
I recently read the Attention with Linear Biases paper (Press, Smith, and Lewis 2022) and it seemed like a neat way to handle positional encodings in transformer models. It struck me that I did not sufficiently understand transformers, as the implementation surprised me. That means this can be an exploration of transformers as well.
Press, Ofir, Noah A. Smith, and Mike Lewis. 2022. “Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation.” https://arxiv.org/abs/2108.12409.
The problem that ALiBi addresses is that transformer models do not extrapolate well to content that is longer than what they were trained with. Transformer models convert the input text into embeddings which are then passed through matrix multiplication. This multiplication is not able to use the position of values within the matrix effectively as repeated words become the same embeddings at different indices and multiply out to the same values.
In the original paper (Vaswani et al. 2017) they proposed two approaches to add positional knowledge (section 3.5 positional encoding). The first was to use sine waves of varying frequency to generate values to add to the embeddings. This would discriminate between the same word at different positions because of the variation in the sine waves. The second was to have a trainable set of values that were added to the embedding. Training these values would allow the model to determine what information about position was interesting.
Vaswani, Ashish, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. “Attention Is All You Need.” https://arxiv.org/abs/1706.03762.
Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. “BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding.” https://arxiv.org/abs/1810.04805.
The trainable values produced better results in subsequent models, e.g. BERT (Devlin et al. 2019), which lead to it being the dominant architecture. Unfortunately this meant that the total size of the model input was fixed as the trainable values could not be extrapolated to longer sequences.
Model Alteration
The ALiBi technique involves two changes. First the positional embeddings are removed, and then every attention layer is altered to add the positional offsets after the Query Key matrix multiplication.
The GPT2 code involves large methods where only tiny changes need to occur. This makes updating GPT2 somewhat tiresome as the changes are easy to miss. To help with this I have repeated the differences below:
The GPT2LMHeadModel is what you get when you create a GPT2 model for Causal Language Modelling. Within it this contains a GPT2Model which applies the positional embedding. To implement ALiBi GPT2 the GPT2Model is altered to delete the positional embedding in the constructor:
def __init__(self, config):
super().__init__(config)
delattr(self, "wpe") # pe = positional embeddingDeleting this field in the constructor is not enough as it is used in the forward method, where it is added to the token embeddings to produce the input embeddings (named hidden_states). Removing the use of it can also remove the use of position_ids as they are only used to calculate the positional embedding:
def forward(
self,
...
) -> Union[Tuple, BaseModelOutputWithPastAndCrossAttentions]:
...
# CHANGED: Remove the position_embeds
# if position_ids is not None:
# position_ids = position_ids.view(-1, input_shape[-1])
...
# CHANGED: Remove the position_embeds
# if position_ids is None:
# position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
# position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
...
if inputs_embeds is None:
inputs_embeds = self.wte(input_ids)
# CHANGED: Remove the position_embeds
# position_embeds = self.wpe(position_ids)
# hidden_states = inputs_embeds + position_embeds
hidden_states = inputs_embedsThese changes have removed the original positional embedding from the GPT2 model. To allow the model to work with positional information we now need to alter the attention blocks to incorporate the linear bias that ALiBi is named after.
It’s easiest to understand this by reviewing the structure of attention itself. Here you can see the point where the ALiBi linear bias is added, which comes right before the softmax.
To make this change we need to alter the GPT2Attention layers within the GPT2Model to add the linear bias before the softmax. This results in the following changes:
def _attn(self, query, key, value, attention_mask=None, head_mask=None):
...
# CHANGED: add the positional embed
attn_weights = self._add_linear_bias(attn_weights)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
...
def _upcast_and_reordered_attn(self, query, key, value, attention_mask=None, head_mask=None):
...
