What parts of an image contribute to the CLIP classification?
image classification
clip
Published
November 19, 2022
CLIP (Radford et al. 2021) is a pair of models that produces an embedding from an image or from some text. The training involved aligning the output between an image and it’s caption.
Radford, Alec, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, et al. 2021. “Learning Transferable Visual Models from Natural Language Supervision.” arXiv. https://doi.org/10.48550/ARXIV.2103.00020.
We can use this to classify images by providing a prompt that describes some images and seeing how close the match is with a given image. This is how the original code classifies datasets like imagenet (see the example notebook for details).
What I would like to do is to determine what parts of an image contribute most to a given classification.
Example Inference
Here we are going to calculate the image similarity to a lot of different prompts. Then we can recreate the process of calculating the similarity to understand more about how CLIP works.
“Dataset”
To perform these inferences I need a dataset. I’m going to use this photo of a cat:
a cat
Image Classification
I am going to describe the content of this image. To do this I am going to use the prompt templates from the CLIP ImageNet prompts along with 10 different classes (big code block…):
Code
imagenet_classes = ["cat","dog","bird","rat","building","tree","man","woman","boy","girl",]imagenet_templates = ['a bad photo of a {}.','a photo of many {}.','a sculpture of a {}.','a photo of the hard to see {}.','a low resolution photo of the {}.','a rendering of a {}.','graffiti of a {}.','a bad photo of the {}.','a cropped photo of the {}.','a tattoo of a {}.','the embroidered {}.','a photo of a hard to see {}.','a bright photo of a {}.','a photo of a clean {}.','a photo of a dirty {}.','a dark photo of the {}.','a drawing of a {}.','a photo of my {}.','the plastic {}.','a photo of the cool {}.','a close-up photo of a {}.','a black and white photo of the {}.','a painting of the {}.','a painting of a {}.','a pixelated photo of the {}.','a sculpture of the {}.','a bright photo of the {}.','a cropped photo of a {}.','a plastic {}.','a photo of the dirty {}.','a jpeg corrupted photo of a {}.','a blurry photo of the {}.','a photo of the {}.','a good photo of the {}.','a rendering of the {}.','a {} in a video game.','a photo of one {}.','a doodle of a {}.','a close-up photo of the {}.','a photo of a {}.','the origami {}.','the {} in a video game.','a sketch of a {}.','a doodle of the {}.','a origami {}.','a low resolution photo of a {}.','the toy {}.','a rendition of the {}.','a photo of the clean {}.','a photo of a large {}.','a rendition of a {}.','a photo of a nice {}.','a photo of a weird {}.','a blurry photo of a {}.','a cartoon {}.','art of a {}.','a sketch of the {}.','a embroidered {}.','a pixelated photo of a {}.','itap of the {}.','a jpeg corrupted photo of the {}.','a good photo of a {}.','a plushie {}.','a photo of the nice {}.','a photo of the small {}.','a photo of the weird {}.','the cartoon {}.','art of the {}.','a drawing of the {}.','a photo of the large {}.','a black and white photo of a {}.','the plushie {}.','a dark photo of a {}.','itap of a {}.','graffiti of the {}.','a toy {}.','itap of my {}.','a photo of a cool {}.','a photo of a small {}.','a tattoo of the {}.',]print(f"{len(imagenet_classes)} classes, {len(imagenet_templates)} templates")
10 classes, 80 templates
I’ve had to cut this down to 10 classes just to spare my memory. The next thing is to calculate the similarity for each of these prompts:
Code
from PIL import Imageimport pandas as pdimport torchfrom transformers import CLIPProcessor, CLIPModelmodel = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")# url = "http://images.cocodataset.org/val2017/000000039769.jpg" two cats!# image = Image.open(requests.get(url, stream=True).raw)image = Image.open("cat.jpg")descriptions = { name: [template.format(name) for template in imagenet_templates]for name in imagenet_classes}prompts = { prompt: labelfor label, prompts in descriptions.items()for prompt in prompts}with torch.inference_mode(): inputs = processor( text=list(prompts.keys()), images=image, return_tensors="pt", padding=True, ) outputs = model(**inputs)logits_per_image = outputs.logits_per_image # this is the image-text similarity scoreprobability_df = pd.DataFrame([ {"label": label, "type": prompts[label], "probability": probability}for label, probability inzip(prompts.keys(), logits_per_image.softmax(dim=1)[0].tolist())])probability_df.sort_values(by="probability", ascending=False).head()
We can see that out of the 800 prompts the top 5 are all for variations of cat prompts. So it has correctly classified the image as one of a cat.
Understanding the Model
How does this actually work?
The important thing to realise is that there are two models under the hood, the text one and the image one. That also means that the preprocessing performed by the processor is actually two preprocessors, one for image and one for text. Then the embeddings for the two preprocessed forms are calculated and the similarity for each is produced.
We can break this down into the individual parts and reproduce that similarity score of 29.
Code
image_features = processor.feature_extractor(image, return_tensors="pt")text_features = processor.tokenizer(["a rendering of a cat."], return_tensors="pt")
/home/matthew/.local/share/virtualenvs/blog-1tuLwbZm/lib/python3.10/site-packages/transformers/models/clip/processing_clip.py:142: FutureWarning: `feature_extractor` is deprecated and will be removed in v5. Use `image_processor` instead.
warnings.warn(
This is actually calculating the cosine similarity, and boosting it using the model.logits_scale.exp() factor. We can easily prove this by just calculating the cosine similarity over the unscaled embeddings.
