Cross Language Prompt Internalization - Article Feature Clustering
Clustering the Wikipedia linked article features for Word Sense Induction
prompt internalization
multilingual prompt internalization
cross language word sense induction
Published
July 19, 2022
I have calculated features using the XLM-RoBERTa base model for different links on wikipedia. If the student model is to be used for word sense induction then these features should cluster. A lack of clustering would show that this approach is not viable.
If clustering is viable the next step would be to work out an efficient way to test containment, as well as calculating an approximate smallest number of features required. The wikipedia processing was only 2% completed and I estimated it as taking 20 days so a way to reduce the work required would be great.
Load Features
The features have been written to a set of files, each of which contains 1,000 articles. Each article has an average of 30 links in it. Only 201 files were processed however that does give us slightly over 6 million features.
These features are not evenly distributed among the different articles so some of them will have a lot of features and some will have very few or none.
Code
from pathlib import Pathimport pandas as pdDATA_FOLDER = Path("/data/prompt-internalization/multilingual/wikipedia/enwiki/20220701/")synonyms_df = pd.read_parquet(DATA_FOLDER /"synonyms.gz.parquet")features_df = pd.concat([ pd.read_parquet(file)forfileinsorted((DATA_FOLDER /"features").glob("*.gz.parquet"))])
We have almost 40,000 features for the top 10 articles. These articles are nice as they form into several distinct themes so we should expect articles like united states and england to be near to each other and united states and democratic party (united states) to be separated.
To be able to work with this I need to create a matrix that has the approximation of what the model produced. Each feature is the top 100 tokens split between the token index and probability. This matrix will be large though - the model has a vocabulary of 250,002 tokens, which will cause memory issues. Finding a smaller matrix that covers all the tokens that are non-zero would be good.
0.9999997086397343 1.0000002902579581 1.0000000003762612
(39963, 2192)
CPU times: user 923 ms, sys: 148 ms, total: 1.07 s
Wall time: 1.07 s
There are 10 separate articles and 100 tokens per link. If each article was always described in an identical way, and every different article was completely different, there would be 1,000 distinct tokens. We can see that there are 2,192 distinct tokens so this ideal state has not been achieved.
It should be possible to review how well the tokens overlap between the different labels.
Code
import pandas as pddef get_iou_crosstab(df: pd.DataFrame) -> pd.DataFrame: labels =sorted(df.target.unique()) df = df[["target", "index"]] df = df.explode("index") df = df.groupby("target").agg(set) intersection = { (left, right): len(df.loc[left][0] & df.loc[right][0])for left in labelsfor right in labels } union = { (left, right): len(df.loc[left][0] | df.loc[right][0])for left in labelsfor right in labels }return pd.DataFrame([ {other: intersection[(label, other)] / union[(label, other)] for other in labels}for label in labels ], index=labels)
This crosstab is pretty encouraging. With the threshold of 0.5 it shows that:
the world war articles overlap only with each other
the political party doesn’t overlap with anything else
most of the countries overlap with each other and the cities
This is a really rough way to cluster this data. Let’s see the results of a more structured analysis.
2d Projection
The first thing is to try out projecting this data into 2 dimensions so we can visualize it. I’m going to use my two favourite approaches of PCA and T-SNE.
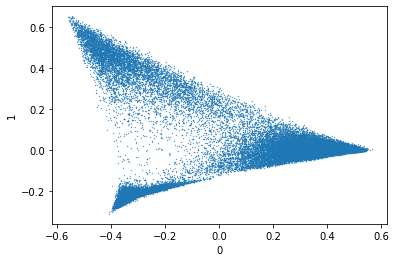
from sklearn.decomposition import PCAfrom sklearn.manifold import TSNEimport numpy as npn_components =2# doing this to avoid the warning about future T-SNEtsne_init = ( PCA( n_components=n_components, svd_solver="randomized", random_state=0, ) .fit_transform(probability) .astype(np.float32, copy=False))tsne_output = TSNE( n_components=n_components, learning_rate="auto", init=tsne_init,).fit_transform(probability)tsne_df = pd.DataFrame(tsne_output)tsne_df["target"] = top_10_rows.target.valuestsne_df.plot.scatter(x=0, y=1, s=0.1) ;None
Here it looks like the data has become a triangle with PCA and four clearly separate islands with T-SNE. This is interesting as it shows both clear structure and a lower set of clusters compared to the number of labels (remember it’s the top 10 labels).