# CHANGED: add the positional embed
attn_weights = self._add_linear_bias(attn_weights)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
...The linear bias that replaces the positional embedding is described by this image:
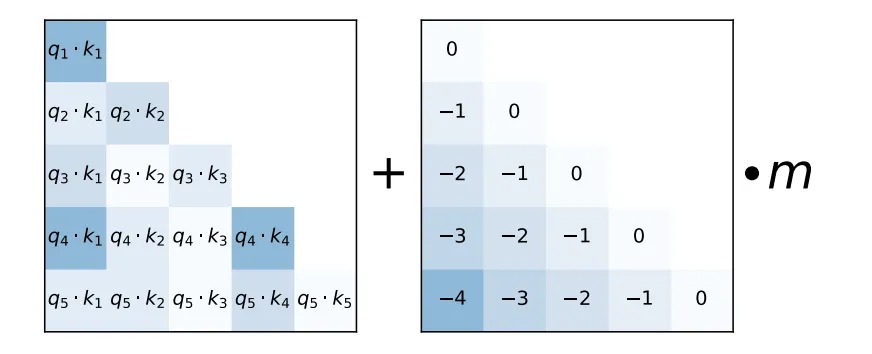
To generate the linear bias we need to have the \(m\) value for the attention head. This varies per attention head which means that the positional embedding is stronger for some heads than others. This is calculated in the github repo by the get_slopes method which I copy. To make the code simple I calculate the offset each time as that allows me to easily resize it to the input tokens.
The linear bias requires a triangular offset, which can be calculated easily by summing two tensors. Broadcasting makes these repeat in the missing dimension:
\[ \begin{bmatrix} 0 & -1 & -2 \\ \end{bmatrix} + \begin{bmatrix} 0 \\ 1 \\ 2 \\ \end{bmatrix} = \begin{bmatrix} 0 & -1 & -2 \\ 1 & 0 & -1 \\ 2 & 1 & 0 \\ \end{bmatrix} \]
We could either take the positive values from this, or use the torch.tril method to select them. With the base offset calculated it just needs to be multiplied by the slope to get the final offset.
Code
from typing import Optional, Tuple, Union
from transformers.models.gpt2.modeling_gpt2 import GPT2Model, GPT2Attention
from transformers.modeling_outputs import BaseModelOutputWithPastAndCrossAttentions
import torch
from torch import nn
import math
class GPT2AlibiModel(GPT2Model):
def __init__(self, config):
super().__init__(config)
delattr(self, "wpe")
for module in self.modules():
if not isinstance(module, GPT2Attention):
continue
GPT2AlibiAttention.convert(module)
# changed twice to remove the position_ids calculation and their use with wpe to generate input_embeds
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPastAndCrossAttentions]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
use_cache = use_cache if use_cache is not None else self.config.use_cache
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
batch_size = input_ids.shape[0]
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
batch_size = inputs_embeds.shape[0]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
device = input_ids.device if input_ids is not None else inputs_embeds.device
if token_type_ids is not None:
token_type_ids = token_type_ids.view(-1, input_shape[-1])
# CHANGED: Remove the position_embeds
# if position_ids is not None:
# position_ids = position_ids.view(-1, input_shape[-1])
if past_key_values is None:
past_length = 0
past_key_values = tuple([None] * len(self.h))
else:
past_length = past_key_values[0][0].size(-2)
# CHANGED: Remove the position_embeds
# if position_ids is None:
# position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
# position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
# GPT2Attention mask.
if attention_mask is not None:
if batch_size <= 0:
raise ValueError("batch_size has to be defined and > 0")
attention_mask = attention_mask.view(batch_size, -1)