Code
import torch.nn.functional as FF.cosine_similarity(text_embeds, image_embeds)
tensor([0.2971])
For some reason they have lifted the calculation into the model. The scaling factor is more reasonable as that alters the probabilities that are produced by the softmax, making them more extreme as we can see below:
By scaling the random starting cosine similarities we can see that we move from a 24% confidence in the top class to a 99% confidence.
What Contributed to the Cat Classification?
If we imagine that the cosine similarity between the text embedding and the image embedding is a linear classification head, like the one that exists in ResNet, then we could try to work out what contributed to the classification. This has been done for ResNet before and has resulted in nice heatmaps that show the activations of different parts of the image. To make the heatmaps the unpooled output of the model was mapped back onto the image.
The image part of CLIP is not like ResNet though. It uses visual attention blocks, after converting the image to 32x32 blocks through a convolution layer. Attention blocks are fully connected so the outputs of a single layer can come from any part of the image.
The amount of math needed to reverse this seems feasible but large. It would be nice if there was a quicker way to calculate this.
Cosine similarity is a scaled dot product. The dot product is like a linear layer without a weight. So if we take the text embedding as our weights (it is the classifier after all), and the image embeddings as the activation, then looking for the most extreme text embedding values would be a good indication of what “features” contribute most to the classification.
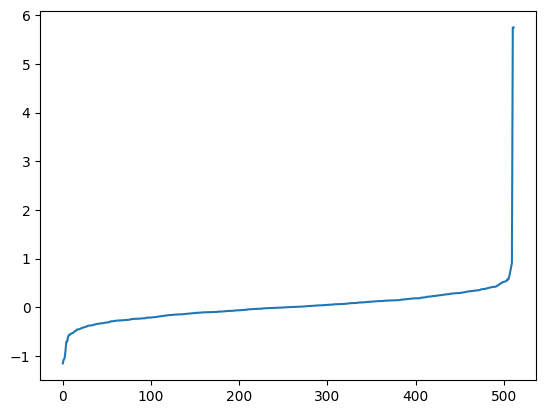
Most of the values cluster around zero and very few values are actually large. If I could find a way to enhance those values and trace it back to the image then that might show what is contributing to the classification.
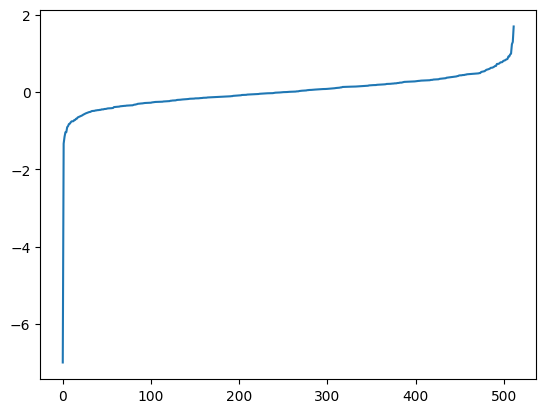
We can review the image as well to see if it also has a very polarized classification.
overlapping_strong_indices =set(image_series[image_series.abs() >=1].index) &set(text_series[text_series.abs() >=1].index)print(f"The overlapping strong indices are: {sorted(overlapping_strong_indices)}")
The overlapping strong indices are: [92]
This time the image has more strongly negative values. What’s interesting here is that the strong values only overlap on index 92. I had thought that index 133 was the most important, but it seems not!
To do this I have a plan. If I were to ask the model to enhance the output values for these indices then it might change the areas that currently do not contribute to the classification. However if I ask the model to reduce the output values then it should identify the areas that do contribute to the classification, as it would be interested in cutting them out.
This is fundamentally a similar approach to what I did for the prompt training, except in reverse. Let’s try it out.
Broad Deoptimization Tracking
The aim is to find the parts of the input image which contribute to the classification. We don’t have to be incredibly precise, as ultimately the combination of pixels is what produces an image feature. This makes me think that working with the output of the strided convolution would be good.
To remind ourselves, the structure of the model is as follows:
The output of the 32x32 convolution is tightly associated with the source image, while smoothing over the individual pixels. Trying to “optimize” the output of this and tracking the locations that change should give an idea of what the model is focusing on. To achieve this I need to be able to pass in the convoluted image, which will require adjusting the embedding layer.
/home/matthew/.local/share/virtualenvs/blog-1tuLwbZm/lib/python3.10/site-packages/transformers/models/clip/processing_clip.py:142: FutureWarning: `feature_extractor` is deprecated and will be removed in v5. Use `image_processor` instead.
warnings.warn(
Looking at this doesn’t clearly show me what in the image it is looking at. I need a way to overlay this onto the original image. The approach of using the post convolution pixels is also questionable to me, as there are so many channels - how can I select the most appropriate value per region?
Let’s start by trying to convert the pixel values back into the original image. The preprocessor does a center crop, a resize, and then normalizes the pixel values. If I can reverse that then I can see what the model sees.
