Reviewing a paper on Blocking Adverts based on image content
image classification
Published
November 29, 2022
I recently read a paper about using deep learning to block images containing adverts (Din et al. 2019). The novelty of the paper appears to be the specific classification domain, the size of the model (very small at 1.76MB), and the integration of the blocker directly into the browser. Given that the image classifier seems quite simple (a variant of SqueezeNet (Iandola et al. 2016)) which is quite old now, I wonder if I can reproduce this using CLIP.
Din, Zain ul abi, Panagiotis Tigas, Samuel T. King, and Benjamin Livshits. 2019. “Percival: Making in-Browser Perceptual Ad Blocking Practical with Deep Learning.” arXiv. https://doi.org/10.48550/ARXIV.1905.07444.
Iandola, Forrest N., Song Han, Matthew W. Moskewicz, Khalid Ashraf, William J. Dally, and Kurt Keutzer. 2016. “SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and ≪0.5MB Model Size.” arXiv. https://doi.org/10.48550/ARXIV.1602.07360.
The first thing to do will be to collect the dataset. Then I can try clustering it using the CLIP embeddings to find out how many separate classifiers I should use. Finally I can evaluate the classifier embeddings against a separate dataset.
Dataset
One problem is that the dataset does not seem to be available. I’ve found a dataset of 64,832 adverts in the Pitt Image Ads Dataset (can’t seem to find citation, it’s by Adriana Kovashka and is available here). I can use this with the open images dataset that I already have.
Let’s have a look at one of the images first:
Code
from pathlib import PathADVERT_FOLDER = Path("/data/image/pitt_adverts/image/")ADVERT_IMAGES =sorted(ADVERT_FOLDER.glob("*/*"))DATA_FOLDER = Path("/data/blog/2022/11/29/perceptual-adblocking")DATA_FOLDER.mkdir(exist_ok=True, parents=True)
Code
from pathlib import Pathfrom PIL import ImageImage.open(ADVERT_IMAGES[0])
My real dataset is the embeddings for all of these images. Let’s create them.
from tqdm.auto import tqdmimport pandas as pdadvert_embedding_df = pd.DataFrame([ {"file": str(file.relative_to(ADVERT_FOLDER)),"embedding": calculate_embedding(file), }forfilein tqdm(ADVERT_IMAGES)])advert_embedding_df.to_parquet(DATA_FOLDER /"advert-embeddings.gz.parquet", compression="gzip")advert_embedding_df
file
embedding
label
0
0/10000.jpg
[0.15955794, 0.12757635, -0.1171277, -0.125003...
0
1
0/100000.jpg
[-0.26774788, -0.18349923, 0.03581748, 0.01433...
0
2
0/100010.jpg
[-0.54049927, -0.0582103, -0.32849184, -0.2700...
1
3
0/100040.jpg
[-0.63116956, -0.1476591, -0.035523407, -0.383...
0
4
0/100060.jpg
[-0.18007469, 0.18109158, 0.054699436, 0.22198...
1
...
...
...
...
64827
9/99899.jpg
[-0.17220578, 0.056135595, -0.054074608, -0.41...
0
64828
9/99959.jpg
[0.15200219, -0.09595037, -0.08600271, 0.65402...
2
64829
9/99969.jpg
[-0.20257103, -0.38640052, 0.14894253, -0.1454...
1
64830
9/99979.jpg
[0.022974648, -0.5470357, -0.22149833, -0.1679...
2
64831
9/99989.jpg
[0.1348732, -0.54329157, 0.16097397, 0.3252397...
1
64832 rows × 3 columns
Clustering
The next thing is to try to define embeddings that can be used to identify the adverts. A nice way to do this is to cluster the embeddings and use the cluster centroids as classifiers - if a new embedding is near to a cluster centroid then we can label the image as an advert.
With CLIP the normal way to measure label / image similarity is to use cosine similarity. SKLearn can be used to create KMeans clusters. If the embeddings are normalized then the KMeans clusters will be defined over the cosine similarity of the embeddings.
To work with this we must ensure that the embeddings are normalized, as that will make the mean square metric into the cosine similarity metric for KMeans.
from sklearn import preprocessingimport numpy as npX = np.array(advert_embedding_df.embedding.tolist())X = preprocessing.normalize(X)(X*X).sum(axis=1).mean()
1.0
KMeans is nice however to use it we have to know how many clusters are present in the data. If we visualize it we might have an idea. I’ve used PCA and T-SNE before to do this so let’s use them again.
