(He et al. 2017 )
Data Cleaning
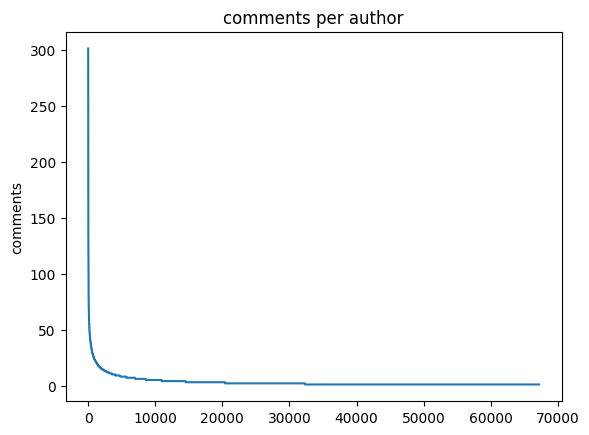
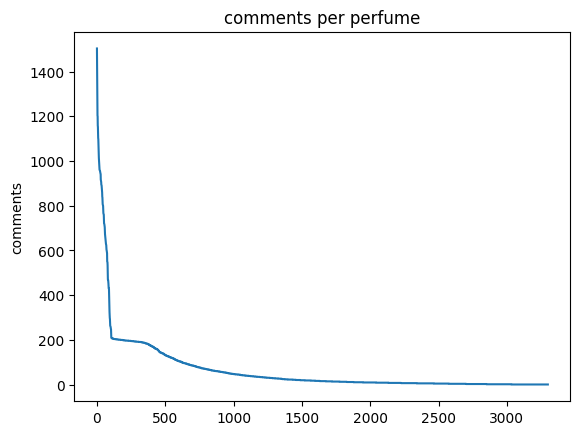
The comment data for the perfumes is nice and has been analysed for sentiment already. However the number of comments that each individual has given varies quite substantially.
In the movielens dataset each reviewer has reviewed at least 20 movies. That makes sure that there is enough data to train the reviewer embeddings on. Lets see if we can come up with a similar threshold for the perfumes and commenters.
The first thing to do is to look at the distribution of comments.
Code
import pandas as pd= pd.read_parquet("/data/perfumes/processed/comments.gz.parquet" )"comment_length" ] = comments_df.content.str .strip().str .len ()= comments_df[comments_df.comment_length > 0 ]= comments_df.sort_values(by= "comment_length" , ascending= False )= comments_df.drop_duplicates(= ["object_id" , "author_id" ],= "first" # keep longest comment = True )= "comments per author" ,= "comments" ,= False ,= True )= "comments per perfume" ,= "comments" ,= False ,; None
We can see here that the commenter or perfume count drops of rapidly. This distribution is quite typical as the most popular perfumes are more visible on the site leading to more comments.
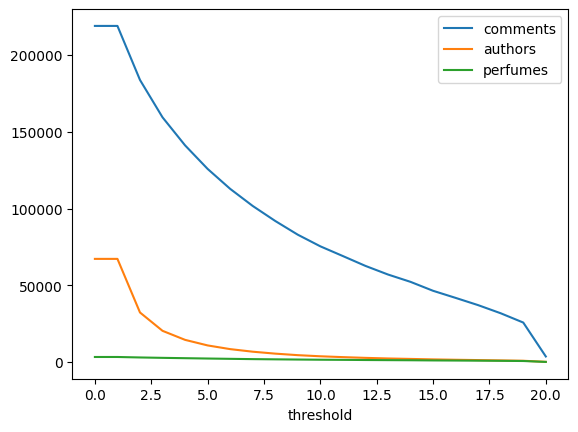
Is there a suitable threshold that we can use to make sure there is enough data per perfume or commenter? Let’s try checking a few thresholds.