Let’s try coloring this data by the label.
Code
from typing import List, Optionalimport matplotlib.pyplot as pltimport pandas as pddef plot_2d(df: pd.DataFrame, targets: Optional[List[str]] =None) ->None: fig, ax = plt.subplots(figsize=(12, 9))for group_name, group_idx in df.groupby("target").groups.items():if targets and group_name notin targets:continue ax.scatter(*df.iloc[group_idx, [0, 1]].T.values, s=0.1, label=group_name ) ax.legend(markerscale=10)
Code
plot_2d(pca_df)
Code
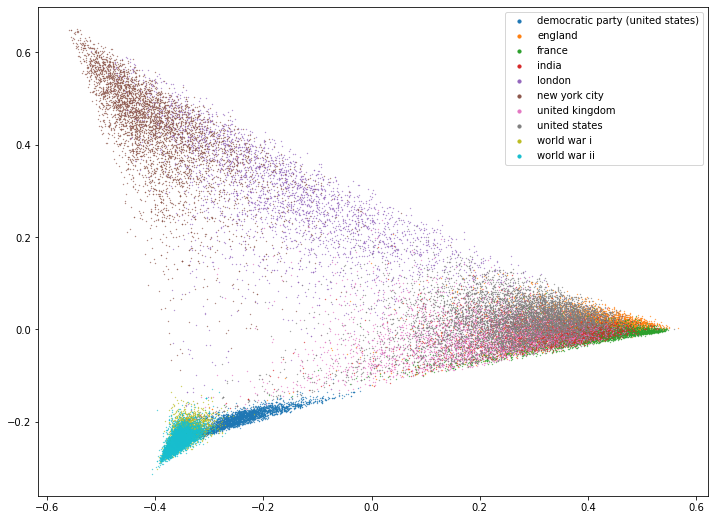
plot_2d(tsne_df)
