Code
from pathlib import Path
import json
AUTH_FILE = Path.home() / ".config" / "huggingface" / "auth.json"
ACCESS_TOKEN = json.loads(AUTH_FILE.read_text())["access_token"]A while ago a new model for image generation came out called Stable Diffusion (Rombach et al. 2022). It’s similar to DALL-E in that it can generate images from a snippet of text. I want to try it out and I finally have a little bit of free time to do so.
To follow along at home you need to agree to the terms of the model and get your access token. I’ve written the token to a local file so I can use it without revealing it.
from pathlib import Path
import json
AUTH_FILE = Path.home() / ".config" / "huggingface" / "auth.json"
ACCESS_TOKEN = json.loads(AUTH_FILE.read_text())["access_token"]This is the original code from the model card. I haven’t used the cli to login so I am just using the access token from above:
{'trained_betas'} was not found in config. Values will be initialized to default values.
ftfy or spacy is not installed using BERT BasicTokenizer instead of ftfy.prompt = "a photo of an astronaut riding a horse on mars"
with autocast("cuda"):
image = pipe(prompt, guidance_scale=7.5).images[0]
image{'trained_betas'} was not found in config. Values will be initialized to default values.
ftfy or spacy is not installed using BERT BasicTokenizer instead of ftfy.
That’s a nice picture. The blog post on the huggingface blog has a lot of these kinds of photos.
The pipeline takes several parameters:
The interesting parts of this are the:
guidance_scale Guidance scale as defined in Classifier-Free Diffusion Guidance(Ho and Salimans 2022). guidance_scale is defined as w of equation 2. of Imagen Paper(Saharia et al. 2022). Guidance scale is enabled by setting guidance_scale > 1. Higher guidance scale encourages to generate images that are closely linked to the text prompt, usually at the expense of lower image quality.
num_inference_steps The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference.
latents Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image generation. Can be used to tweak the same generation with different prompts. If not provided, a latents tensor will be generated by sampling using the supplied random generator.
So I can determine how much attention the model pays to the prompt, how much cleaning is done, and make it reproducible. We can turn this into a nice method as follows:
from typing import Optional
import torch
@torch.autocast("cuda")
def show(
prompt: str,
num_inference_steps: int = 100,
guidance_scale: float = 7.5,
latents: Optional[torch.FloatTensor] = None,
**config,
) -> None:
images = pipe(
prompt,
num_inference_steps=num_inference_steps,
guidance_scale=guidance_scale,
latents=latents,
**config,
).images
for image in images:
display(image)In this post I’m going to try generating lots of pictures of Buzz Lightyear. This is similar to the astronaught theme of the huggingface demo, but it does show one of the weaker areas of the image generators that I have seen so far - their ability to generate faces.
show("Buzz lightyear on mars")
This is a good start. The modelling of the suit is quite varied, the legs are done well but the buttons on the chest seem off. His face has problems with the eyes.
We can try adjusting the generation to turn up the influence of the guidance and the number of denoising steps.
show("Buzz lightyear on mars", guidance_scale=25, num_inference_steps=500)
In this picture buzz looks extremely good. The problems with the face are almost fixed and his suit is near perfect. Even his shadow seems better. Unfortunately there is a repeating texture across the surface of mars and it has lost some detail.
I wonder how it would compare if we drop these settings down to minimum.
show("Buzz lightyear on mars", guidance_scale=1, num_inference_steps=1)Potential NSFW content was detected in one or more images. A black image will be returned instead. Try again with a different prompt and/or seed.
I’m glad that there is a NSFW filter on this. In this case we are generating an image that should be safe for work so I am interested to see what the safety check is hiding. The safety checker is a classifier which has a model defined here.
It’s quite interesting as it has 20 different things that it looks for and it measures their presence using cosine similarity over the CLIP interpretation of the image. While it would be nice to find what those 20 concepts are I fear it might be quite depressing. Consideration like this is great to see.