Code
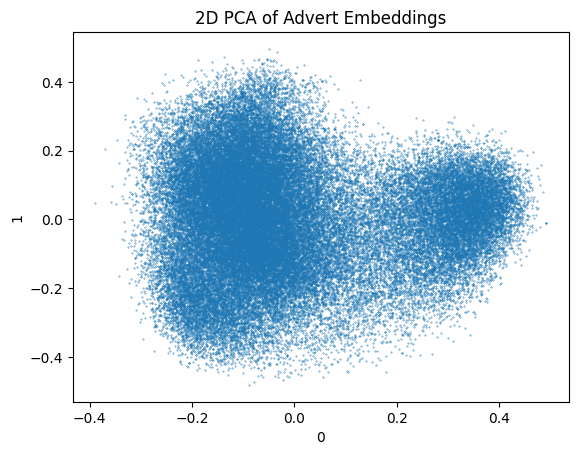
from sklearn.decomposition import PCApca_output = PCA( n_components=2, random_state=0,).fit_transform(X)pca_df = pd.DataFrame(pca_output)pca_df.plot.scatter( title="2D PCA of Advert Embeddings", x=0, y=1, s=0.1,) ;None
Code
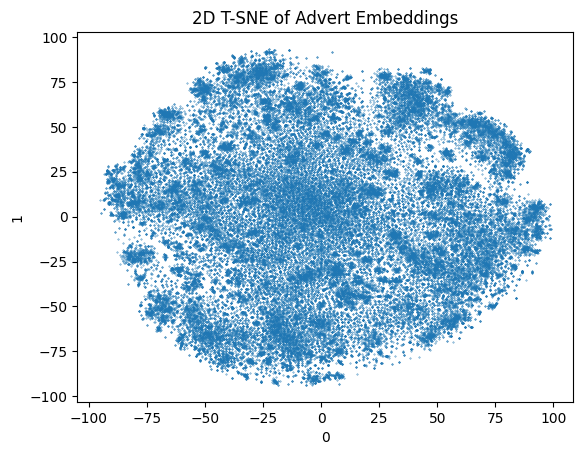
from sklearn.decomposition import PCAfrom sklearn.manifold import TSNEimport numpy as npn_components =2# doing this to avoid the warning about future T-SNEtsne_init = ( PCA( n_components=n_components, svd_solver="randomized", random_state=0, ) .fit_transform(X) .astype(np.float32, copy=False))tsne_output = TSNE( n_components=n_components, learning_rate="auto", init=tsne_init,).fit_transform(X)tsne_df = pd.DataFrame(tsne_output)tsne_df.plot.scatter( title="2D T-SNE of Advert Embeddings", x=0, y=1, s=0.1,) ;None
Here we can see that the PCA visualization has not clearly separated the points. There is perhaps two clusters in that. T-SNE is significantly slower and shows far more variation in the data. There could be hundreds of distinct clusters in that.
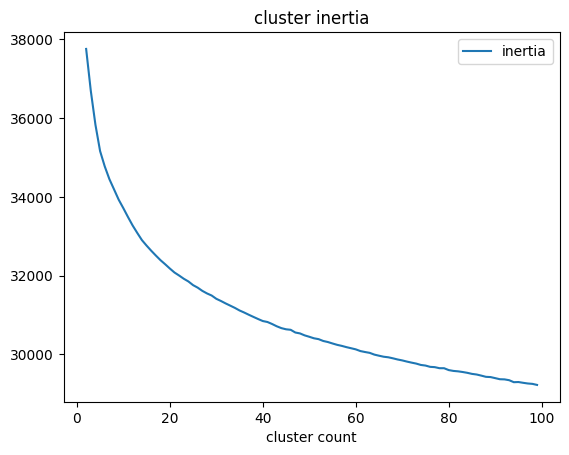
Another way to determine the cluster count is to use the elbow method, where you plot the distortion and inertia. Distortion is the mean of the squared distance for each point to the center of the cluster. Inertia is the sum of the squared distance for each point to the center of the nearest other cluster. The “elbow” comes from the point in the graph where the rate of change of these values suddenly changes.