The clusters do have mostly consistent color. I’m pleased that the democratic party is a separate isolated cluster which has very little overlap with the other labels. The T-SNE projection suggests that there are four distinct clusters in this data, being:
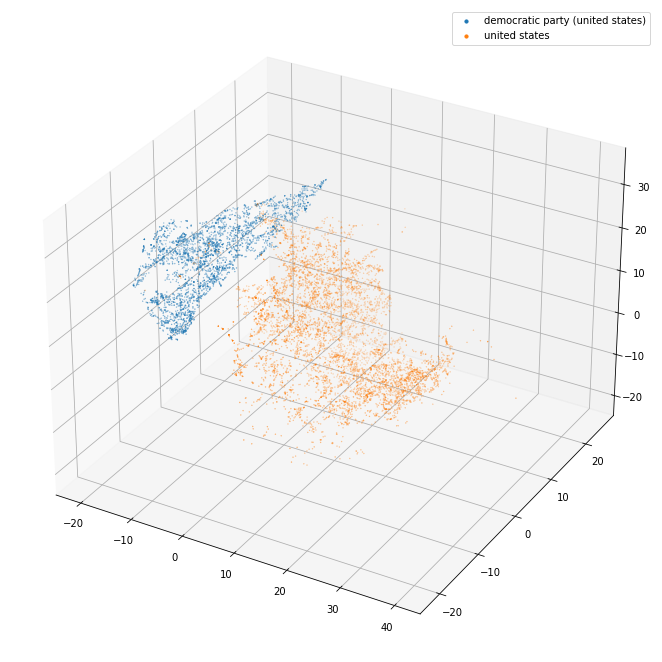
The democratic party (bottom center)
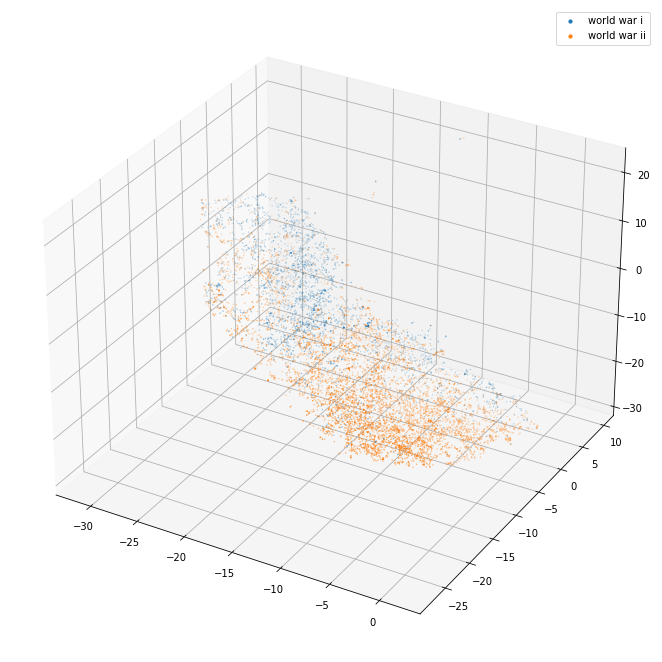
The world wars (left)
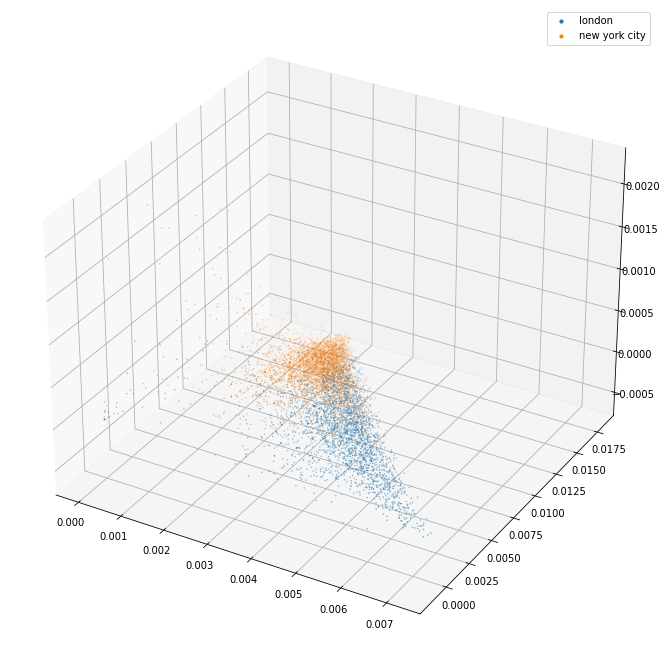
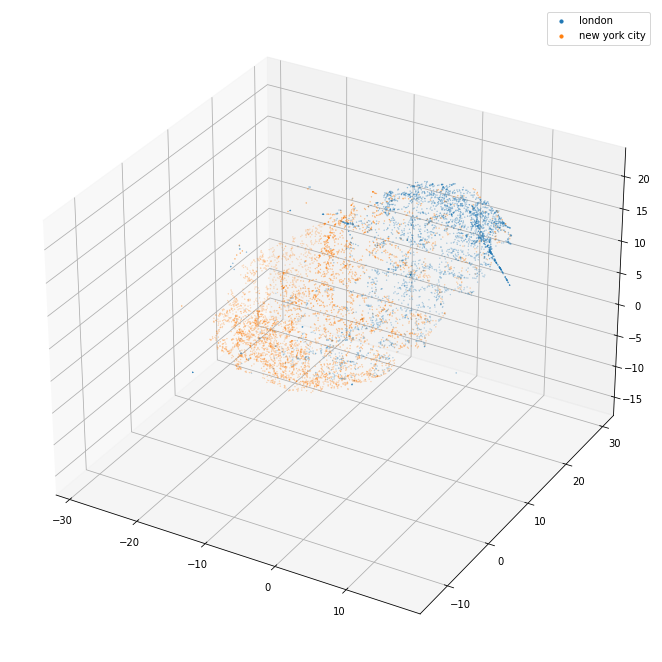
London and New York (top)
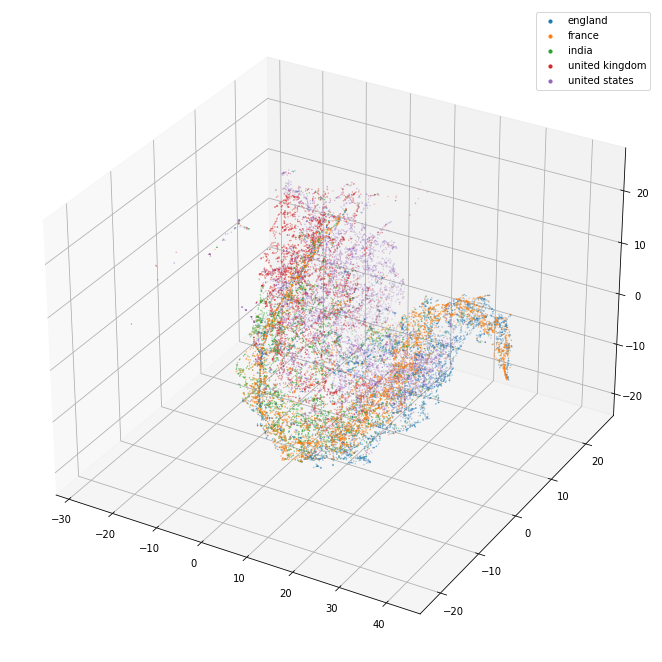
The countries (right)
Which is encouraging as it suggests that the cities can be cleanly separated from the countries.