For now we are generating what should be a benign image so I would like to disable this checker. I’m making a context manager for this. Let’s see what is being concealed.
from contextlib import contextmanager
@contextmanager
def unsafe():
def unsafe_check(clip_input, images):
return images, [False for _ in images]
original = pipe.safety_checker.forward
try:
pipe.safety_checker.forward = unsafe_check
yield
finally:
pipe.safety_checker.forward = original
with unsafe():
show("Buzz lightyear on mars", guidance_scale=1, num_inference_steps=1)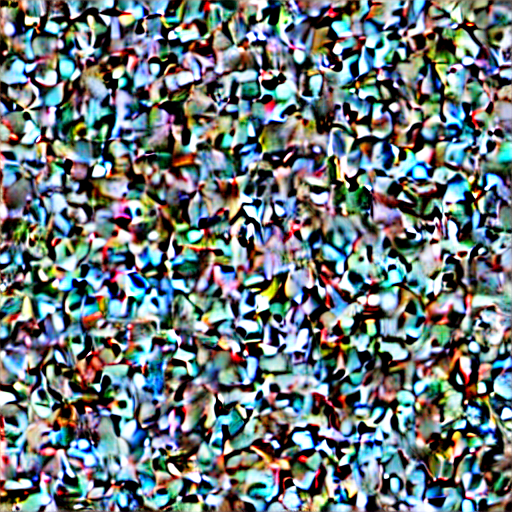
This looks like a mess.
I’ve started reading about the diffusion process from this blog post and it appers that this is the full noise stage before the image has coalesced.
The basic process of the diffusion model is to take noise and then repeatedly denoise it, turning it into the final image. I wonder if we can use the latent tensor to watch this turn into the real image. The first thing is to use the latent tensor to reliably produce the same image. In the blog post by huggingface they generate the latents with:
latents = torch.randn(
(batch_size, unet.in_channels, height // 8, width // 8),
generator=generator,
)
latents = latents.to(torch_device)It should be possible to use this same approach.
latents = torch.randn(
(1, pipe.unet.in_channels, 512 // 8, 512 // 8),
)
latents = latents.to(device)show("Buzz lightyear on mars", latents=latents, num_inference_steps=50)
show("Buzz lightyear on mars", latents=latents, num_inference_steps=50)
This is a nice enough image and the latents appear to have done their job. Let’s see if we can make a gif that shows how the image develops from the noise.
from typing import Iterator
from PIL import Image
# extremely slow approach!
def inference_progression(
prompt: str,
num_inference_steps: int,
latents: torch.FloatTensor,
) -> Iterator[Image.Image]:
for steps in range(1, num_inference_steps):
try:
yield pipe(
prompt,
num_inference_steps=steps,
latents=latents,
).images[0]
except:
print(f"problem generating image {steps}")
# https://pillow.readthedocs.io/en/stable/handbook/image-file-formats.html#gif
images = list(
inference_progression(
"Buzz lightyear on mars",
num_inference_steps=50,
latents=latents,
)
)
image = images[0] # extract first image from iterator
image.save(
fp="buzz-lightyear.gif",
format='GIF',
append_images=images[1:],
save_all=True,
duration=200,
loop=1,
)I haven’t disabled the NSFW filter this time and the generation of some of the images also hit problems. It seems that the num_inference_steps has some unusual results at images 3, 9, 27… so maybe there is some kind of rounding error there? Even so the progression is interesting:

What I want to do now is to break the model down into it’s individual parts and then manually convert each round of denoising. This would both show me how the model works and allow me to do interesting things like providing seed images.