The model has clipped this image very well as it is clearly still a cat. If I was to scale the different sections of this image so that the parts of the image it does not want to change are faded, then we should be able to see what it wants to change.
Code
from PIL import Imagefrom torchvision.transforms import ToPILImageimage_mean = torch.tensor([0.48145466,0.4578275,0.40821073])image_std = torch.tensor([0.26862954,0.26130258,0.27577711])def show_region_attention(values: torch.Tensor, attention: torch.Tensor) ->None:# need to resize attention to match the values attention = attention.to(float) attention = attention[0] attention = attention.repeat_interleave(32, dim=0).repeat_interleave(32, dim=1) attention = attention - attention.min() attention = attention / attention.max()iflen(attention.shape) ==2: attention = attention[None] values = values[0] values = (values * image_std[:, None, None]) + image_mean[:, None, None] values = values * attention display(ToPILImage()(values))def most_varied_channel(attention: torch.Tensor) ->int:# this finds the channel that has the greatest variation between min and max value attention = attention.reshape(768, -1) value_range = attention.max(dim=1).values - attention.min(dim=1).valuesreturn value_range.argmax().item()
Code
print("92 feature: mean of all channels")show_region_attention( image_features.pixel_values, interest_92.mean(dim=1),)print("92 feature: max of all channels")show_region_attention( image_features.pixel_values, interest_92.max(dim=1).values,)print("92 feature: most varied channel")show_region_attention( image_features.pixel_values, interest_92[:, most_varied_channel(interest_92)],)
92 feature: mean of all channels
92 feature: max of all channels
92 feature: most varied channel
When I use the mean it seems that the tips of the ears are most interesting. The most varied channel is harder to interpret. Neither of these is the clear indication that I was hoping for.
I wonder if I am being too selective with the loss calculation.
Code
import torchwith torch.no_grad(): text_features = processor.tokenizer(["a rendering of a cat."], return_tensors="pt") text_outputs = model.text_model(**text_features) text_embeds = text_outputs[1] # pooler_output text_embeds = model.text_projection(text_embeds)def no_cat_loss(output: torch.Tensor) -> torch.Tensor:return (torch.matmul(output, text_embeds.T) **2).sum()interest_cat = regions_of_interest( processor=processor, model=model, image=image, loss_fn=no_cat_loss, steps=1,)print("anti cat loss: mean of all channels")show_region_attention( image_features.pixel_values, interest_cat.mean(dim=1),)print("anti cat loss: max of all channels")show_region_attention( image_features.pixel_values, interest_cat.max(dim=1).values,)print("anti cat loss: most varied channel")show_region_attention( image_features.pixel_values, interest_cat[:, most_varied_channel(interest_cat)],)interest_cat.max()
anti cat loss: mean of all channels
anti cat loss: max of all channels
anti cat loss: most varied channel
tensor(30.0327)
Code
import torchwith torch.no_grad(): text_features = processor.tokenizer(["a rendering of a cat."], return_tensors="pt") text_outputs = model.text_model(**text_features) text_embeds = text_outputs[1] # pooler_output text_embeds = model.text_projection(text_embeds)def positive_cat_loss(output: torch.Tensor) -> torch.Tensor: dot_product = torch.matmul(output, text_embeds.T) dot_product[dot_product <=0] =0.return (dot_product **2).sum()interest_cat = regions_of_interest( processor=processor, model=model, image=image, loss_fn=positive_cat_loss,)print("only cat contributors loss: mean of all channels")show_region_attention( image_features.pixel_values, interest_cat.mean(dim=1),)print("only cat contributors loss: max of all channels")show_region_attention( image_features.pixel_values, interest_cat.max(dim=1).values,)print("only cat contributors loss: boosted max of all channels")show_region_attention( image_features.pixel_values, (interest_cat.max(dim=1).values *100).softmax(dim=2))interest_cat.max()
only cat contributors loss: mean of all channels
only cat contributors loss: max of all channels
only cat contributors loss: boosted max of all channels
tensor(30.0327)
Code
import torchwith torch.no_grad(): text_features = processor.tokenizer(["a rendering of a cat."], return_tensors="pt") text_outputs = model.text_model(**text_features) text_embeds = text_outputs[1] # pooler_output text_embeds = model.text_projection(text_embeds)def strong_cat_loss(output: torch.Tensor) -> torch.Tensor:global text_embeds text_embeds = text_embeds.clone() text_embeds[text_embeds <0.75] =0.return (torch.matmul(output, text_embeds.T) **2).sum()interest_cat = regions_of_interest( processor=processor, model=model, image=image, loss_fn=strong_cat_loss,)print("strong prompt contributors loss: mean of all channels")show_region_attention( image_features.pixel_values, interest_cat.mean(dim=1),)print("strong prompt contributors loss: max of all channels")show_region_attention( image_features.pixel_values, interest_cat.max(dim=1).values,)print("strong prompt contributors loss: boosted max of all channels")show_region_attention( image_features.pixel_values, (interest_cat.max(dim=1).values *100).softmax(dim=2))interest_cat.max()
strong prompt contributors loss: mean of all channels
strong prompt contributors loss: max of all channels
strong prompt contributors loss: boosted max of all channels
tensor(2.3929)
Code
import torchwith torch.no_grad(): text_features = processor.tokenizer(["a rendering of a cat."], return_tensors="pt") text_outputs = model.text_model(**text_features) text_embeds = text_outputs[1] # pooler_output text_embeds = model.text_projection(text_embeds)def strong_cat_loss(output: torch.Tensor) -> torch.Tensor:global text_embeds text_embeds = text_embeds.clone() text_embeds[text_embeds >-0.75] =0.return (torch.matmul(output, text_embeds.T) **2).sum()interest_cat = regions_of_interest( processor=processor, model=model, image=image, loss_fn=strong_cat_loss,)print("strong prompt detractors loss: mean of all channels")show_region_attention( image_features.pixel_values, interest_cat.mean(dim=1),)print("strong prompt detractors loss: max of all channels")show_region_attention( image_features.pixel_values, interest_cat.max(dim=1).values,)print("strong prompt detractors loss: boosted max of all channels")show_region_attention( image_features.pixel_values, (interest_cat.max(dim=1).values *100).softmax(dim=2))interest_cat.max()
strong prompt detractors loss: mean of all channels
strong prompt detractors loss: max of all channels
strong prompt detractors loss: boosted max of all channels
tensor(1.1274)
I can keep on fiddling with this for some time. It’s tricky to map the 768 channels to a per-region attention. I’ve had some success and the model seems to favour the eye and the chin of the cat.
