Are large language models unidirectional? Can they benefit from saving intermediate state of previous runs?
Published
June 30, 2023
In the past I’ve checked out the past_key_values returned by causal language models. The past_key_values are the hidden states of the model as it processed the input, and can be passed to the model as part of the input. This is done to skip processing the repeated input prefix and can allow you to vary the input suffix efficiently.
Given that generation natually involves reusing the previously computed sequence at each step, using the past_key_values could result in a significant speed improvement. I want to see if the latest large language models are compatible with this. If they are then it would be good to measure if text generation speed can be improved by using it.
GPT2 as a baseline
I know that GPT2 is unidirectional and thus compatible with this approach. To provide a baseline I am going to demonstrate the technique using GPT2 and show the variance in output.
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("gpt2")model = AutoModelForCausalLM.from_pretrained("gpt2")model = model.cuda()calculate_past_variance("I like to eat", model=model, tokenizer=tokenizer)
without past
with past
absolute Δ
relative Δ
mean
-120.728113
-120.728128
0.000015
1.252379e-07
std
3.248003
3.248004
0.000008
2.523081e-06
min
-137.848907
-137.848938
0.000000
0.000000e+00
25%
-122.974373
-122.974380
0.000008
6.204052e-08
50%
-120.448189
-120.448196
0.000015
1.266834e-07
75%
-118.552200
-118.552208
0.000023
1.930642e-07
max
-107.432274
-107.432281
0.000053
4.971110e-07
The relative difference between the two is less than one in a million (this is the absolute difference between the techniques divided by the absolute without past values). Given floating point values and accumulating error this is the kind of variance I would expect from an ideally equivalent approach that has to contend with implementation details.
RoBERTa as a failure
I think that this technique works with GPT2. When reviewing the performance of recent large language models it would be good to see what a failure looks like. The RoBERTa model is bidirectional, and supports causal language modelling. Given the bidirectional nature I expect (and previously found) that using past_key_values will not work.
Let’s see how it performs.
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("roberta-base")model = AutoModelForCausalLM.from_pretrained("roberta-base")model = model.cuda()calculate_past_variance("I like to eat", model=model, tokenizer=tokenizer)
without past
with past
absolute Δ
relative Δ
mean
-3.229857
-3.045575
0.820397
0.254004
std
2.762300
2.758758
0.626264
0.226718
min
-13.632034
-14.680342
0.000015
0.000001
25%
-5.055089
-4.883758
0.324226
0.064139
50%
-3.325728
-3.093300
0.688780
0.207107
75%
-1.532873
-1.286581
1.180103
0.769863
max
22.772289
23.043306
4.705049
0.206613
Here we can see significant differences in output between the two runs with variances within an order of magnitude of the output. Such a change in output could trivially change the results of using the model for classification or text generation.
GPT2 and Quantization
The final consideration is the use of quantization on this technique. Large language models are aptly named - I cannot run them in full precision on my graphics card. They can be quantized with only a small impact on output, and so this is how I have been running them.
Before evaluating this technique on a quantized large language model, we should first quantize GPT2. That will show if past_key_values is compatible with such a model.
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("gpt2")model = AutoModelForCausalLM.from_pretrained("gpt2", load_in_4bit=True)calculate_past_variance("I like to eat", model=model, tokenizer=tokenizer)
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please run
python -m bitsandbytes
and submit this information together with your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
bin /home/matthew/.cache/pypoetry/virtualenvs/blog-HrtMnrOS-py3.11/lib/python3.11/site-packages/bitsandbytes/libbitsandbytes_cuda121.so
CUDA_SETUP: WARNING! libcudart.so not found in any environmental path. Searching in backup paths...
CUDA SETUP: CUDA runtime path found: /usr/local/cuda/lib64/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 7.5
CUDA SETUP: Detected CUDA version 121
CUDA SETUP: Loading binary /home/matthew/.cache/pypoetry/virtualenvs/blog-HrtMnrOS-py3.11/lib/python3.11/site-packages/bitsandbytes/libbitsandbytes_cuda121.so...
without past
with past
absolute Δ
relative Δ
mean
-120.754618
-120.768101
0.013483
0.000112
std
3.247413
3.248440
0.025922
0.007982
min
-137.875000
-137.875000
0.000000
0.000000
25%
-123.000000
-123.000000
0.000000
0.000000
50%
-120.500000
-120.500000
0.000000
0.000000
75%
-118.562500
-118.625000
0.000000
0.000000
max
-107.437500
-107.500000
0.125000
0.001163
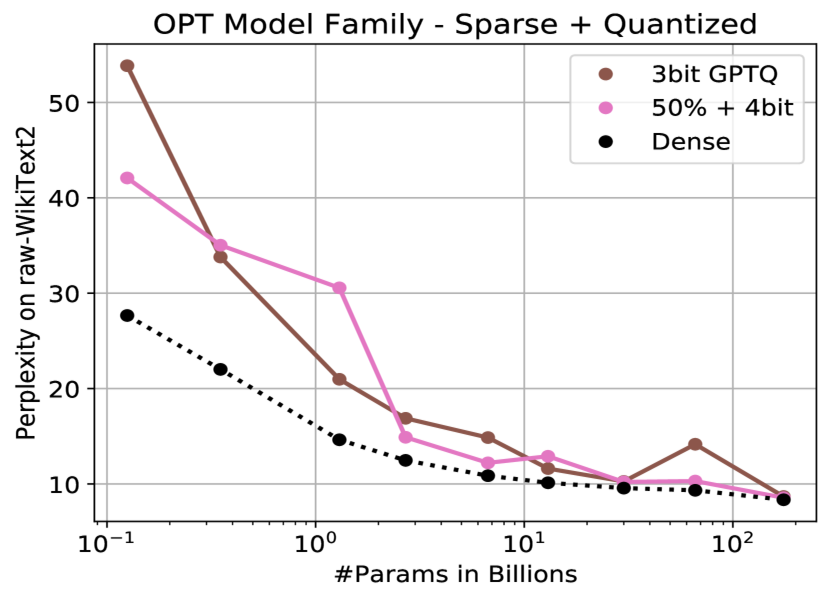
Quantization has clearly impacted this model. This is to be expected as this is a 124M parameter model and we can see that quantization severely impacts this in this graphic from (Frantar and Alistarh 2023).