The huggingface blog post has an excellent image of the diffusion process:
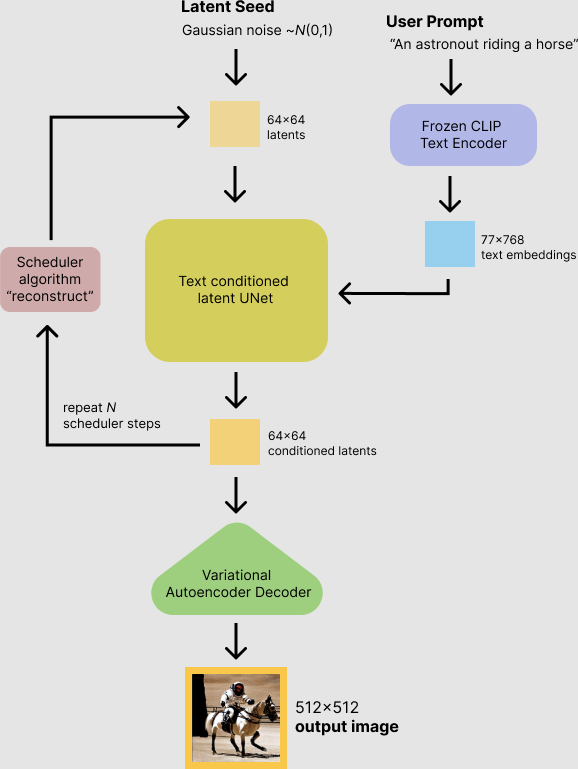
To be able to step in at each stage I need to be able to run the individual parts. Luckily the latents that were generated earlier should form a good starting point.
The first thing is to adjust the pipeline code to run the vae over every step of the process. Luckily the huggingface code is extremely high quality so a bit of copy and paste later (and feeling bad about calling a function argument self) we get:
import torch
import inspect
from tqdm.auto import tqdm
from PIL import Image
from typing import Iterator
from diffusers import LMSDiscreteScheduler
@torch.autocast("cuda")
@torch.inference_mode()
def one_pass(
self,
prompt: str,
latents: torch.Tensor,
num_inference_steps: int,
guidance_scale: float = 7.5,
height: int = 512,
width: int = 512,
) -> Iterator[Image.Image]:
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe.to(device)
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
# get prompt text embeddings
text_input = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_embeddings = self.text_encoder(text_input.input_ids.to(self.device))[0]
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
max_length = text_input.input_ids.shape[-1]
uncond_input = self.tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
latents_device = "cpu" if self.device.type == "mps" else self.device
latents_shape = (batch_size, self.unet.in_channels, height // 8, width // 8)
if latents is None:
latents = torch.randn(
latents_shape,
generator=generator,
device=latents_device,
)
else:
if latents.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
latents = latents.to(self.device)
# set timesteps
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
extra_set_kwargs = {}
if accepts_offset:
extra_set_kwargs["offset"] = 1
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
# if we use LMSDiscreteScheduler, let's make sure latents are mulitplied by sigmas
if isinstance(self.scheduler, LMSDiscreteScheduler):
latents = latents * self.scheduler.sigmas[0]
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for i, t in enumerate(self.progress_bar(self.scheduler.timesteps)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
if isinstance(self.scheduler, LMSDiscreteScheduler):
sigma = self.scheduler.sigmas[i]
# the model input needs to be scaled to match the continuous ODE formulation in K-LMS
latent_model_input = latent_model_input / ((sigma**2 + 1) ** 0.5)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
if isinstance(self.scheduler, LMSDiscreteScheduler):
latents = self.scheduler.step(noise_pred, i, latents, **extra_step_kwargs).prev_sample
else:
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
yield _to_image(self, latents)
def _to_image(self, latents: torch.Tensor) -> Image.Image:
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
return self.numpy_to_pil(image)[0]images = list(one_pass(pipe, prompt="buzz lightyear on mars", latents=latents, num_inference_steps=50))
image = images[0] # extract first image from iterator
image.save(
fp="better-steps.gif",
format='GIF',
append_images=images[1:],
save_all=True,
duration=200,
loop=0,
)Now we can see the steps in action. This is a vastly vastly better visualization of the process:

I’m really happy with this as it’s a far smaller change at each step compared to before. It also doesn’t have the strange steps.