If I instead operate over the original pixel values as my optimizable target then the code should be simpler and it should be considerably easier to apply to the source image.
Precise Deoptimization Tracking
This time I am just going to optimize the pixel values directly. Doing this should give a permutation over the three channels directly. I could even visualize the change as a picture itself.
This is not an encouraging start and it shows something of the problem that I wanted to avoid. The convolution layer appears to attend to a very specific area of each region. I can try rerunning this process however I am not hopeful.
import torchwith torch.no_grad(): text_features = processor.tokenizer(["a rendering of a cat."], return_tensors="pt") text_outputs = model.text_model(**text_features) text_embeds = text_outputs[1] # pooler_output text_embeds = model.text_projection(text_embeds)def positive_cat_loss(output: torch.Tensor) -> torch.Tensor: dot_product = torch.matmul(output, text_embeds.T) dot_product[dot_product <=0] =0.return (dot_product **2).sum()interest_cat = pixels_of_interest( processor=processor, model=model, image=image, loss_fn=positive_cat_loss,)print("only cat contributors loss: mean of all channels")show_pixel_attention( image_features.pixel_values, interest_cat.mean(dim=1),)print("only cat contributors loss: max of all channels")show_pixel_attention( image_features.pixel_values, interest_cat.max(dim=1).values,)print("only cat contributors loss: boosted max of all channels")show_pixel_attention( image_features.pixel_values, (interest_cat.max(dim=1).values *100).softmax(dim=2))interest_cat.max()
only cat contributors loss: mean of all channels
only cat contributors loss: max of all channels
only cat contributors loss: boosted max of all channels
tensor(5.7169)
Code
import torchwith torch.no_grad(): text_features = processor.tokenizer(["a rendering of a cat."], return_tensors="pt") text_outputs = model.text_model(**text_features) text_embeds = text_outputs[1] # pooler_output text_embeds = model.text_projection(text_embeds)def strong_cat_loss(output: torch.Tensor) -> torch.Tensor:global text_embeds text_embeds = text_embeds.clone() text_embeds[text_embeds <0.75] =0.return (torch.matmul(output, text_embeds.T) **2).sum()interest_cat = pixels_of_interest( processor=processor, model=model, image=image, loss_fn=strong_cat_loss,)print("strong prompt contributors loss: mean of all channels")show_pixel_attention( image_features.pixel_values, interest_cat.mean(dim=1),)print("strong prompt contributors loss: max of all channels")show_pixel_attention( image_features.pixel_values, interest_cat.max(dim=1).values,)print("strong prompt contributors loss: boosted max of all channels")show_pixel_attention( image_features.pixel_values, (interest_cat.max(dim=1).values *100).softmax(dim=2))interest_cat.max()
strong prompt contributors loss: mean of all channels
strong prompt contributors loss: max of all channels
strong prompt contributors loss: boosted max of all channels
tensor(0.7629)
So this hasn’t worked. The per pixel values are tied too heavily to the specific convolutions that are being done. Furthermore I’m not confident that this approach is the best way in general.
Instead of relying on back propagation to move the regions I need a way that tracks the contribution of each region through the model.
Forward Tracing
I want to be able to determine the influence of each region on the outcome. To do this I need to be able to track the contribution that each region has at each point in the model. This feels like a large task, so I wonder if there is a way to do it in pytorch that preserves information.
The aim would be to express each tensor value as a vector of values where the sum of all of them is the original value. Each individual value of the vector would be the value contribution from a specific region. With a bit of broadcasting wrangling it should be possible to get this working with the original model parameters.
The problem is that the torch code is highly optimized so “merely” patching the tensor type is not going to work out. This may involve reimplementing the attention layers. Luckily the model has very little variation in it, so if I can reimplement one layer then I can reimplement all of them.