PCA looks like it extends in another dimension as the shape reminds me of an old origami fold that I was fond of:
hyperbolic plane
I wonder if the labels separate more clearly in 3d.
3d Projection
PCA and T-SNE are not restricted to projecting to 2 dimensions. Given that the PCA projection in particular looks like it has a significant third dimension I’m interested in visualizing it.
from sklearn.decomposition import PCAfrom sklearn.manifold import TSNEimport numpy as npn_components =3# doing this to avoid the warning about future T-SNEtsne_init = ( PCA( n_components=n_components, svd_solver="randomized", random_state=0, ) .fit_transform(probability) .astype(np.float32, copy=False))tsne_output = TSNE( n_components=n_components, learning_rate="auto", init=tsne_init,).fit_transform(probability)tsne_3d_df = pd.DataFrame(tsne_output)tsne_3d_df["target"] = top_10_rows.target.values
Code
from typing import List, Optionalimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3Dimport pandas as pddef plot_3d(df: pd.DataFrame, targets: Optional[List[str]] =None) ->None: fig = plt.figure(figsize=(12, 9)) ax = Axes3D(fig, auto_add_to_figure=False) fig.add_axes(ax)for group_name, group_idx in df.groupby("target").groups.items():if targets and group_name notin targets:continue ax.scatter(*df.iloc[group_idx, [0, 1, 2]].T.values, s=0.1, label=group_name ) ax.legend(markerscale=10)
Code
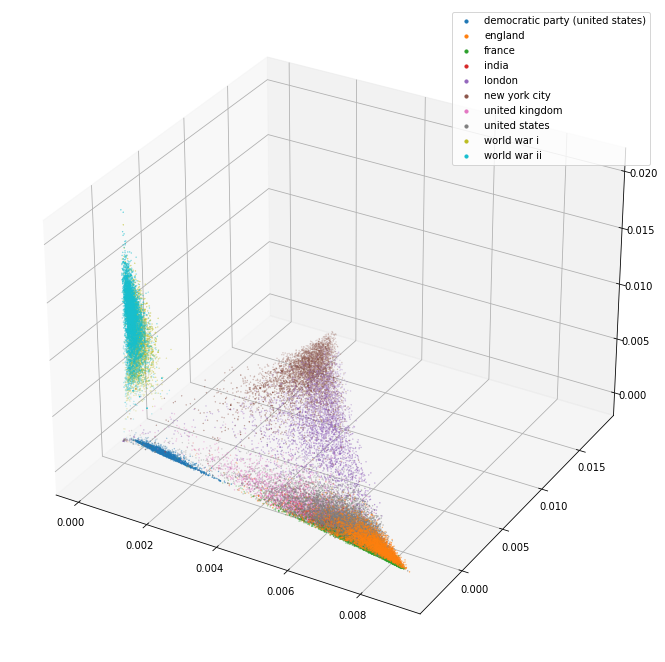
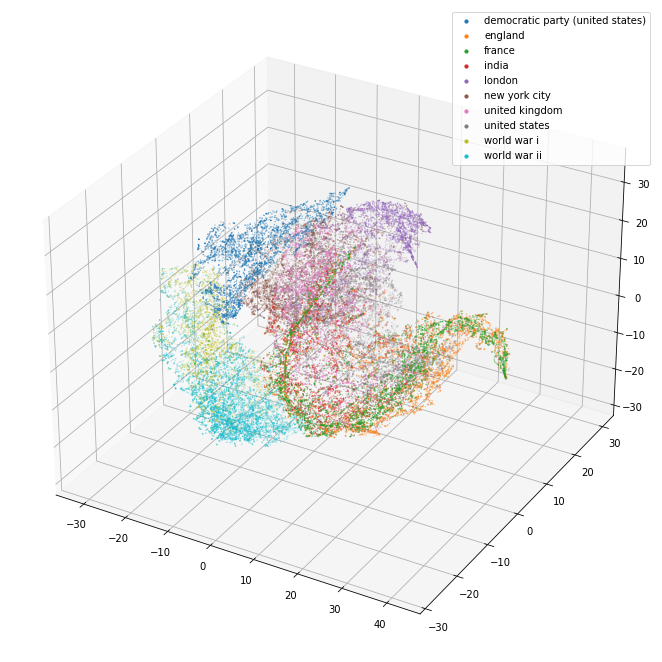
plot_3d(pca_3d_df)