If we wanted to adjust existing images with this then we would need the original encoder part of the vae. The vae does have an encoder though!
If we have the encoder then perhaps we could mask out part of the image and fill it with noise, then try generating the image again. Let’s see what happens if we encode and decode the same image.
from PIL import Image
import torch
@torch.no_grad()
def encode_decode(pipe, image: Image.Image) -> Image.Image:
latents = image_to_latents(image)
return latents_to_image(latents)
def image_to_latents(image: Image.Image) -> torch.Tensor:
image_array = image_to_tensor(image)
encoded = pipe.vae.encode(image_array)
return encoded.latent_dist.sample()
def image_to_tensor(image: Image.Image) -> torch.Tensor:
image = image.convert("RGB")
image_array = np.array(image)
image_array = image_array.astype(np.float32)
image_array = image_array / 255
image_array = image_array[None].transpose(0, 3, 1, 2)
image_array = torch.from_numpy(image_array)
image_array = (image_array - 0.5) * 2
image_array = image_array.to(pipe.device)
return image_array
def latents_to_image(latents: torch.Tensor) -> Image.Image:
decoded = pipe.vae.decode(latents)
image = decoded.sample
image = (image / 2 + 0.5).clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).numpy()
return pipe.numpy_to_pil(image)[0]encode_decode(pipe, images[-1])
This works perfectly, which is to be expected as the image itself is directly from the latent space. What we need now is to mask out part of the image with noise and then try to run that image through the process. Here is one I’ve created earlier:

@torch.no_grad()
def encode_denoise_decode(pipe, prompt: str, steps: int, image: Image.Image) -> Image.Image:
latents = image_to_latents(image)
yield from one_pass(pipe, prompt=prompt, latents=latents, num_inference_steps=steps)
# return latents_to_image(latents)with open("buzz-noise.png", "rb") as handle:
masked_image = Image.open(handle)
masked_image.load()
masked_image
denoised_images = list(encode_denoise_decode(
pipe,
"buzz lightyear on mars",
50,
masked_image,
))
denoised_image[0].save(
fp="denoising-face.gif",
format='GIF',
append_images=denoised_image[1:],
save_all=True,
duration=200,
loop=0,
)Unfortunately there is very little change in this image. I think this is because the model is expecting a noisy image where this is already quite noise free (excluding the specific face area of course). Instead what appears to happen is the entire image gets a little more noisy.

I wonder if a more effective way to do this would be to provide the source image as the prompt in some way. The model uses CLIP to encode the text prompt, so how would it handle an image prompt.
from transformers import CLIPVisionModel, CLIPFeatureExtractor
image_extractor = CLIPFeatureExtractor()
clip_model = CLIPVisionModel.from_pretrained("openai/clip-vit-base-patch32")
clip_model.eval()
