Could not locate the tokenizer configuration file, will try to use the model config instead.
/home/matthew/.cache/pypoetry/virtualenvs/blog-HrtMnrOS-py3.10/lib/python3.10/site-packages/transformers/optimization.py:306: FutureWarning: This implementation of AdamW is deprecated and will be removed in a future version. Use the PyTorch implementation torch.optim.AdamW instead, or set `no_deprecation_warning=True` to disable this warning
warnings.warn(| Step | Training Loss | Validation Loss | Kl Div | Overlap |
|---|---|---|---|---|
| 1000 | 1.110600 | 1.047299 | 1.346683 | 0.187260 |
| 2000 | 1.065600 | 1.037303 | 1.333630 | 0.192484 |
| 3000 | 1.054000 | 1.035281 | 1.337833 | 0.191517 |
| 4000 | 1.051000 | 1.030929 | 1.328986 | 0.212905 |
| 5000 | 1.055000 | 1.030358 | 1.328421 | 0.211345 |
| 6000 | 1.052700 | 1.028577 | 1.327474 | 0.207088 |
The Kullback-Leibler divergence is even worse for this model which surprises me as the change to the model is relatively smaller. Since it appears to have collapsed maybe the now-unchanged tokens contribute to this.
evaluate(
model_name="xlm-roberta-large",
model_path=model_path,
)Could not locate the tokenizer configuration file, will try to use the model config instead.=== BASS EVALUATION ===
First Phrase is: We spotted a large bass in the ocean. Target is: bass
Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
Second Phrase is: The bass player did not receive the acknowledgment she deserves. Target is: bass
Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
Third Phrase is: The black sea bass, is a member of the wreckfish family. Target is: bass
Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
First & Second: ['Author', 'Country', 'Item', 'Model', 'Other', 'Place', 'Price', 'Product', 'Service', 'Tags']
First & Third: ['Author', 'Country', 'Item', 'Model', 'Other', 'Place', 'Price', 'Product', 'Service', 'Tags']
Second & Third: ['Author', 'Country', 'Item', 'Model', 'Other', 'Place', 'Price', 'Product', 'Service', 'Tags']
=== FRIDAY EVALUATION ===
Spanish Phrase is: Friday es mi canción favorita.
Spanish Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
English Phrase is: Friday is my favourite song.
English Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
Description Overlap is: Author, Country, Item, Model, Other, Place, Price, Product, Service, Tags
Description Difference is:
=== MALIBU EVALUATION ===
Phrase is: I like to drive my Malibu while drinking Malibu.
First Malibu (car) Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
Second Malibu (drink) Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
First & Second: ['Author', 'Country', 'Item', 'Model', 'Other', 'Place', 'Price', 'Product', 'Service', 'Tags']
First ^ Second: []
=== FOOTBALL EVALUATION ===
Spanish Phrase is: Retiremos el equipo de la cancha, Boca no merece jugar esta copa que hace tiempo viene siendo desprestigiada.
Ya no se juega al futbol.
English Phrase is: Let's remove the team from the field, Boca does not deserve to play this cup that has long been discredited. Football is no longer played.
Spanish word is: equipo, English word is: team
Spanish Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
English Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
Overlap is: Author, Country, Item, Model, Other, Place, Price, Product, Service, Tags (10)
Difference is: (0)
Spanish word is: Boca, English word is: Boca
Spanish Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
English Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
Overlap is: Author, Country, Item, Model, Other, Place, Price, Product, Service, Tags (10)
Difference is: (0)
Spanish word is: copa, English word is: cup
Spanish Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
English Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
Overlap is: Author, Country, Item, Model, Other, Place, Price, Product, Service, Tags (10)
Difference is: (0)
Spanish word is: tiempo, English word is: long
Spanish Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
English Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
Overlap is: Author, Country, Item, Model, Other, Place, Price, Product, Service, Tags (10)
Difference is: (0)
Spanish word is: futbol, English word is: Football
Spanish Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
English Description is: Other, Author, Product, Service, Place, Tags, Model, Item, Price, Country
Overlap is: Author, Country, Item, Model, Other, Place, Price, Product, Service, Tags (10)
Difference is: (0)
Another collapsed model.
evaluate(
model_name="xlm-roberta-large",
model_path=COMPARISON_LARGE_MODEL,
ignore_tokens=top_10.tolist(),
)=== BASS EVALUATION ===
First Phrase is: We spotted a large bass in the ocean. Target is: bass
Description is: Fish, Animal, Object, Item, Feature, Bird, Subject, Size, Material, Place
Second Phrase is: The bass player did not receive the acknowledgment she deserves. Target is: bass
Description is: Profession, Job, Position, Jobs, Experience, Work, Skill, Industry, Professional, Service
Third Phrase is: The black sea bass, is a member of the wreckfish family. Target is: bass
Description is: Animal, Fish, Food, Family, Item, Product, Cat, Race, Game, Group
First & Second: []
First & Third: ['Animal', 'Fish', 'Item']
Second & Third: []
=== FRIDAY EVALUATION ===
Spanish Phrase is: Friday es mi canción favorita.