Code
import pandas as pddef threshold(df: pd.DataFrame, count: int ) -> pd.DataFrame:def subset(values: pd.Series) -> set [str ]:= values.value_counts()return set (counts[counts >= count].index)= None while last_size != len (df):= len (df)= subset(df.author_name)= subset(df.object_id)= df[df.author_name.isin(authors) & df.object_id.isin(perfumes)]= df.reset_index(drop= True )"author_name" ] = df.author_name.astype("category" )"object_id" ] = df.object_id.astype("category" )return dfdef threshold_stats(df: pd.DataFrame, count: int ) -> dict := threshold(df= df, count= count)= len (df.author_name.unique())= len (df.object_id.unique())return {"threshold" : count,"comments" : len (df),"authors" : author_count,"perfumes" : perfume_count,= pd.DataFrame([= comments_df, count= count)for count in range (21 )"threshold" )5 , 10 , 20 ]]
comments
authors
perfumes
threshold
5
125836
10834
2296
10
75394
3760
1517
20
3635
137
85
Using the movielens threshold of 20 would destroy this dataset. I think that a threshold of 5 or 10 is achievable as there is still enough data to make this interesting.
Code
= threshold(df= comments_df, count= 5 )= threshold(df= comments_df, count= 10 )
We then need a target value to train against. Each comment has been through a sentiment model to determine the overall sentiment of the comment. I am going to use this as a proxy for the commenters preference.
To train collaborative filters I need a single value expressing this. Keeping the process simple should help. * The target value is between -1 and 1 * If the sentiment is negative then the target is -1 * If the sentiment is neutral then the target is 0 * If the sentiment is positive then the target is 1
This scale is nice because tanh can be applied to the output of the model to scale it to this range.
Code
import pandas as pd"target_class" ] = comments_5_df[["negative" , "neutral" , "positive" ]].T.idxmax()"target" ] = comments_5_df.target_class.map ({"negative" : - 1.0 ,"neutral" : 0. ,"positive" : 1.0 ,"target_class" ] = comments_10_df[["negative" , "neutral" , "positive" ]].T.idxmax()"target" ] = comments_10_df.target_class.map ({"negative" : - 1.0 ,"neutral" : 0. ,"positive" : 1.0 ,"threshold 5" : comments_5_df.target_class.value_counts() / len (comments_5_df),"threshold 10" : comments_10_df.target_class.value_counts() / len (comments_10_df)"negative" , "neutral" , "positive" ]]
threshold 5
threshold 10
target_class
negative
0.375799
0.396610
neutral
0.113688
0.108351
positive
0.510514
0.495039
These are similar distributions and neutral is rarely expressed. It may well be that we can combine this with negative as a neutral review of a perfume is not an endorsement and that would make these datasets nearly balanced.
The final thing is to split these into test and train datasets. Comments have a date so taking the most recent comment by each user would produce a 20% or 10% test dataset which is systematic.
Code
import pandas as pddef test_train_split_idx(df: pd.DataFrame) -> (pd.Index, pd.Index):= (= "date" , ascending= False )= ["author_name" ], keep= "first" )= set (most_recent.index)= df[~ df.index.isin(recent_index)]return most_recent.index, without_most_recent.index
Code
import pandas as pd= test_train_split_idx(comments_5_df)= test_train_split_idx(comments_10_df)"threshold" : 5 , "test size" : len (comments_5_test_idx), "train size" : len (comments_5_train_idx)},"threshold" : 10 , "test size" : len (comments_10_test_idx), "train size" : len (comments_10_train_idx)},"threshold" )
test size
train size
threshold
5
10834
115002
10
3760
71634
SciKit Learn
I’ve done this sort of training before. These models are dramatically simpler than what I usually use, and their performance heavily depends on the choice of hyperparameters. Given that it might be a good time to try out structuring this code as a sklearn estimator.
If this code is structured in that way then it is possible to perform a grid search over the hyperparameters. Let’s start by defining the structure of such an estimator.