clip_model.cuda() ; NoneSome weights of the model checkpoint at openai/clip-vit-base-patch32 were not used when initializing CLIPVisionModel: ['text_model.encoder.layers.9.layer_norm2.weight', 'text_model.encoder.layers.5.self_attn.v_proj.bias', 'text_model.encoder.layers.10.layer_norm2.bias', 'text_model.embeddings.position_embedding.weight', 'text_model.encoder.layers.4.layer_norm2.bias', 'text_model.encoder.layers.5.self_attn.k_proj.weight', 'text_model.encoder.layers.7.self_attn.v_proj.bias', 'text_model.final_layer_norm.weight', 'text_model.encoder.layers.0.self_attn.k_proj.bias', 'text_model.encoder.layers.3.self_attn.k_proj.weight', 'text_model.encoder.layers.9.layer_norm1.bias', 'text_model.encoder.layers.3.layer_norm2.weight', 'text_model.encoder.layers.3.mlp.fc2.weight', 'text_model.encoder.layers.4.self_attn.v_proj.weight', 'text_model.encoder.layers.2.layer_norm1.weight', 'text_model.encoder.layers.6.self_attn.q_proj.weight', 'text_model.encoder.layers.5.mlp.fc2.weight', 'text_model.encoder.layers.1.self_attn.v_proj.weight', 'text_model.encoder.layers.1.layer_norm2.weight', 'text_model.encoder.layers.7.self_attn.q_proj.weight', 'text_model.encoder.layers.3.layer_norm2.bias', 'text_model.encoder.layers.0.layer_norm1.weight', 'text_model.encoder.layers.10.self_attn.v_proj.bias', 'text_model.encoder.layers.8.layer_norm1.weight', 'text_model.encoder.layers.11.self_attn.q_proj.bias', 'text_model.encoder.layers.5.self_attn.q_proj.bias', 'text_model.encoder.layers.1.self_attn.k_proj.bias', 'text_model.encoder.layers.6.mlp.fc2.bias', 'text_model.encoder.layers.10.mlp.fc1.weight', 'text_model.encoder.layers.0.self_attn.q_proj.bias', 'text_model.encoder.layers.7.mlp.fc2.weight', 'text_model.encoder.layers.9.layer_norm1.weight', 'text_model.encoder.layers.1.self_attn.out_proj.bias', 'text_model.encoder.layers.8.layer_norm1.bias', 'text_model.encoder.layers.6.self_attn.k_proj.weight', 'text_model.encoder.layers.6.self_attn.out_proj.weight', 'text_model.encoder.layers.4.self_attn.out_proj.bias', 'text_model.encoder.layers.7.self_attn.k_proj.weight', 'text_model.encoder.layers.8.layer_norm2.bias', 'text_model.encoder.layers.10.layer_norm1.weight', 'text_model.encoder.layers.8.mlp.fc2.bias', 'text_model.encoder.layers.3.self_attn.k_proj.bias', 'text_model.encoder.layers.8.self_attn.out_proj.weight', 'text_model.embeddings.token_embedding.weight', 'text_model.encoder.layers.10.self_attn.out_proj.weight', 'text_model.encoder.layers.5.self_attn.out_proj.bias', 'text_model.encoder.layers.2.self_attn.out_proj.bias', 'text_model.encoder.layers.7.layer_norm2.weight', 'text_model.final_layer_norm.bias', 'text_model.encoder.layers.6.layer_norm2.bias', 'text_model.encoder.layers.8.self_attn.q_proj.bias', 'text_model.encoder.layers.5.self_attn.q_proj.weight', 'text_model.encoder.layers.3.self_attn.q_proj.weight', 'text_model.encoder.layers.6.layer_norm2.weight', 'text_model.encoder.layers.0.layer_norm2.weight', 'text_model.encoder.layers.2.self_attn.out_proj.weight', 'text_model.encoder.layers.6.mlp.fc1.weight', 'text_model.encoder.layers.1.self_attn.k_proj.weight', 'text_model.encoder.layers.0.mlp.fc1.bias', 'text_model.encoder.layers.2.self_attn.v_proj.weight', 'text_model.encoder.layers.11.self_attn.out_proj.bias', 'text_model.encoder.layers.4.self_attn.out_proj.weight', 'text_model.encoder.layers.5.self_attn.v_proj.weight', 'text_model.encoder.layers.9.self_attn.out_proj.bias', 'text_model.encoder.layers.0.self_attn.out_proj.weight', 'text_model.encoder.layers.8.layer_norm2.weight', 'text_model.encoder.layers.5.layer_norm1.bias', 'text_model.encoder.layers.0.layer_norm2.bias', 'text_model.encoder.layers.4.mlp.fc1.bias', 'text_model.encoder.layers.8.self_attn.k_proj.bias', 'text_model.encoder.layers.6.self_attn.v_proj.weight', 