To understand what’s involved in reimplementing the model, let’s review the model. The part that we are most concerned about right now is the repeating body of the model, which looks like this:
To be able to trace through this I want to be able to pass in a tensor that has a value which is split between each source region. If I can operate over that by multiplying it by the model parameters appropriately broadcast then I can get the tracing working.
There are the following kinds of operations that need to be replicated:
Linear Layer
Batchwize Matrix Multiplication
View / Transpose / Contiguous
Activation Functions (Softmax / GELU)
Traceable Linear Layer
The majority of these layers are linear. Attention also has some internal operations which are not represented by these modules which will need to be replicated.
A linear layer is a matrix multiplication combined with an addition. The multiplication can be expanded using Einstein summation. Addition needs to be scaled such that it affects each contribution is changed by the appropriate amount. Another approach to addition is to have an additional index which holds such fixed offsets.
linear layer has bias: True
untracked linear: tensor([-0.8449, 0.5872, -0.2979, -0.7776, -0.2705])
einsum linear with bias: tensor([-0.8449, 0.5872, -0.2979, -0.7776, -0.2705])
einsum linear: tensor([ 0.2498, 0.8545, -0.1213, 0.4675, 0.1067])
tracked linear: tensor([ 0.2498, 0.8545, -0.1213, 0.4675, 0.1067])
3d untracked linear: tensor([-0.8449, 0.5872, -0.2979, -0.7776, -0.2705])
3d einsum linear with bias: tensor([-0.8449, 0.5872, -0.2979, -0.7776, -0.2705])
3d einsum linear: tensor([ 0.2498, 0.8545, -0.1213, 0.4675, 0.1067])
3d tracked linear: tensor([ 0.2498, 0.8545, -0.1213, 0.4675, 0.1067])
This approach using einstein summation works with the core operation, the bias needs some special handling.
We can try adding the bias to each value as a flat amount and see if we need to get more complicated later. It may well be that we need to assign bias to the values in accordance with their current value.
Code
import torchfrom torch import nninput_tensor = torch.rand(2, 768)@torch.no_grad()def tracked_linear_with_bias(t: torch.Tensor, linear: nn.Linear) -> torch.Tensor:# 49 values for each region of the input image, sum to 1 per t value t_tracked = track(t) tracking_size = t_tracked.shape[-1] t_mm = torch.einsum("bik,jik->bjk", t_tracked, linear.weight[:, :, None]) t_bias = t_mm + (linear.bias[:, None] / tracking_size)return t_bias.sum(dim=-1)@torch.no_grad()def tracked_linear_with_bias_3d(t: torch.Tensor, linear: nn.Linear) -> torch.Tensor:# 49 values for each region of the input image, sum to 1 per t value t_tracked = track(t) tracking_size = t_tracked.shape[-1] t_mm = torch.einsum("Bbik,Bjik->Bbjk", t_tracked, linear.weight[None, :, :, None]) t_bias = t_mm + (linear.bias[:, None] / tracking_size)return t_bias.sum(dim=-1)print(f"linear layer has bias: {linear_layer.bias isnotNone}")print(f"untracked linear: {untracked_linear(input_tensor, linear_layer)[0, :5]}")print(f"einsum linear with bias: {einsum_linear_with_bias(input_tensor, linear_layer)[0, :5]}")print(f"tracked linear with bias: {tracked_linear_with_bias(input_tensor, linear_layer)[0, :5]}")input_tensor = input_tensor.reshape(1, 2, 768)print(f"tracked linear with bias: {tracked_linear_with_bias_3d(input_tensor, linear_layer)[0, 0, :5]}")
linear layer has bias: True
untracked linear: tensor([-0.6019, 0.5975, -0.1942, -0.9617, -0.5879])
einsum linear with bias: tensor([-0.6019, 0.5975, -0.1942, -0.9617, -0.5879])
tracked linear with bias: tensor([-0.6019, 0.5975, -0.1942, -0.9617, -0.5879])
tracked linear with bias: tensor([-0.6019, 0.5975, -0.1942, -0.9617, -0.5879])
This is good enough to get going with. The assignment of the bias to the values may need work as it will skew the attribution quite heavily.
linear layer has bias: True
untracked linear: tensor([-0.8051, 0.5180, -0.3463, -1.0407, -0.4379])
tracked linear class: tensor([-0.8051, 0.5180, -0.3463, -1.0407, -0.4379])
tracked linear class 3d: tensor([-0.8051, 0.5180, -0.3463, -1.0407, -0.4379])
This works then. The next thing is the batchwize matrix multiplication.
Traceable Batch Matrix Multiplication
Batch matrix multiplication is an adjustment to what we have been doing so far. The difference is that both sides of the multiplication are now tracked.
I’ve tried to get this working with a single einsum operation but the product of the two attributions means that the original values are not preserved. That may not matter when calculating attribution but until I have a working system I am not happy changing the results.