Code
from dataclasses import dataclassfrom typing import TypedDict, Optionalfrom tqdm.auto import tqdmfrom torch.utils.data import DataLoader, Datasetfrom torch import nnimport torchimport pandas as pdimport numpy as npfrom sklearn.base import BaseEstimator= {"sgd" : torch.optim.SGD,"adam" : torch.optim.Adam,class Entry(TypedDict):str int float @dataclass class CommentDataset(Dataset):def __post_init__(self ) -> None :self .df = self .df.reset_index(drop= True )def __len__ (self ) -> int :return len (self .df)def __getitem__ (self , index) -> Entry:return {"user" : self .df.author_name.cat.codes[index],"product" : self .df.object_id.cat.codes[index],"target" : self .df.target[index],class CollaborativeEstimator(BaseEstimator):def __init__ (self ,float ,int ,int ,str ,str ,-> None :self .learning_rate = learning_rateself .epochs = epochsself .batch_size = batch_sizeself .optimizer = optimizerself .device = deviceself .model = None def _create_model(self ) -> nn.Module:raise NotImplementedError ()def fit(self , X, y, quiet: bool = True ) -> None := pd.DataFrame(X)"target" ] = yself .model = self .train(train_df= df, quiet= quiet)@torch.inference_mode ()def predict(self , X) -> np.array:assert self .model is not None , "fit the model first" = X.author_name.cat.codes.tolist()= X.object_id.cat.codes.tolist()self .model.eval ()= [self .model(= torch.tensor(users[index:index+ self .batch_size]),= torch.tensor(products[index:index+ self .batch_size]),for index in range (0 , len (users), self .batch_size)return np.concatenate(predictions)def train(self , train_df: pd.DataFrame, test_df: Optional[pd.DataFrame] = None , quiet: bool = True ) -> nn.Module:= DataLoader(= CommentDataset(train_df),= self .batch_size,= True ,if test_df is not None := DataLoader(= CommentDataset(test_df),= self .batch_size,= False ,else := None = self ._create_model()self .device)= optimizer_fn[self .optimizer](= self .learning_rate,for epoch in tqdm(range (self .epochs), disable= quiet):= self ._train_iter(model= model, optimizer= optimizer, dl= train_dl, quiet= quiet)/= len (train_df)if test_dl is not None := self ._test_iter(model= model, dl= test_dl) / len (test_df)if not quiet:print (f"epoch { epoch:02d} : train loss { train_loss:0.4f} , test loss { test_loss:0.4f} " )elif not quiet:print (f"epoch { epoch:02d} : train loss { train_loss:0.4f} " )eval ()return modeldef _train_iter(self , model: nn.Module, optimizer: torch.optim.Optimizer, dl: DataLoader, quiet: bool ) -> float := 0. for batch in tqdm(dl, disable= quiet, leave= False ):= batch["user" ].to(self .device)= batch["product" ].to(self .device)= batch["target" ].to(self .device)= model(users= users, products= products)= (output - targets)** 2 += loss.sum ().item()= loss.mean()return train_loss@torch.inference_mode ()def _test_iter(self , model: nn.Module, dl: DataLoader, quiet: bool ) -> float :eval ()= 0. for batch in tqdm(test_dl, disable= quiet, leave= False ):= batch["user" ].to(self .device)= batch["product" ].to(self .device)= batch["target" ].to(self .device)= model(users= users, products= products)= model(users= users, products= products)= (output - targets)** 2 += loss.sum ().item()return test_loss
This implementation lacks a key part - the _create_model method. I also need to ensure that this can work with a custom data split. Let’s try it out with a trivial model.
This model takes a single hyperparameter that it will return as the score.
Code
from dataclasses import dataclassfrom torch import nnimport torch@dataclass class FixedConfig:float class FixedModel(nn.Module):def __init__ (self , config: FixedConfig) -> None :super ().__init__ ()self .config = config# need a parameter to train self .score = nn.Parameter(torch.ones(1 ) * config.score)def forward(self , users: torch.IntTensor, products: torch.IntTensor) -> torch.Tensor:return torch.ones(users.shape[0 ]) * self .scoreclass FixedEstimator(CollaborativeEstimator):def __init__ (self ,float ,float ,int ,int ,str ,str ,-> None :super ().__init__ (= learning_rate,= epochs,= batch_size,= optimizer,= device,self .score = scoredef _create_model(self ) -> nn.Module:= FixedConfig(score= self .score)return FixedModel(config)
We can then try this out. The aim here is to make sure that the model is trained the correct number of times with the correct dataset.
Code
from sklearn.model_selection import GridSearchCVfrom sklearn.metrics import mean_absolute_error, make_scorer= {"score" : [- 1 , - 0.5 , 0 , 0.5 , 1 ],= FixedEstimator(= 0.0 ,= 0.0 , # disable changing the score = 1 ,= 64 ,= "sgd" ,= "cpu" ,= GridSearchCV(= base_estimator,= parameter_grid,=- 1 ,= make_scorer(mean_absolute_error, greater_is_better= False ),= [(comments_5_train_idx, comments_5_test_idx)],= "raise" ,= comments_5_df[["object_id" , "author_name" ]],= comments_5_df["target" ],
GridSearchCV(cv=[(Index([ 0, 1, 2, 4, 5, 6, 7, 8, 10,
11,
...