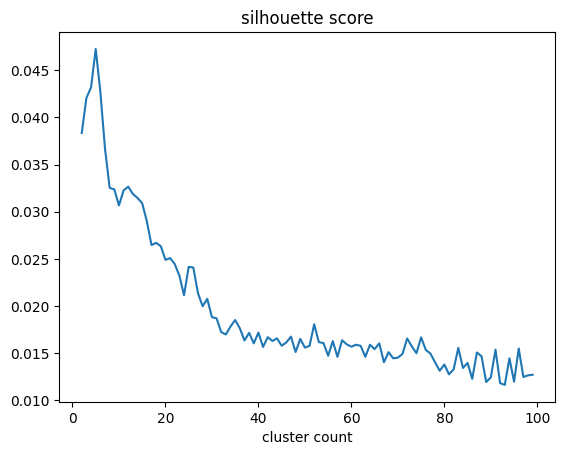
I’ve recently heard of the silhouette score which is a metric based on the distortion and inertia. You can calculate it for each cluster count and then take the count with the highest number. I like this as it automates the elbow.
The silhouette method suggests that there are 5 clusters, while the elbow method is less conclusive. I was expecting more as the original CLIP paper used 80 templates per class.
The next thing to do is to make a classifier out of this and see how many of the open images get classified as adverts.
One problem with this is that the different clusters may have different variance. I want to be able to train a classification head using these centroids as a starting point. Then the bias over that linear layer can be used to set the size of the cluster.
Classifying
With a classification layer that uses the centroids as the starting weights how well can I classify this existing dataset? I can create a model which uses the CLIP stages first to produce the embedding, then uses a linear layer to classify the image into one of the 5 clusters. This linear layer can be initialized with the cluster centroids that we have just calculated.
A model structured in this way should work as the linear layer is reproducing the dot product. If we want to recreate cosine similarity exactly then normalizing the model output prior to the linear layer will do this. Otherwise we can use an adjusted sigmoid following the classification, and in this way the range of output remains -1 to 1 in both cases.
We can now see what this classifier would produce without any training. The only thing that is untrained is the bias, which tends to be low to start with.
The dataset for these is then the desired output class and the embeddings. We know that the embeddings come directly from CLIP output, so running CLIP again doesn’t add much value.
The first thing to do is to define a loss function. This will control how the optimizer updates the bias of the classifier, so it is the most important thing to get right.
I have written this loss function to adhere to these principles:
We can use sigmoid to map the outputs to a fixed range (will adjust it to be -1 to 1).
For an advert we are only concerned with the output of the cluster index, that must be positive. Closer to 1 is better.
For a non advert we want all outputs to be negative. Closer to -1 is better.
We have an equal number of non adverts as adverts, so we don’t want a non advert to have more influence over the model than an advert.
So the non advert will consider a random output instead of all of the outputs.
Code
from typing import Callableimport torchLossFunction = Callable[[torch.Tensor, torch.Tensor], torch.Tensor]def absolute_loss(outputs: torch.Tensor, labels: torch.Tensor) -> torch.Tensor:""" This wants to move the outputs to +1 or -1. For a negative row one target is chosen at random to update. """ labels = labels.clone() batch_size, label_count = outputs.shape indexes = labels index_mask = indexes ==-1# target is the desired output value targets = torch.ones_like(indexes, device=outputs.device) targets[index_mask] *=-1# where the correct output is -1, we choose a random output index to test# this ensures that one negative example has the same influence as one positive example# and it provides a similar influence over the bias values indexes[index_mask] = torch.randint( low=0, high=label_count, size=(index_mask.sum(),), device=outputs.device, ) outputs = outputs[range(batch_size), indexes]# the loss is based on the difference between the target and the output# this doesn't compare across all of the outputs at any point (which would allow cross entropy)# that is because if the image is an advert then it is fine for any output to be positive,# so other indices that are positive should not be punished loss = targets - outputs loss = loss**2 loss = loss.sum()return loss
Next is to define a training loop and metric. This is quite verbose, normally we would be using the huggingface trainer however this is quite a specific task and doesn’t really fit into that.
This adds the normalization to the model before the linear layer. Doing this makes the output of the linear layer the cosine similarity of the cluster centroids and the current embedding.
/home/matthew/.local/share/virtualenvs/blog-1tuLwbZm/lib/python3.10/site-packages/torch/optim/lr_scheduler.py:156: UserWarning: The epoch parameter in `scheduler.step()` was not necessary and is being deprecated where possible. Please use `scheduler.step()` to step the scheduler. During the deprecation, if epoch is different from None, the closed form is used instead of the new chainable form, where available. Please open an issue if you are unable to replicate your use case: https://github.com/pytorch/pytorch/issues/new/choose.
warnings.warn(EPOCH_DEPRECATION_WARNING, UserWarning)
with torch.inference_mode(): output = classifier.infer(OPENIMAGES_FOLDER / openimages_embedding_df.iloc[0].file)print(f"predictions: {output[0]}")print("no image cluster")
predictions: tensor([ 0.0059, -0.1296, -0.0508, -0.2039, -0.2314])
no image cluster
This is interesting. The training results in decreasing accuracy which I can’t seem to figure out. When running it over those two images the non advert image has been incorrectly classified.