'text_model.encoder.layers.3.self_attn.q_proj.bias', 'text_model.encoder.layers.4.self_attn.q_proj.bias', 'text_model.encoder.layers.5.mlp.fc1.bias', 'text_projection.weight', 'text_model.encoder.layers.2.layer_norm2.bias', 'text_model.encoder.layers.11.mlp.fc2.weight', 'text_model.encoder.layers.3.self_attn.v_proj.bias', 'text_model.encoder.layers.11.layer_norm2.weight', 'text_model.encoder.layers.8.self_attn.k_proj.weight', 'text_model.encoder.layers.4.self_attn.v_proj.bias', 'text_model.encoder.layers.2.self_attn.k_proj.weight', 'text_model.encoder.layers.1.layer_norm2.bias', 'text_model.encoder.layers.10.self_attn.q_proj.weight', 'text_model.encoder.layers.6.layer_norm1.bias', 'text_model.encoder.layers.6.layer_norm1.weight', 'text_model.encoder.layers.10.self_attn.k_proj.weight', 'text_model.encoder.layers.2.self_attn.k_proj.bias', 'text_model.encoder.layers.10.layer_norm2.weight', 'text_model.encoder.layers.0.mlp.fc2.weight', 'text_model.encoder.layers.3.layer_norm1.bias', 'text_model.encoder.layers.2.layer_norm1.bias', 'text_model.encoder.layers.1.mlp.fc1.weight', 'text_model.encoder.layers.2.self_attn.q_proj.bias', 'text_model.encoder.layers.11.layer_norm1.bias', 'text_model.encoder.layers.9.self_attn.k_proj.weight', 'text_model.encoder.layers.2.mlp.fc1.bias', 'text_model.encoder.layers.10.layer_norm1.bias', 'text_model.encoder.layers.7.self_attn.q_proj.bias', 'text_model.encoder.layers.9.self_attn.q_proj.weight', 'text_model.encoder.layers.1.self_attn.v_proj.bias', 'text_model.encoder.layers.10.self_attn.v_proj.weight', 'text_model.encoder.layers.5.self_attn.out_proj.weight', 'text_model.encoder.layers.7.self_attn.v_proj.weight', 'text_model.encoder.layers.8.mlp.fc1.weight', 'text_model.encoder.layers.8.self_attn.v_proj.weight', 'text_model.encoder.layers.3.layer_norm1.weight', 'text_model.encoder.layers.7.layer_norm2.bias', 'text_model.encoder.layers.11.mlp.fc1.bias', 'text_model.encoder.layers.8.mlp.fc1.bias', 'text_model.encoder.layers.6.mlp.fc1.bias', 'text_model.encoder.layers.7.mlp.fc1.bias', 'text_model.encoder.layers.5.layer_norm2.weight', 'text_model.encoder.layers.1.mlp.fc2.bias', 'text_model.encoder.layers.0.self_attn.out_proj.bias', 'text_model.encoder.layers.10.mlp.fc2.bias', 'visual_projection.weight', 'text_model.encoder.layers.2.self_attn.v_proj.bias', 'text_model.encoder.layers.9.self_attn.q_proj.bias', 'text_model.encoder.layers.0.mlp.fc2.bias', 'text_model.encoder.layers.8.self_attn.q_proj.weight', 'text_model.encoder.layers.0.self_attn.v_proj.bias', 'text_model.encoder.layers.10.self_attn.out_proj.bias', 'text_model.encoder.layers.0.self_attn.q_proj.weight', 'text_model.encoder.layers.7.self_attn.k_proj.bias', 'text_model.encoder.layers.9.self_attn.k_proj.bias', 'text_model.encoder.layers.1.self_attn.q_proj.bias', 'text_model.encoder.layers.8.self_attn.out_proj.bias', 'text_model.encoder.layers.9.mlp.fc1.weight', 'text_model.encoder.layers.9.self_attn.v_proj.weight', 'text_model.encoder.layers.3.self_attn.v_proj.weight', 'text_model.encoder.layers.2.mlp.fc1.weight', 'text_model.encoder.layers.9.mlp.fc2.weight', 'text_model.encoder.layers.0.self_attn.k_proj.weight', 'text_model.encoder.layers.6.self_attn.k_proj.bias', 'text_model.encoder.layers.4.layer_norm2.weight', 'text_model.encoder.layers.9.self_attn.out_proj.weight', 'text_model.encoder.layers.4.mlp.fc1.weight', 