125826, 125827, 125828, 125829, 125830, 125831, 125832, 125833, 125834,
125835],
dtype='int64', length=115002),
Index([ 6997, 106583, 2096, 99857, 75533, 116425, 103546, 91366, 20675,
46071,
...
89531, 12221, 71600, 102132, 111257, 87469, 124689, 110351, 77345,
115926],
dtype='int64', length=10834))],
error_score='raise',
estimator=FixedEstimator(batch_size=64, device='cpu', epochs=1,
learning_rate=0.0, optimizer='adam',
score=0.0),
n_jobs=-1, param_grid={'score': [-1, -0.5, 0, 0.5, 1]},
scoring=make_scorer(mean_absolute_error, greater_is_better=False)) In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. GridSearchCV GridSearchCV(cv=[(Index([ 0, 1, 2, 4, 5, 6, 7, 8, 10,
11,
...
125826, 125827, 125828, 125829, 125830, 125831, 125832, 125833, 125834,
125835],
dtype='int64', length=115002),
Index([ 6997, 106583, 2096, 99857, 75533, 116425, 103546, 91366, 20675,
46071,
...
89531, 12221, 71600, 102132, 111257, 87469, 124689, 110351, 77345,
115926],
dtype='int64', length=10834))],
error_score='raise',
estimator=FixedEstimator(batch_size=64, device='cpu', epochs=1,
learning_rate=0.0, optimizer='adam',
score=0.0),
n_jobs=-1, param_grid={'score': [-1, -0.5, 0, 0.5, 1]},
scoring=make_scorer(mean_absolute_error, greater_is_better=False))
Code
{'mean_fit_time': array([10.15469885, 9.80105376, 10.18585205, 10.24359465, 9.83500171]),
'std_fit_time': array([0., 0., 0., 0., 0.]),
'mean_score_time': array([0.00424838, 0.00418973, 0.00426602, 0.00428987, 0.00427222]),
'std_score_time': array([0., 0., 0., 0., 0.]),
'param_score': masked_array(data=[-1, -0.5, 0, 0.5, 1],
mask=[False, False, False, False, False],
fill_value='?',
dtype=object),
'params': [{'score': -1},
{'score': -0.5},
{'score': 0},
{'score': 0.5},
{'score': 1}],
'split0_test_score': array([-1.13716079, -0.99843087, -0.85970094, -0.86127008, -0.86283921]),
'mean_test_score': array([-1.13716079, -0.99843087, -0.85970094, -0.86127008, -0.86283921]),
'std_test_score': array([0., 0., 0., 0., 0.]),
'rank_test_score': array([5, 4, 1, 2, 3], dtype=int32)}
The results here show me that there were 5 models evaluated which each had a score parameter. Those 5 models have scores tracked by the splitN_test_score values, which only has a single entry. This shows that the cv split I passed in was respected.
The score itself is negative, which surprised me. It turns out that using a loss function and greater_is_better results in the scorer negating the underlying score, so that the grid search can still use the behaviour of maximizing the score.
The best estimator is available as the grid.estimator, so we can check that it returns a fixed value.
Code
10 ))
AssertionError: fit the model first
It looks like it has initialized the model but not trained it!
Let’s try that and then evaluate it.
Code
= comments_5_df.loc[comments_5_train_idx][["object_id" , "author_name" ]],= comments_5_df.loc[comments_5_train_idx][["target" ]],= comments_5_df.loc[comments_5_test_idx][["object_id" , "author_name" ]].head(10 ),
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)
We can see that the estimator is returning the fixed 0. value for every input, which is what the model is designed to do.
This model achieved an absolute error of 0.8597, so we should bear that in mind for future models.
To have a good baseline we can even infer what the ideal single value to return is. When we generated the data we set the target value for each row. With this we can calculate the mean of the overall dataset quite easily.
Code
Code
from sklearn.metrics import mean_absolute_error= FixedEstimator(= comments_5_df.loc[comments_5_train_idx].target.mean(),= 0.0 , # disable changing the score = 1 ,= 64 ,= "sgd" ,= "cpu" ,= comments_5_df.loc[comments_5_train_idx][["object_id" , "author_name" ]],= comments_5_df.loc[comments_5_train_idx][["target" ]],= estimator.predict(= comments_5_df.loc[comments_5_test_idx][["object_id" , "author_name" ]],= comments_5_df.loc[comments_5_test_idx]["target" ],= predictions,
This shows that fitting directly to the training data doesn’t always generalize well. It’s good to know that a score of around 0.86 can be considered no better than random.