Code
import torchleft_tensor = torch.rand(2, 100, 768, requires_grad=False)right_tensor = torch.rand(2, 768, 100, requires_grad=False)@torch.no_grad()def untracked_bmm(left: torch.Tensor, right: torch.Tensor) -> torch.Tensor:return torch.bmm(left_tensor, right_tensor)@torch.no_grad()def einsum_bmm(left: torch.Tensor, right: torch.Tensor) -> torch.Tensor:return torch.einsum("bnm,bmp->bnp", left, right)@torch.no_grad()def tracked_bmm(left: torch.Tensor, right: torch.Tensor) -> torch.Tensor: left_tracked = track(left) right_tracked = track(right)# kinda horrible here,# but the problem is that the full batch multiplication (i.e. bnmi,bmpi->bnpi over both tracked)# leads to a squaring of the values as the decomposed values are multiplied on both sides# to make this clear, imagine that left_tracked was [0.5, 0.5] and right_tracked was [0.5, 0.5]# if we do a pointwise multiplication of these we get [0.25, 0.25] which sums to 0.5# reversing this scaling effect is tricky as the actual effect depends on the tracking value itself# least squares inverse of the matrix# then use that to find the closest point to the untracked left_bmm = torch.einsum("bnmi,bmpi->bnpi", left_tracked, right.unsqueeze(-1)) right_bmm = torch.einsum("bnmi,bmpi->bnpi", left.unsqueeze(-1), right_tracked) bmm = left_bmm + right_bmm bmm = bmm /2return bmm.sum(dim=-1)print(f"untracked bmm: {untracked_bmm(left_tensor, right_tensor)[0, 0, :5]}")print(f"einsum bmm: {einsum_bmm(left_tensor, right_tensor)[0, 0, :5]}")print(f"tracked bmm: {tracked_bmm(left_tensor, right_tensor)[0, 0, :5]}")
@torch.no_grad()def tracked_bmm_full(left: torch.Tensor, right: torch.Tensor) -> torch.Tensor: left_tracked = track(left) right_tracked = track(right)# kinda horrible here,# but the problem is that the full batch multiplication (i.e. bnmi,bmpi->bnpi over both tracked)# leads to a squaring of the values as the decomposed values are multiplied on both sides# to make this clear, imagine that left_tracked was [0.5, 0.5] and right_tracked was [0.5, 0.5]# if we do a pointwise multiplication of these we get [0.25, 0.25] which sums to 0.5# reversing this scaling effect is tricky as the actual effect depends on the tracking value itself# least squares inverse of the matrix# then use that to find the closest point to the untracked tracked_bmm = torch.einsum("bnmi,bmpi->bnpi", left_tracked, right_tracked) tracked_bmm_ratio = tracked_bmm.abs().sum(dim=-1) true_bmm = torch.einsum("bnm,bmp->bnp", left, right) true_bmm_ratio = true_bmm.abs() scaled_bmm = tracked_bmm * (true_bmm_ratio / tracked_bmm_ratio).unsqueeze(-1)return scaled_bmm.sum(dim=-1)print(f"untracked bmm: {untracked_bmm(left_tensor, right_tensor)[0, 0, :5]}")print(f"tracked bmm: {tracked_bmm_full(left_tensor, right_tensor)[0, 0, :5]}")
This should be more straightforward. The quick GELU operation involves a sigmoid which should be done over the aggregated value, and the effect on the tracing values can be achieved by multiplying them by the resulting value.
Code
import torchfrom torch import nngelu = model.vision_model.encoder.layers[0].mlp.activation_fninput_tensor = torch.rand(2, 768, requires_grad=False)@torch.no_grad()def untracked_gelu(xs: torch.Tensor, activation_fn: nn.Module) -> torch.Tensor:# this is the quick gelu algorithm used by clipreturn activation_fn(xs)@torch.no_grad()def tracked_gelu(xs: torch.Tensor, activation_fn: nn.Module) -> torch.Tensor: xs_tracked = track(xs)# gelu would change a lot if it were run over the tracking parts of the value# so we have to run it on the overall value.# Since it has become the output value, to then apply it back to the tracking values# we need to normalize it.# for example, tracking values of [0.4, 0.4] -> gelu -> 0.8# if we multiply the tracking values by the gelu we get [0.32, 0.32]# but we want the sum to be 0.8, so we divide the gelu value by the sum of the tracking values# [0.4, 0.4] * (0.8 / sum([0.4, 0.4])) -> [0.4, 0.4] gelu = activation_fn(xs) normalized_gelu = gelu / xs xs_tracked = xs_tracked * normalized_gelu.unsqueeze(-1)return xs_tracked.sum(dim=-1)print(f"untracked gelu: {untracked_gelu(input_tensor, gelu)[0, :5]}")print(f"tracked gelu: {tracked_gelu(input_tensor, gelu)[0, :5]}")
This is a very similar approach to the GELU as layer normalization operates over the last two dimensions. So the tracked data needs to be untracked to get the normalized version and then scale the values by that. Since it’s so similar this can use the same TrackingActivation class.
Code
import torchfrom torch import nninput_tensor = torch.rand(2, 768, requires_grad=False)layer_norm = model.vision_model.encoder.layers[0].layer_norm1@torch.no_grad()def untracked_layer_norm(xs: torch.Tensor, norm: nn.LayerNorm) -> torch.Tensor:return norm(xs)@torch.no_grad()def tracked_layer_norm(xs: torch.Tensor, norm: nn.LayerNorm) -> torch.Tensor: xs_tracked = track(xs)# layer normalization operates over the last two dimensions# so if it were run over the tracked values then it would fundamentally change them# instead the scaling approach from gelu will be used layer_norm = untracked_layer_norm(xs, norm) normalized_layer_norm = layer_norm / xs xs_tracked = xs_tracked * normalized_layer_norm.unsqueeze(-1)return xs_tracked.sum(dim=-1)print(f"untracked layer norm: {untracked_layer_norm(input_tensor, layer_norm)[0, :5]}")print(f"tracked layer norm: {tracked_layer_norm(input_tensor, layer_norm)[0, :5]}")
With this we should have a fully traceable encoder. The CLIPEncoder class can have the encoder layers replaced directly and should still work.