Train without Normalization
This does not add the normalization to the model before the linear layer. When creating a model it can be good to avoid too much manipulation as that reduces the amount that the model can adjust itself. Let’s see if this works better.
/home/matthew/.local/share/virtualenvs/blog-1tuLwbZm/lib/python3.10/site-packages/torch/optim/lr_scheduler.py:156: UserWarning: The epoch parameter in `scheduler.step()` was not necessary and is being deprecated where possible. Please use `scheduler.step()` to step the scheduler. During the deprecation, if epoch is different from None, the closed form is used instead of the new chainable form, where available. Please open an issue if you are unable to replicate your use case: https://github.com/pytorch/pytorch/issues/new/choose.
warnings.warn(EPOCH_DEPRECATION_WARNING, UserWarning)
with torch.inference_mode(): output = classifier.infer(OPENIMAGES_FOLDER / openimages_embedding_df.iloc[0].file)print(f"predictions: {output[0]}")print("no image cluster")
predictions: tensor([-0.4785, -0.7180, -0.3558, -0.5442, -0.6286])
no image cluster
Now the model is able to marginally improve the accuracy of the predictions. It does correctly classify both of the images this time. This isn’t working as well as I had hoped.
Linear Regression
This is a simple task really. I think of the bias as the radius of the cluster associated with the centroid. As the bias becomes more negative the boundary of the cluster moves closer to the centroid.
So if it is this simple then can I could just try generating both the weights and the bias with a linear regressor. As I’m prone to overcomplication, and I want to test this against the complicated pytorch trained version, I am going to try linear regression against the different combinations of centroids and bias. A massive code block follows…
To start with we can recreate the pytorch model by operating only over the bias. This involves performing the dot product over the embeddings and centroids and regressing over the resulting value.
A clearly terrible result. The model is just predicting that everything is an advert.
Linear Regression - Centroid Only
This time the bias will be discarded entirely and the calculated centroids ignored. Instead the linear regressor will calculate the new centroids to use.
This is a substantial improvement as it is actually trying to classify both classes. The overall accuracy is in line with the pytorch version.
Linear Regression - Centroid and Bias
Now we can use the full power of linear regression, as it is able to calculate an intercept for the data which is the bias from the torch linear layer.
This is a substantial result. It’s a lot more accurate than the pytorch version. To be fair that was unable to train the centroids themselves so it is not really a fair comparison.
However, when investigating this I found something unusual:
This is clearly an excellent result. It’s very strange that training the bias results in a near perfect classifier when we ignore that calculated bias.
It’s also interesting to me that the individual classifiers are each dramatically weaker but combine to form a near perfect classifier. Since this is a remarkable result we must be extra careful when double checking the results.
Manual Evaluation
Now we can look at the best and worst classified images. This evaluation will be looking at the train and test images, so it’s not a perfect evaluation. Ideally I would have a dataset for this evaluation that comes from a separate source.
We can start by looking at the advert images.