Hadamard
The simplest collaborative filter is the hadamard product over the user and perfume embeddings. This can optionally incorporate a bias per user and product which is not subject to the product.
Code
from dataclasses import dataclassfrom torch import nnimport torch@dataclass class HadamardConfig:int int int bool bool class HadamardModel(nn.Module):def __init__ (self , config: HadamardConfig) -> None :super ().__init__ ()self .config = configself .user_embedding = nn.Embedding(= config.user_count,= config.embedding_size,self .product_embedding = nn.Embedding(= config.product_count,= config.embedding_size,if config.bias:self .user_bias = nn.Parameter(torch.zeros(config.user_count))self .product_bias = nn.Parameter(torch.zeros(config.user_count))def forward(self , users: torch.IntTensor, products: torch.IntTensor) -> torch.Tensor:= users.long ()= products.long ()= self .user_embedding(users)= self .product_embedding(products)= user_embedding * product_embedding= hadamard.sum (dim=- 1 )if self .config.bias:= result + self .user_bias[users] + self .product_bias[products]if self .config.tanh:return torch.tanh(result)return resultclass HadamardEstimator(CollaborativeEstimator):def __init__ (self ,int ,int ,int ,bool ,bool ,float ,int ,int ,str ,str ,-> None :super ().__init__ (= learning_rate,= epochs,= batch_size,= optimizer,= device,self .product_count = product_countself .user_count = user_countself .embedding_size = embedding_sizeself .bias = biasself .tanh = tanhdef _create_model(self ) -> nn.Module:= HadamardConfig(= self .product_count,= self .user_count,= self .embedding_size,= self .bias,= self .tanh,return HadamardModel(config)
Code
= HadamardEstimator(= len (comments_5_df.object_id.cat.categories),= len (comments_5_df.author_name.cat.categories),= 32 ,= True ,= True ,= 1e-3 ,= 5 ,= 64 ,= "adam" ,= "cpu" ,= comments_5_df.loc[comments_5_train_idx][["object_id" , "author_name" ]],= comments_5_df.loc[comments_5_train_idx][["target" ]],= False ,= estimator.predict(= comments_5_df.loc[comments_5_test_idx][["object_id" , "author_name" ]],= comments_5_df.loc[comments_5_test_idx].target,= predictions,
epoch 00: train loss 1.7357
epoch 01: train loss 1.5551
epoch 02: train loss 1.4020
epoch 03: train loss 1.2910
epoch 04: train loss 1.2088
This is performing poorly. The range of values that can be produced is -1 to 1 and the model is forced to stick within that thanks to the tanh activation function. It’s ~1 off the correct value on average.
Remember that returning a fixed value of 0.0 got a mean absolute error of 0.8597. I can’t even say it has overfit, as the loss function is mean squared error. The train function must be averaging an absolute error of more than one to have a square that is also above one.
There are several hyperparameters available for this model, and the model is so simple that it runs quite quickly. Part of the reason for using a sklearn estimator as the structure is to allow a grid search over these hyperparameters.
Code
from sklearn.model_selection import GridSearchCVfrom sklearn.metrics import mean_absolute_error, make_scorer= {"embedding_size" : [32 , 64 ],"bias" : [True , False ],"tanh" : [True , False ],"batch_size" : [64 , 128 ],= HadamardEstimator(= len (comments_5_df.object_id.cat.categories),= len (comments_5_df.author_name.cat.categories),= 32 ,= True ,= True ,= 1e-1 ,= 5 ,= 64 ,= "sgd" ,= "cpu" ,= GridSearchCV(= base_estimator,= parameter_grid,=- 1 ,= make_scorer(mean_absolute_error, greater_is_better= False ),= [(comments_5_train_idx, comments_5_test_idx)],= "raise" ,= comments_5_df[["object_id" , "author_name" ]],= comments_5_df["target" ],= len (grid.cv_results_["mean_test_score" ])= - grid.cv_results_["mean_test_score" ].max ()print (f"grid search of { combination_count:,} combinations " f"results in best score of { best_score:0.4f} "
grid search of 16 combinations results in best score of 0.9748
Code
HadamardEstimator(batch_size=64, bias=True, device='cpu', embedding_size=32,
epochs=5, learning_rate=0.1, optimizer='sgd',
product_count=2296, tanh=True, user_count=10834) In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
While this grid search has improved the score slightly the model itself is still significantly worse than just predicting a single value each time.