Trace CLIP Inference
Now it’s time to trace the cat as it passes through the dataset. We need to generate the traced inputs and then see how they progress as they move through the model.
I’ve cleaned up the code quite a bit and put it all together so we can now see the final result.
Code
# from src/main/python/blog/tracing/v2022/layers.pyfrom typing import Optional, Tupleimport torchfrom torch import nnfrom transformers import CLIPModelfrom transformers.models.clip.modeling_clip import ( CLIPMLP, CLIPAttention, CLIPEncoder, CLIPEncoderLayer, CLIPVisionTransformer,)def load_tracing_image_model( model_name: str="openai/clip-vit-base-patch32",) -> CLIPModel: model = CLIPModel.from_pretrained(model_name) tracing_model = TracingCLIPVisionTransformer( model=model.vision_model, projection=model.visual_projection ) tracing_model.eval()return tracing_modelclass TracingLinear(nn.Module):def__init__(self, linear: nn.Linear) ->None:super().__init__()self.weight = linear.weight[:, :, None]if linear.bias isnotNone:self.bias = linear.bias[:, None]else:self.bias = torch.zeros(self.weight.shape[0], 1)def forward(self, xs: torch.Tensor) -> torch.Tensor:iflen(xs.shape) ==3: mm =self._matrix_multiply_3d(xs)else: mm =self._matrix_multiply_4d(xs)*_, image_regions = xs.shape bias = mm +self.bias / image_regionsreturn biasdef _matrix_multiply_3d(self, xs: torch.Tensor) -> torch.Tensor:return torch.einsum("bik,jik->bjk", xs, self.weight)def _matrix_multiply_4d(self, xs: torch.Tensor) -> torch.Tensor:return torch.einsum("Bbik,Bjik->Bbjk", xs, self.weight[None])class TracingBMM(nn.Module):def forward(self, xs: torch.Tensor, ys: torch.Tensor) -> torch.Tensor: x_untracked = xs.sum(dim=-1) y_untracked = ys.sum(dim=-1) tracked_bmm = torch.einsum("bnmi,bmpi->bnpi", xs, ys) tracked_bmm_ratio = tracked_bmm.abs().sum(dim=-1) true_bmm = torch.einsum("bnm,bmp->bnp", x_untracked, y_untracked) true_bmm_ratio = true_bmm.abs() scaled_bmm = tracked_bmm * (true_bmm_ratio / tracked_bmm_ratio).unsqueeze(-1)return scaled_bmmclass TracingActivation(nn.Module):def__init__(self, activation_function: nn.Module) ->None:super().__init__()self.activation_function = activation_functiondef forward(self, xs: torch.Tensor) -> torch.Tensor: x_untracked = xs.sum(dim=-1)# if the sum is zero then dividing by it will result in nan# x_untracked[x_untracked == 0.0] = 1.0 activation =self.activation_function(x_untracked) normalized_activation = activation / x_untracked# When values are zero after the application of the function then they# have no further contribution. That means we can set the values in xs to zero. normalized_activation[x_untracked ==0.0] =0.0 result = xs * normalized_activation.unsqueeze(-1) mask = normalized_activation.abs() <0.01 result[mask] = (normalized_activation[mask] / xs.shape[-1]).unsqueeze(-1)return resultclass TracingCLIPAttention(nn.Module):"""Multi-headed attention from 'Attention Is All You Need' paper"""def__init__(self, layer: CLIPAttention) ->None:super().__init__()self.layer = layerself.k_proj = TracingLinear(layer.k_proj)self.v_proj = TracingLinear(layer.v_proj)self.q_proj = TracingLinear(layer.q_proj)self.out_proj = TracingLinear(layer.out_proj)self.bmm = TracingBMM()self.softmax = TracingActivation(nn.Softmax(dim=-1))def forward(self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor] =None, causal_attention_mask: Optional[torch.Tensor] =None, output_attentions: Optional[bool] =False, ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:"""Input shape: Batch x Time x Channel x Tracing""" bsz, tgt_len, embed_dim, tracking_dim = hidden_states.size()# get query proj query_states =self.q_proj(hidden_states) *self.layer.scale key_states =self._shape(self.k_proj(hidden_states), -1, bsz, tracking_dim) value_states =self._shape(self.v_proj(hidden_states), -1, bsz, tracking_dim) proj_shape = (bsz *self.layer.num_heads, -1, self.layer.head_dim, tracking_dim) query_states =self._shape(query_states, tgt_len, bsz, tracking_dim).view(*proj_shape ) key_states = key_states.view(*proj_shape) value_states = value_states.view(*proj_shape) src_len = key_states.size(1) attn_weights =self.bmm(query_states, key_states.transpose(1, 2))# code has been cut out here which relates to the# causal_attention_mask, attention_mask and error checkingassert causal_attention_mask isNoneassert attention_mask isNone attn_weights =self.softmax(attn_weights)if output_attentions:# this operation is a bit akward, but it's required to# make sure that attn_weights keeps its gradient.