'text_model.encoder.layers.11.self_attn.v_proj.weight', 'text_model.encoder.layers.3.mlp.fc1.weight', 'text_model.encoder.layers.7.layer_norm1.weight', 'text_model.encoder.layers.2.mlp.fc2.weight', 'text_model.encoder.layers.8.mlp.fc2.weight', 'text_model.encoder.layers.0.mlp.fc1.weight', 'text_model.encoder.layers.6.self_attn.q_proj.bias', 'text_model.encoder.layers.11.self_attn.out_proj.weight', 'text_model.encoder.layers.5.mlp.fc2.bias', 'logit_scale', 'text_model.encoder.layers.3.self_attn.out_proj.bias', 'text_model.encoder.layers.1.self_attn.q_proj.weight', 'text_model.encoder.layers.4.mlp.fc2.weight', 'text_model.encoder.layers.11.self_attn.k_proj.bias', 'text_model.encoder.layers.9.layer_norm2.bias', 'text_model.encoder.layers.11.self_attn.q_proj.weight', 'text_model.encoder.layers.1.layer_norm1.bias', 'text_model.encoder.layers.7.layer_norm1.bias', 'text_model.encoder.layers.3.self_attn.out_proj.weight', 'text_model.encoder.layers.8.self_attn.v_proj.bias', 'text_model.encoder.layers.4.layer_norm1.weight', 'text_model.encoder.layers.11.self_attn.k_proj.weight', 'text_model.encoder.layers.11.mlp.fc2.bias', 'text_model.encoder.layers.9.mlp.fc2.bias', 'text_model.encoder.layers.2.layer_norm2.weight', 'text_model.embeddings.position_ids', 'text_model.encoder.layers.11.layer_norm1.weight', 'text_model.encoder.layers.4.self_attn.k_proj.bias', 'text_model.encoder.layers.7.mlp.fc1.weight', 'text_model.encoder.layers.1.mlp.fc1.bias', 'text_model.encoder.layers.6.mlp.fc2.weight', 'text_model.encoder.layers.4.self_attn.k_proj.weight', 'text_model.encoder.layers.5.layer_norm2.bias', 'text_model.encoder.layers.5.self_attn.k_proj.bias', 'text_model.encoder.layers.9.self_attn.v_proj.bias', 'text_model.encoder.layers.2.mlp.fc2.bias', 'text_model.encoder.layers.0.self_attn.v_proj.weight', 'text_model.encoder.layers.10.self_attn.q_proj.bias', 'text_model.encoder.layers.1.layer_norm1.weight', 'text_model.encoder.layers.1.self_attn.out_proj.weight', 'text_model.encoder.layers.4.mlp.fc2.bias', 'text_model.encoder.layers.7.mlp.fc2.bias', 'text_model.encoder.layers.2.self_attn.q_proj.weight', 'text_model.encoder.layers.1.mlp.fc2.weight', 'text_model.encoder.layers.3.mlp.fc2.bias', 'text_model.encoder.layers.11.mlp.fc1.weight', 'text_model.encoder.layers.9.mlp.fc1.bias', 'text_model.encoder.layers.0.layer_norm1.bias', 'text_model.encoder.layers.4.self_attn.q_proj.weight', 'text_model.encoder.layers.5.layer_norm1.weight', 'text_model.encoder.layers.4.layer_norm1.bias', 'text_model.encoder.layers.10.mlp.fc1.bias', 'text_model.encoder.layers.10.mlp.fc2.weight', 'text_model.encoder.layers.11.layer_norm2.bias', 'text_model.encoder.layers.6.self_attn.out_proj.bias', 'text_model.encoder.layers.10.self_attn.k_proj.bias', 'text_model.encoder.layers.5.mlp.fc1.weight', 'text_model.encoder.layers.7.self_attn.out_proj.bias', 'text_model.encoder.layers.3.mlp.fc1.bias', 'text_model.encoder.layers.7.self_attn.out_proj.weight', 'text_model.encoder.layers.11.self_attn.v_proj.bias', 'text_model.encoder.layers.6.self_attn.v_proj.bias']
- This IS expected if you are initializing CLIPVisionModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing CLIPVisionModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).@torch.autocast("cuda")
@torch.inference_mode()
def denoising_loop(
self,
prompt_embedding: torch.Tensor,