Hadamard then Linear
This uses a linear layer to turn the embedding product into a single value. I’m removing the per user and per perfume bias just to make this model simpler. I don’t expect this to be the solution.
Code
from dataclasses import dataclassfrom torch import nnimport torch@dataclass class HadamardThenLinearConfig:int int int bool bool class HadamardThenLinearModel(nn.Module):def __init__ (self , config: HadamardThenLinearConfig) -> None :super ().__init__ ()self .config = configself .user_embedding = nn.Embedding(= config.user_count,= config.embedding_size,self .product_embedding = nn.Embedding(= config.product_count,= config.embedding_size,self .linear = nn.Linear(config.embedding_size, 1 , bias= config.bias)def forward(self , users: torch.IntTensor, products: torch.IntTensor) -> torch.Tensor:= users.long ()= products.long ()= self .user_embedding(users)= self .product_embedding(products)= user_embedding * product_embedding= self .linear(hadamard)if self .config.tanh:return torch.tanh(result)return resultclass HadamardThenLinearEstimator(CollaborativeEstimator):def __init__ (self ,int ,int ,int ,bool ,bool ,float ,int ,int ,str ,str ,-> None :super ().__init__ (= learning_rate,= epochs,= batch_size,= optimizer,= device,self .product_count = product_countself .user_count = user_countself .embedding_size = embedding_sizeself .bias = biasself .tanh = tanhdef _create_model(self ) -> nn.Module:= HadamardThenLinearConfig(= self .product_count,= self .user_count,= self .embedding_size,= self .bias,= self .tanh,return HadamardThenLinearModel(config)
Code
from sklearn.model_selection import GridSearchCVfrom sklearn.metrics import mean_absolute_error, make_scorer= {"embedding_size" : [32 , 64 ],"bias" : [True , False ],"tanh" : [True , False ],"batch_size" : [64 , 128 ],= HadamardThenLinearEstimator(= len (comments_5_df.object_id.cat.categories),= len (comments_5_df.author_name.cat.categories),= 32 ,= True ,= True ,= 1e-1 ,= 5 ,= 64 ,= "sgd" ,= "cpu" ,= GridSearchCV(= base_estimator,= parameter_grid,=- 1 ,= make_scorer(mean_absolute_error, greater_is_better= False ),= [(comments_5_train_idx, comments_5_test_idx)],= "raise" ,= comments_5_df[["object_id" , "author_name" ]],= comments_5_df["target" ],= len (grid.cv_results_["mean_test_score" ])= - grid.cv_results_["mean_test_score" ].max ()print (f"grid search of { combination_count:,} combinations " f"results in best score of { best_score:0.4f} "
grid search of 16 combinations results in best score of 0.8598
Code
HadamardThenLinearEstimator(batch_size=64, bias=True, device='cpu',
embedding_size=32, epochs=5, learning_rate=0.1,
optimizer='sgd', product_count=2296, tanh=True,
user_count=10834) In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
With the linear layer the model is able to achieve an identical score to the fixed score model. This is hardly a resounding success. I wonder if this has devolved into making fixed predictions.
Code
= comments_5_df.loc[comments_5_train_idx][["object_id" , "author_name" ]],= comments_5_df.loc[comments_5_train_idx][["target" ]],= comments_5_df.loc[comments_5_test_idx][["object_id" , "author_name" ]].head(10 ),
array([[0.05531971],
[0.1267522 ],
[0.10492838],
[0.10181362],
[0.19049501],
[0.10646662],
[0.06197954],
[0.06103778],
[0.05164405],
[0.12245701]], dtype=float32)
There is some variation in the output. It still hasn’t managed to do better than a fixed prediction though.