# In order to do so, attn_weights have to reshaped# twice and have to be reused in the following attn_weights_reshaped = attn_weights.view( bsz, self.layer.num_heads, tgt_len, src_len, tracking_dim ) attn_weights = attn_weights_reshaped.view( bsz *self.layer.num_heads, tgt_len, src_len, tracking_dim )else: attn_weights_reshaped =None# this is not intended for training so dropout is removed entirely# attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training) attn_probs = attn_weights attn_output =self.bmm(attn_probs, value_states) attn_output = attn_output.view( bsz, self.layer.num_heads, tgt_len, self.layer.head_dim, tracking_dim ) attn_output = attn_output.transpose(1, 2) attn_output = attn_output.reshape(bsz, tgt_len, embed_dim, tracking_dim) attn_output =self.out_proj(attn_output)return attn_output, attn_weights_reshapeddef _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int, tracking_dim: int):return ( tensor.view( bsz, seq_len, self.layer.num_heads, self.layer.head_dim, tracking_dim ) .transpose(1, 2) .contiguous() )class TracingCLIPMLP(nn.Module):def__init__(self, layer: CLIPMLP) ->None:super().__init__()self.activation_fn = TracingActivation(layer.activation_fn)self.fc1 = TracingLinear(layer.fc1)self.fc2 = TracingLinear(layer.fc2)def forward(self, hidden_states: torch.Tensor) -> torch.Tensor: hidden_states =self.fc1(hidden_states) hidden_states =self.activation_fn(hidden_states) hidden_states =self.fc2(hidden_states)return hidden_statesclass TracingCLIPEncoderLayer(nn.Module):def__init__(self, layer: CLIPEncoderLayer) ->None:super().__init__()self.self_attn = TracingCLIPAttention(layer.self_attn)self.layer_norm1 = TracingActivation(layer.layer_norm1)self.mlp = TracingCLIPMLP(layer.mlp)self.layer_norm2 = TracingActivation(layer.layer_norm2)def forward(self, hidden_states: torch.Tensor, attention_mask: Optional[torch.Tensor], causal_attention_mask: Optional[torch.Tensor], output_attentions: bool, ) -> torch.Tensor: residual = hidden_states hidden_states =self.layer_norm1(hidden_states) hidden_states, attn_weights =self.self_attn( hidden_states=hidden_states, attention_mask=attention_mask, causal_attention_mask=causal_attention_mask, output_attentions=output_attentions, ) hidden_states = residual + hidden_states residual = hidden_states hidden_states =self.layer_norm2(hidden_states) hidden_states =self.mlp(hidden_states) hidden_states = residual + hidden_states outputs = (hidden_states,)if output_attentions: outputs += (attn_weights,)return outputsclass TracingCLIPVisionTransformer(nn.Module):def__init__(self, model: CLIPVisionTransformer, projection: nn.Linear) ->None:super().__init__()self.embeddings = model.embeddings# misspelling present in modelself.pre_layernorm = TracingActivation(model.pre_layrnorm)self.encoder = CLIPEncoder(model.encoder.config)self.encoder.layers = nn.ModuleList( [TracingCLIPEncoderLayer(layer) for layer in model.encoder.layers] )self.post_layernorm = TracingActivation(model.post_layernorm)self.visual_projection = TracingLinear(projection)def forward(self, pixel_values: Optional[torch.Tensor] =None) -> torch.Tensor: embeddings =self.embeddings(pixel_values=pixel_values) _, image_regions, _ = embeddings.shape embeddings_traced = torch.zeros(*embeddings.shape, image_regions, device=embeddings.device )for i inrange(image_regions): embeddings_traced[:, i, :, i] = embeddings[:, i, :] embeddings_normalized =self.pre_layernorm(embeddings_traced) encoded =self.encoder( inputs_embeds=embeddings_normalized, output_attentions=False, output_hidden_states=False, return_dict=False, ) encoded = encoded[0] encoded = encoded[:, 0, :] encoded =self.post_layernorm(encoded)returnself.visual_projection(encoded)
This shape is the original 1 (one image) 512 (image embedding) shape with the additional 50 image regions from the embedding. The 0 index is the class embeddings, so that doesn’t correspond to any region of the image. Patches of the image come after so we can now try to correlate what it is paying attention to in the image with the image itself.
The original embedding indices of interest were:
index
value
92
-7.000749
98
-1.338176
198
-1.162172
258
-1.042850
389
-1.041473
index
value
321
1.693858
39
1.293888
376
1.234921
Looking at 92 first, we are looking for the input regions with a negative value:
When reviewing this the most important thing is the degree to which this has faithfully tracked the activations as they pass through the image. I’ve had to adjust some aspects of the tracing calculation both for correctness (divide by zero) and mathematical simplicity (multiplication of two tracked matricies). These changes are likely to lead to compounding differences between the original outputs and the new ones.
This shows me that the tracing has unfortunately lost it’s way. The difference between the original output and the traced output is significant so unfortunately these results are not reliable.