Projecting this into 3d has shown something similar to the shape that I suspected. It’s almost a shame that I can’t rotate that projection a little to see it better. We can now try separating out the different labels into related groups to see if they are clustered near to each other.
Code
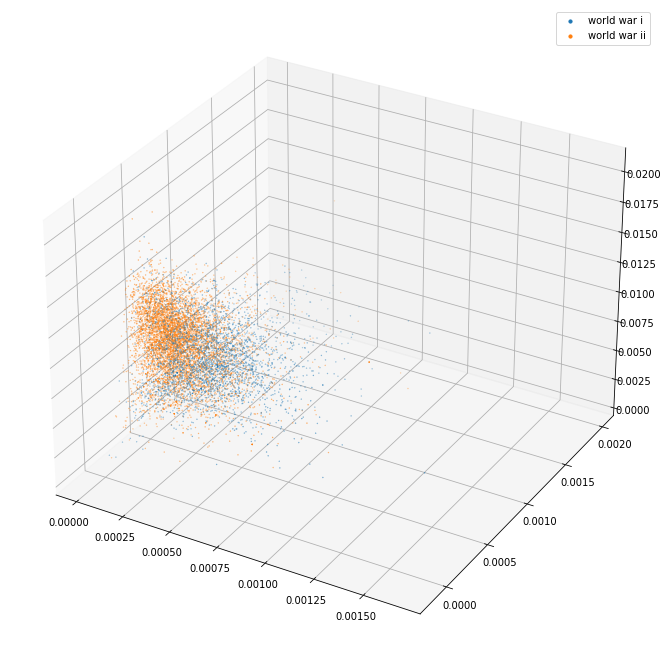
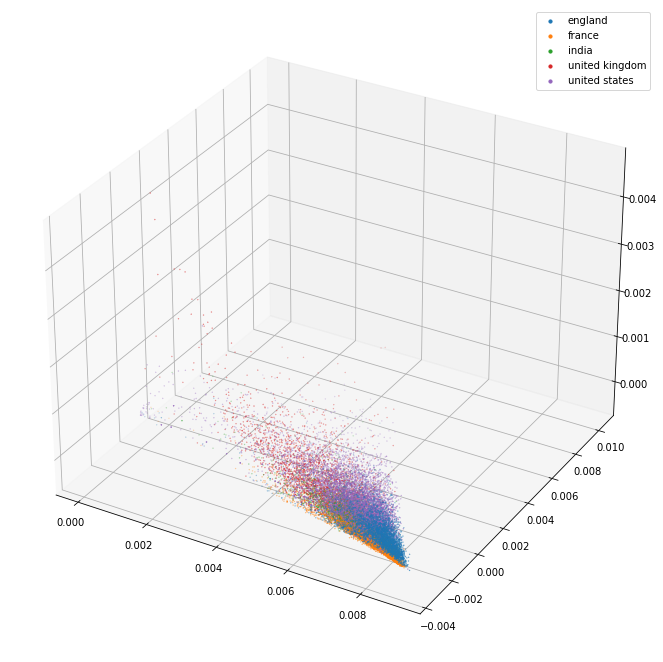
plot_3d(pca_3d_df, ["world war i", "world war ii"])
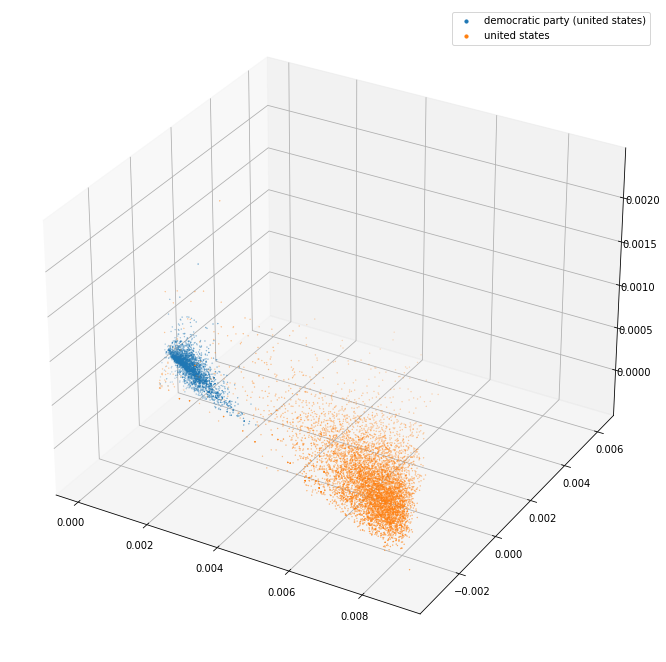
plot_3d(pca_3d_df, ["democratic party (united states)", "united states"])
The 3d projection helps a lot. I can see here that the separation between the separate kinds of things (political party/world war/city/country) seems pretty good. The countries in particular are blended together so it may well be that they are quite similar and that distinguishing them might be tricky.
We can repeat this with T-SNE, however that already looks like a complex structure so I am not sure how much this will help.
Code
plot_3d(tsne_3d_df)
Code
plot_3d(tsne_3d_df, ["world war i", "world war ii"])
plot_3d(tsne_3d_df, ["democratic party (united states)", "united states"])
The T-SNE projection might look pretty but the clarity of the separate clusters is somewhat lacking. I’m satisfied with the PCA projection results though.
Clustering New Points
Having these clusters is nice. What I need is to be able to define these clusters in a way where I can test new points to see if they lie within.
Given that the labels do not form nice spherical shapes I do not think that KMeans would be appropriate. Something that can track the shape more accurately could be better.