Code
from dataclasses import dataclassimport torchfrom torch import nnimport pandas as pd= {"gelu" : nn.GELU,"tanh" : nn.Tanh,@dataclass class HadamardThenLinearConfig:int list [int ]str = "gelu" class HadamardThenLinear(nn.Module):def __init__ (self ,-> None :super ().__init__ ()self .user_to_ord = {for index, name in enumerate (sorted (comments_df.author_name.unique())self .product_to_ord = {for index, product in enumerate (sorted (comments_df.object_id.unique())self .user_embedding = nn.Embedding(= len (self .user_to_ord),= config.embedding_size,self .product_embedding = nn.Embedding(= len (self .product_to_ord),= config.embedding_size,= [= config.embedding_size,= config.linear_layers[0 ],= activation_name_to_function[config.activation_function]for in_features, out_features in zip (config.linear_layers, config.linear_layers[1 :]):= in_features,= out_features,self .linear = nn.Sequential(* linear)@property def device(self ) -> torch.device:return self .user_embedding.weight.devicedef predict(self , user: str , product: int ) -> torch.Tensor:= self .device= torch.tensor([self .user_to_ord[user]], device= self .device)= torch.tensor([self .product_to_ord[product]], device= self .device)return self .forward(users= user_tensor, products= product_tensor)[0 ]def forward(self , users: torch.IntTensor, products: torch.IntTensor) -> torch.Tensor:= self .user_embedding(users)= self .product_embedding(products)= torch.mul(user_embedding, product_embedding)return self .linear(hadamard)
Code
import numpy as npdef regression_value(df: pd.DataFrame) -> np.array:""" Turns the positive/neutral/negative into a single value. The range is split as follows: -1 negative / -0.33 neutral 0.33 / positive 1 This gives each value a range of 0.66. This is a regression task so the exact value is calculated thusly: The majority class has a value between 0 and 1 The majority class must have a value of at least one third or it would not be the majority We can take the value of the majority of positive and negative and place it on the line -negative / positive E.G. positive: 0.4, neutral: 0.3, negative: 0.3 result: 0.4 positive: 0.3, neutral: 0.3, negative: 0.4 result: -0.4 Think this is simple enough for now. """ = df[["negative" , "positive" ]].to_numpy()= values.argmax(axis= 1 )= (index - 0.5 ) * 2 # select maximum value = values[np.arange(values.shape[0 ]), index]return values * sign
Code
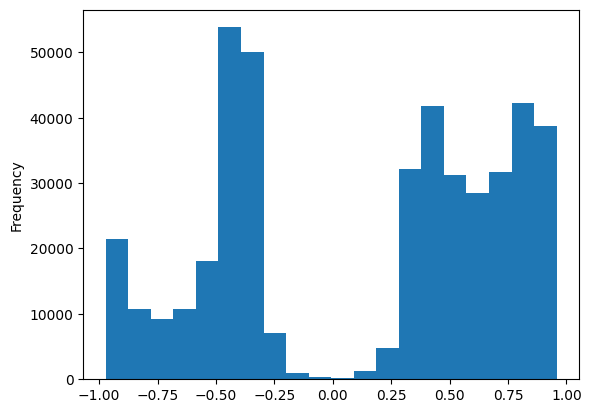
import pandas as pd= pd.read_parquet("/data/perfumes/processed/comments.gz.parquet" )"target" ] = regression_value(comments_df)"target" ].plot.hist(bins= 20 )
<Axes: ylabel='Frequency'>
This doesn’t seem well balanced. Is it consistent with the original data?
What I need to do is to compare the ratio of the different class ranges to the actual distribution of comment sentiment. I can calculate the ratio of class ranges by thresholding the target values
Code
= pd.DataFrame(["label" : "negative" , "count" : (comments_df.target <= - 1 / 3 ).sum ()},"label" : "neutral" , "count" : ((comments_df.target > - 1 / 3 ) & (comments_df.target < 1 / 3 )).sum ()},"label" : "positive" , "count" : (comments_df.target >= 1 / 3 ).sum ()},"label" )/ len (comments_df)
count
label
negative
0.380840
neutral
0.074362
positive
0.544798
And I can compare this to the majority class for the sentiment analysis
Code
= ("negative" , "neutral" , "positive" ]]"negative" , "neutral" , "positive" ]]/ len (comments_df)
count
negative
0.356156
neutral
0.123791
positive
0.520053
With these we can calculate the relative difference between the classes
Code
- true_distribution) / len (comments_df)
count
label
negative
0.024685
neutral
-0.049429
positive
0.024744
As you can see this regression approach has reduced neutral and approximately evenly boosted negative and positive. Positive is the majority class overall so negative has seen a slight increase in relative frequency. This doesn’t seem terrible though.