Spanish Description is: Day, Tag, Time, Year, Theme, Birthday, Tags, Today, Holiday, Season
English Phrase is: Friday is my favourite song.
English Description is: Day, Tag, Time, Year, Birthday, Theme, Tags, Holiday, Today, Season
Description Overlap is: Birthday, Day, Holiday, Season, Tag, Tags, Theme, Time, Today, Year
Description Difference is:
=== MALIBU EVALUATION ===
Phrase is: I like to drive my Malibu while drinking Malibu.
First Malibu (car) Description is: Brand, Bike, Car, Model, Motor, Style, Vehicle, Company, Truck, Business
Second Malibu (drink) Description is: Drink, Brand, Beer, Product, Food, Style, Wine, Company, Bike, Service
First & Second: ['Bike', 'Brand', 'Company', 'Style']
First ^ Second: ['Beer', 'Business', 'Car', 'Drink', 'Food', 'Model', 'Motor', 'Product', 'Service', 'Truck', 'Vehicle', 'Wine']
=== FOOTBALL EVALUATION ===
Spanish Phrase is: Retiremos el equipo de la cancha, Boca no merece jugar esta copa que hace tiempo viene siendo desprestigiada.
Ya no se juega al futbol.
English Phrase is: Let's remove the team from the field, Boca does not deserve to play this cup that has long been discredited. Football is no longer played.
Spanish word is: equipo, English word is: team
Spanish Description is: Team, Sports, Sport, Race, Game, Group, Organization, Style, Company, Player
English Description is: Team, Race, Sport, Sports, Game, Organization, Group, Style, Company, Position
Overlap is: Company, Game, Group, Organization, Race, Sport, Sports, Style, Team (9)
Difference is: Player, Position (2)
Spanish word is: Boca, English word is: Boca
Spanish Description is: Team, Sport, Sports, Game, Company, Race, Country, City, State, Place
English Description is: Team, Sport, Sports, Game, Race, Company, Country, Organization, State, Brand
Overlap is: Company, Country, Game, Race, Sport, Sports, State, Team (8)
Difference is: Brand, City, Organization, Place (4)
Spanish word is: copa, English word is: cup
Spanish Description is: Game, Sport, Sports, Style, Team, Games, Race, Action, Service, Company
English Description is: Game, Sport, Sports, Race, Team, Event, League, Style, Form, Categories
Overlap is: Game, Race, Sport, Sports, Style, Team (6)
Difference is: Action, Categories, Company, Event, Form, Games, League, Service (8)
Spanish word is: tiempo, English word is: long
Spanish Description is: Game, Sports, Season, Sport, Time, Race, Event, Service, Size, Country
English Description is: Game, Season, Race, Sports, Country, Sport, Time, Event, Team, Place
Overlap is: Country, Event, Game, Race, Season, Sport, Sports, Time (8)
Difference is: Place, Service, Size, Team (4)
Spanish word is: futbol, English word is: Football
Spanish Description is: Sports, Sport, Game, Team, Hobby, Football, Games, Soccer, Action, Style
English Description is: Sport, Sports, Game, Team, Football, Games, Hobby, Soccer, League, Race
Overlap is: Football, Game, Games, Hobby, Soccer, Sport, Sports, Team (8)
Difference is: Action, League, Race, Style (4)
Again this is a strong performance for the post inference token filtering.
Training the model with manipulated teacher output is a non starter. I went to a workshop on model distillation, which inspired this approach, and in that they mentioned that the teacher must be of the same architecture as the student.
In distillation the teacher is informing the student of the best distribution for the different predictions. The recommendations from the teacher are shaped by the internal structure of the teacher. If the architecture of the teacher is different to the student then the recommended distribution is unlikely to help the student find a good set of weights.
Changing the output of the teacher before training the student is like changing the teacher architecture. This is why I think that the student performs poorly when trying to learn the manipulated distribution. There isn’t really a fix for this, so I think that token filtering has to be done post inference.
Separately to that the small and large models do have problems. Model collapse still seems to be an issue and should be the next focus.