Frantar, Elias, and Dan Alistarh. 2023. “SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot.”https://arxiv.org/abs/2301.00774.
perplexity changes with model size and quantization level
The 124M parameter line is the far left one and shows a best case degredation from around 28 perplexity to more than 40. That’s a huge loss.
Even with this dramatic change the difference in outputs is at most 0.1%. This seems like a reasonable worst-case difference.
MPT 7B
We can now evaluate MPT 7B (Team 2023) using this technique. I’m going to try both 4bit and 8bit quantization to see if that changes the results.
Team, MosaicML NLP. 2023. “Introducing MPT-7B: A New Standard for Open-Source, Commercially Usable LLMs.” 2023. www.mosaicml.com/blog/mpt-7b.
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("mosaicml/mpt-7b")model = AutoModelForCausalLM.from_pretrained("mosaicml/mpt-7b", load_in_4bit=True, trust_remote_code=True)calculate_past_variance("I like to eat", model=model, tokenizer=tokenizer)
Instantiating an MPTForCausalLM model from /home/matthew/.cache/huggingface/modules/transformers_modules/mosaicml/mpt-7b/a78c1fa391580242211a2f516cf9ef10c86713c8/modeling_mpt.py
You are using config.init_device='cpu', but you can also use config.init_device="meta" with Composer + FSDP for fast initialization.
without past
with past
absolute Δ
relative Δ
mean
40.278929
31.707907
8.587784
0.213208
std
8.868180
6.700384
2.653544
0.299221
min
-1.125000
0.068481
0.000000
0.000000
25%
40.218750
31.562500
7.468750
0.185703
50%
42.593750
33.656250
8.875000
0.208364
75%
44.750000
35.125000
10.187500
0.227654
max
57.062500
43.906250
19.156250
0.335706
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("mosaicml/mpt-7b")model = AutoModelForCausalLM.from_pretrained("mosaicml/mpt-7b", load_in_8bit=True, trust_remote_code=True)calculate_past_variance("I like to eat", model=model, tokenizer=tokenizer)
Instantiating an MPTForCausalLM model from /home/matthew/.cache/huggingface/modules/transformers_modules/mosaicml/mpt-7b/a78c1fa391580242211a2f516cf9ef10c86713c8/modeling_mpt.py
You are using config.init_device='cpu', but you can also use config.init_device="meta" with Composer + FSDP for fast initialization.
without past
with past
absolute Δ
relative Δ
mean
40.496577
29.884832
10.619180
0.262224
std
9.041705
6.293464
3.288190
0.363669
min
-1.349609
-1.061523
0.000000
0.000000
25%
40.000000
29.734375
9.281250
0.232031
50%
42.843750
31.468750
11.125000
0.259664
75%
45.250000
32.937500
12.750000
0.281768
max
58.031250
43.281250
19.765625
0.340603
This is clearly more consistent with RoBERTa than GPT2. It appears that this model cannot effectively use past_key_values. A great shame.
Falcon 7B
The falcon 7B model came out recently (Almazrouei et al. 2023) and I have recently looked into it. Maybe this one will work with past_key_values?
Almazrouei, Ebtesam, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Merouane Debbah, Etienne Goffinet, et al. 2023. “Falcon-40B: An Open Large Language Model with State-of-the-Art Performance.”
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-7b")model = AutoModelForCausalLM.from_pretrained("tiiuae/falcon-7b", load_in_4bit=True, trust_remote_code=True)calculate_past_variance("I like to eat", model=model, tokenizer=tokenizer)
without past
with past
absolute Δ
relative Δ
mean
-14.261603
-9.267643
5.104978
0.357953
std
2.733929
2.113323
2.461072
0.900196
min
-26.296875
-20.250000
0.000000
0.000000
25%
-16.234375
-10.609375
3.398438
0.209336
50%
-14.570312
-9.250000
5.117188
0.351206
75%
-12.601562
-7.902344
6.750000
0.535648
max
1.404297
0.727051
17.265625
12.294854
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-7b")model = AutoModelForCausalLM.from_pretrained("tiiuae/falcon-7b", load_in_8bit=True, trust_remote_code=True)calculate_past_variance("I like to eat", model=model, tokenizer=tokenizer)
without past
with past
absolute Δ
relative Δ
mean
-14.041440
-12.929303
2.086437
0.148591
std
2.699918
2.064221
1.565948
0.579998
min
-26.218750
-23.984375
0.000000
0.000000
25%
-16.031250
-14.281250
0.867188
0.054094
50%
-14.304688
-13.179688
1.789062
0.125068
75%
-12.343750
-11.820312
2.960938
0.239873
max
1.180664
0.358887
12.265625
10.388751
A second example of RoBERTa like performance.
Conclusion
The two large language models I have reviewed are not able to use past_key_values safely. Doing so significantly changes their output.
This is a pity as the performance improvement available using this technique for generation would be significant. Oh well.