from PIL import Imageimport numpy as npadvert_predictions = np.array(advert_embedding_df.embedding.tolist()) @ linear_layer.Tadvert_predictions = advert_predictions.max(axis=1)print(f"overall accuracy of: {(advert_predictions >0).astype(float).sum() /len(advert_embedding_df):0.3f}")print(f"total misclassified: {(advert_predictions <=0).astype(int).sum():,} of {len(advert_embedding_df):,}")
overall accuracy of: 0.989
total misclassified: 715 of 64,832
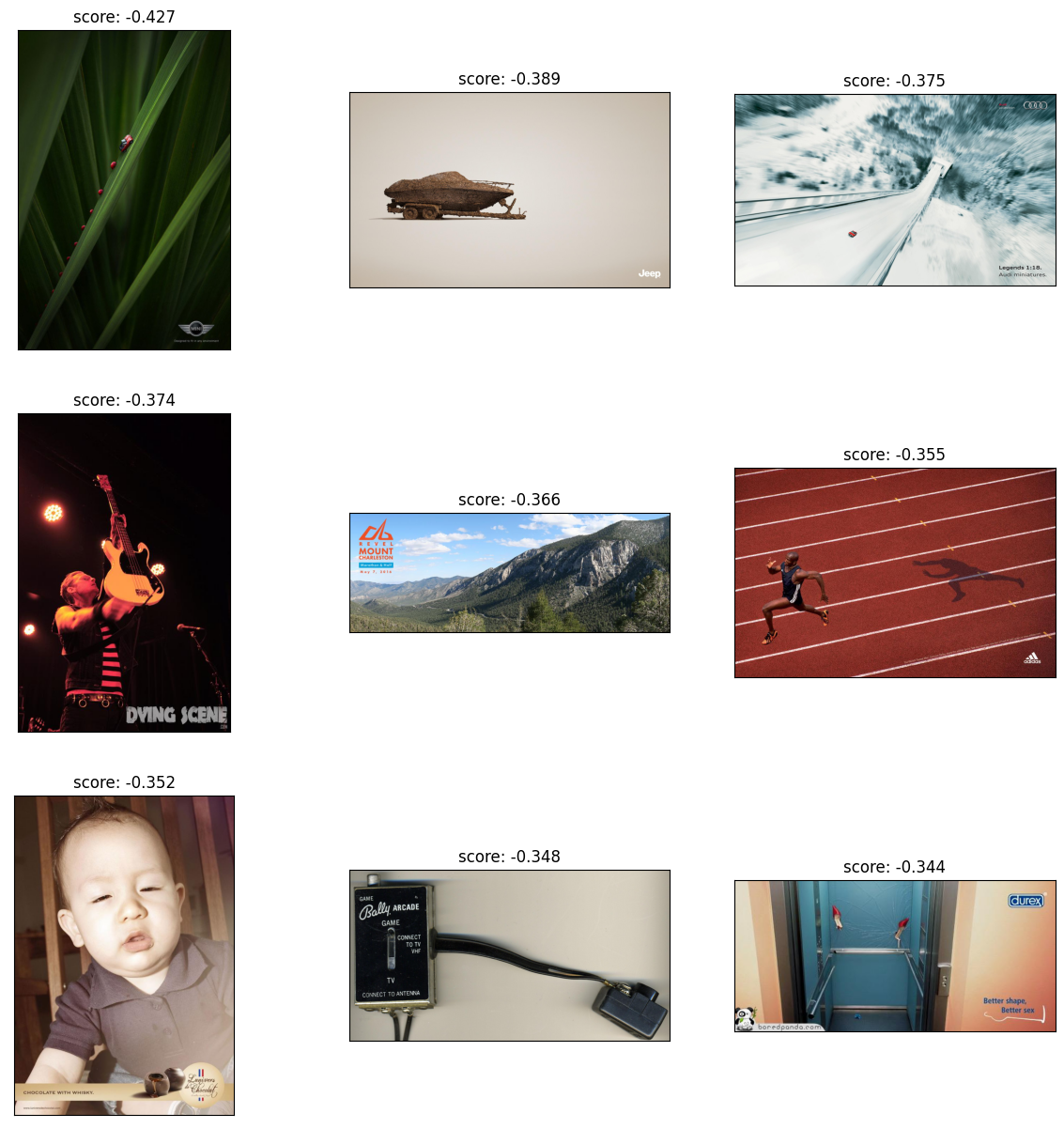
Now we can test the classifier with the open images dataset. We will start by looking at the misclassified images. This time it is the images that have the highest maximum score.
from PIL import Imageimport numpy as npnon_advert_predictions = np.array(openimages_embedding_df.embedding.tolist()) @ linear_layer.Tnon_advert_predictions = non_advert_predictions.max(axis=1)print(f"overall accuracy of: {(non_advert_predictions <=0).astype(float).sum() /len(openimages_embedding_df):0.3f}")print(f"total misclassified: {(non_advert_predictions >0).astype(int).sum():,} of {len(openimages_embedding_df):,}")
overall accuracy of: 0.949
total misclassified: 3,322 of 64,832
Here we can see that the misclassified images are either adverts or strongly resemble adverts. Is this really a misclassification or is it a problem with the dataset?
The next thing is to review the best classifications, those images with the lowest maximum score.
These images are not adverts and have some variation which is nice.
Broadly though there is clearly a problem with the open images dataset. It contains adverts. The dataset was sourced from the internet and I understood it to be primarily user generated content. It seems surprising to me that individuals would include adverts, but here we are.
While these overall results are slightly weaker than the test set suggested the evaluation seems solid. I’m happy with how this went.