latents: torch.Tensor,
num_inference_steps: int,
guidance_scale: float = 7.5,
height: int = 512,
width: int = 512,
) -> Iterator[Image.Image]:
device = "cuda" if torch.cuda.is_available() else "cpu"
self.to(device)
latents = latents.to(self.device)
batch_size, token_count, *_ = prompt_embedding.shape
if len(prompt_embedding.shape) == 2:
prompt_embedding = prompt_embedding.broadcast_to(1, self.tokenizer.model_max_length, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
max_length = text_input.input_ids.shape[-1]
uncond_input = self.tokenizer(
[""] * batch_size, padding="max_length", max_length=token_count, return_tensors="pt"
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0][:, :token_count]
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embedding = torch.cat([uncond_embeddings, prompt_embedding])
# set timesteps
accepts_offset = "offset" in set(inspect.signature(self.scheduler.set_timesteps).parameters.keys())
extra_set_kwargs = {}
if accepts_offset:
extra_set_kwargs["offset"] = 1
self.scheduler.set_timesteps(num_inference_steps, **extra_set_kwargs)
# if we use LMSDiscreteScheduler, let's make sure latents are mulitplied by sigmas
if isinstance(self.scheduler, LMSDiscreteScheduler):
latents = latents * self.scheduler.sigmas[0]
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for i, t in enumerate(self.progress_bar(self.scheduler.timesteps)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
if isinstance(self.scheduler, LMSDiscreteScheduler):
sigma = self.scheduler.sigmas[i]
# the model input needs to be scaled to match the continuous ODE formulation in K-LMS
latent_model_input = latent_model_input / ((sigma**2 + 1) ** 0.5)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=prompt_embedding).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
if isinstance(self.scheduler, LMSDiscreteScheduler):
latents = self.scheduler.step(noise_pred, i, latents, **extra_step_kwargs).prev_sample
else:
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
yield _to_image(self, latents)@torch.no_grad()
def image_prompt(image: Image.Image) -> torch.Tensor:
tensors = image_extractor(image, return_tensors="pt")
tensors.to(clip_model.device)
embedding = clip_model(**tensors).pooler_output
return embedding[None]
@torch.no_grad()
def text_prompt(prompt: str) -> torch.Tensor:
text_input = pipe.tokenizer(
prompt,
padding="max_length",
max_length=pipe.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
return pipe.text_encoder(text_input.input_ids.to(pipe.device))[0]images = list(denoising_loop(
pipe,
prompt_embedding=text_prompt("buzz lightyear on mars"),
latents=latents,
num_inference_steps=50,
# guidance_scale=1,
))
buzz_lightyear_image = images[-1]
buzz_lightyear_image
images = list(denoising_loop(
pipe,
prompt_embedding=image_prompt(buzz_lightyear_image),
latents=latents,
num_inference_steps=50,
# guidance_scale=1,
))
images[-1]
images = list(denoising_loop(
pipe,
prompt_embedding=(image_prompt(buzz_lightyear_image) + text_prompt("buzz lightyear on mars")) / 2,
latents=latents,
num_inference_steps=50,
# guidance_scale=1,
))
images[-1]
This approach is clearly not working. I’m not sure that the clip model I am using to encode the image is consistent with the clip model used to embed the text.
Something to fiddle with later. I’ve spent enough time on this and written enough horrible code.