I like using (H)DBSCAN as it can track arbitrary shapes. Working with that over a large number of labels could be tricky so I may need to optimize this in future.
The biggest problem with using DBSCAN is coming up with appropriate values for eps and min_samples.
This doesn’t seem terrible? When considering these it is more significant to work out what the labelling would be for the wrong classes. As I see it DBSCAN is a very off/on classification where I may need a more continuous metric to allow for dispute resolution.
Using DBSCAN as the clustering shows much stronger performance. At this point the cities / countries are separated. Just from clustering this seems good enough as the actual text that was linked can be used as a signal to separate the intermingled cluster into the specific article.
Clustering with OPTIC
The sklearn documentation for DBSCAN also mentions OPTIC as an alternative which requires less configuration. Given that eps / max_samples are hard to calculate it might be worth trying.
/home/matthew/.cache/pypoetry/virtualenvs/blog-HrtMnrOS-py3.10/lib/python3.10/site-packages/sklearn/cluster/_optics.py:903: RuntimeWarning: divide by zero encountered in divide
ratio = reachability_plot[:-1] / reachability_plot[1:]
/home/matthew/.cache/pypoetry/virtualenvs/blog-HrtMnrOS-py3.10/lib/python3.10/site-packages/sklearn/cluster/_optics.py:903: RuntimeWarning: divide by zero encountered in divide
ratio = reachability_plot[:-1] / reachability_plot[1:]
This is incredibly slow to run and it smashes the data into tiny clusters. Given the lack of configuration it’s not really a viable system.