Code
from tqdm.auto import tqdmfrom torch.utils.data import Dataset, DataLoaderimport torchimport pandas as pdfrom typing import TypedDictclass Entry(TypedDict):str int float class DataframeDataset(Dataset):def __init__ (self , df: pd.DataFrame, model: NeuralCollaborativeFilter) -> None :self .df = dfself .model = modeldef __len__ (self ) -> int :return len (self .df)def __getitem__ (self , index) -> Entry:= self .df.iloc[index]return {"user" : model.user_to_ord[row.author_name],"product" : model.product_to_ord[row.object_id],"target" : row.target,def train(float ,int ,float = 1e-2 ,-> None := len (comments_df) // batch_size= max (int (steps_per_epoch * epochs), 1 )= 0 = DataLoader(= DataframeDataset(df= comments_df, model= model),= batch_size,= True ,= torch.optim.SGD(model.parameters(), lr= learning_rate)with tqdm(total= max_steps) as progress:while step < max_steps:= 0. = 0 for batch in dl:= batch["user" ].to(model.device)= batch["product" ].to(model.device)= batch["target" ].to(model.device)= model(users= users, products= products)= (output - targets)** 2 = loss.mean()+= loss.item() * users.shape[0 ]+= users.shape[0 ]+= 1 = 1 )if step >= max_steps:break print (f"loss: { total_loss / count:0.4f} " )
Code
= NeuralCollaborativeFilter(= NeuralCollaborativeFilterConfig(embedding_size= 10 , linear_layers= [5 , 1 ]),= comments_df,
Code
= model, comments_df= comments_df, epochs= 5.0 , batch_size= 1024 )
loss: 0.3669
loss: 0.3594
loss: 0.3589
loss: 0.3586
loss: 0.3585
Code
NeuralCollaborativeFilter(
(user_embedding): Embedding(95239, 10)
(product_embedding): Embedding(3301, 10)
(linear): Sequential(
(0): Linear(in_features=10, out_features=5, bias=True)
(1): GELU(approximate=none)
(2): Linear(in_features=5, out_features=1, bias=True)
)
)
Code
import torchimport pandas as pd@torch.inference_mode ()def predict(row: pd.Series) -> dict := row.author_name= row.object_id= row.target= model.predict(user= row.author_name, product= row.object_id)return {"user" : user,"product" : product,"target" : target,"actual" : output.item(),with torch.inference_mode():= pd.DataFrame([for row in comments_df.sample(n= 10 ).iloc
user
product
target
actual
0
Arapaima
30164
0.416576
0.172515
1
MrBolton
11649
0.384884
0.051200
2
Roge'
29223
-0.395069
0.150277
3
muncierobson
28246
0.532335
0.203679
4
AuthenticAF
153
0.811077
0.157944
5
zaramona
839
0.408400
0.112785
6
kbot
1833
-0.938313
0.153833
7
dlnkmch
44035
-0.638388
0.169346
8
Yiorgos
143
0.923327
0.176568
9
Firas Mohammad
1834
0.544264
0.143746
This is not very good.
Code
= NeuralCollaborativeFilter(= NeuralCollaborativeFilterConfig(= 50 ,= [50 , 1 ],= "tanh" ,= comments_df,= model, comments_df= comments_df, epochs= 5.0 , batch_size= 64 )
loss: 0.3602
loss: 0.3583
loss: 0.3582
loss: 0.3581
loss: 0.3581
Code
import torchimport pandas as pd@torch.inference_mode ()def predict(row: pd.Series) -> dict := row.author_name= row.object_id= row.target= model.predict(user= row.author_name, product= row.object_id)return {"user" : user,"product" : product,"target" : target,"actual" : output.item(),with torch.inference_mode():= pd.DataFrame([for row in comments_df.sample(n= 10 ).iloc
user
product
target
actual
0
Lsquared
51694
-0.903351
0.130655
1
dolcethadon
3169
0.123378
0.136765
2
Nuppu
4375
-0.942973
0.142797
3
gennarowilde
28246
0.896267
0.143619
4
Eveningrose
31666
-0.918491
0.131670
5
Lightning
705
0.574902
0.141479
6
Lerochek
33519
-0.688771
0.138597
7
Sarah
14982
0.768827
0.139419
8
DarlingNikki
707
-0.782034
0.135745
9
Madyana
18590
0.404112
0.150562