# We create a 3D attention mask from a 2D tensor mask.
# Sizes are [batch_size, 1, 1, to_seq_length]
# So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
# this attention mask is more simple than the triangular masking of causal attention
# used in OpenAI GPT, we just need to prepare the broadcast dimension here.
attention_mask = attention_mask[:, None, None, :]
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and the dtype's smallest value for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
# If a 2D or 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.add_cross_attention and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# head_mask has shape n_layer x batch x n_heads x N x N
head_mask = self.get_head_mask(head_mask, self.config.n_layer)
if inputs_embeds is None:
inputs_embeds = self.wte(input_ids)
# CHANGED: Remove the position_embeds
# position_embeds = self.wpe(position_ids)
# hidden_states = inputs_embeds + position_embeds
hidden_states = inputs_embeds
if token_type_ids is not None:
token_type_embeds = self.wte(token_type_ids)
hidden_states = hidden_states + token_type_embeds
hidden_states = self.drop(hidden_states)
output_shape = input_shape + (hidden_states.size(-1),)
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning_once(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
presents = () if use_cache else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
all_hidden_states = () if output_hidden_states else None
for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
# Model parallel
if self.model_parallel:
torch.cuda.set_device(hidden_states.device)
# Ensure layer_past is on same device as hidden_states (might not be correct)
if layer_past is not None:
layer_past = tuple(past_state.to(hidden_states.device) for past_state in layer_past)
# Ensure that attention_mask is always on the same device as hidden_states
if attention_mask is not None:
attention_mask = attention_mask.to(hidden_states.device)
if isinstance(head_mask, torch.Tensor):
head_mask = head_mask.to(hidden_states.device)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if self.gradient_checkpointing and self.training:
def create_custom_forward(module):
def custom_forward(*inputs):
# None for past_key_value
return module(*inputs, use_cache, output_attentions)
return custom_forward
outputs = torch.utils.checkpoint.checkpoint(
create_custom_forward(block),
hidden_states,
None,
attention_mask,
head_mask[i],
encoder_hidden_states,
encoder_attention_mask,
)
else:
outputs = block(
hidden_states,
layer_past=layer_past,
attention_mask=attention_mask,
head_mask=head_mask[i],
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=use_cache,
output_attentions=output_attentions,
)
hidden_states = outputs[0]
if use_cache is True:
presents = presents + (outputs[1],)
if output_attentions:
all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (outputs[3 if use_cache else 2],)
# Model Parallel: If it's the last layer for that device, put things on the next device
if self.model_parallel:
for k, v in self.device_map.items():
if i == v[-1] and "cuda:" + str(k) != self.last_device:
hidden_states = hidden_states.to("cuda:" + str(k + 1))
hidden_states = self.ln_f(hidden_states)
hidden_states = hidden_states.view(output_shape)
# Add last hidden state
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [hidden_states, presents, all_hidden_states, all_self_attentions, all_cross_attentions]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=presents,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
class GPT2AlibiAttention(GPT2Attention):
@classmethod
def convert(cls, layer: GPT2Attention) -> None:
layer.__class__ = cls # yolo
layer.slopes = torch.tensor(get_slopes(layer.num_heads))
def _add_linear_bias(self, attn_weights: torch.Tensor) -> torch.Tensor:
# attn_weights is batch_size, num_heads, tokens, tokens
# e.g. torch.Size([1, 12, 2, 2])
batch_size, num_heads, tokens, _ = attn_weights.shape
offset = torch.tril(
-torch.tensor(range(tokens), device=attn_weights.device)[None, :]
+ torch.tensor(range(tokens), device=attn_weights.device)[:,None]
)
self.slopes = self.slopes.to(attn_weights.device)
# this is now (tokens, tokens)
offset = offset[None, :] * self.slopes[:, None, None]
# this is now (num_heads, tokens, tokens)
return attn_weights + offset[None, :]
def _attn(self, query, key, value, attention_mask=None, head_mask=None):
attn_weights = torch.matmul(query, key.transpose(-1, -2))
if self.scale_attn_weights:
attn_weights = attn_weights / torch.full(
[], value.size(-1) ** 0.5, dtype=attn_weights.dtype, device=attn_weights.device
)
# Layer-wise attention scaling
if self.scale_attn_by_inverse_layer_idx:
attn_weights = attn_weights / float(self.layer_idx + 1)
if not self.is_cross_attention:
# if only "normal" attention layer implements causal mask
query_length, key_length = query.size(-2), key.size(-2)
causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length]
mask_value = torch.finfo(attn_weights.dtype).min
# Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`.
# Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device`
mask_value = torch.full([], mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
attn_weights = torch.where(causal_mask, attn_weights.to(attn_weights.dtype), mask_value)
if attention_mask is not None:
# Apply the attention mask
attn_weights = attn_weights + attention_mask
# CHANGED: add the positional embed
attn_weights = self._add_linear_bias(attn_weights)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
# Downcast (if necessary) back to V's dtype (if in mixed-precision) -- No-Op otherwise
attn_weights = attn_weights.type(value.dtype)
attn_weights = self.attn_dropout(attn_weights)
# Mask heads if we want to
if head_mask is not None:
attn_weights = attn_weights * head_mask
attn_output = torch.matmul(attn_weights, value)
return attn_output, attn_weights
def _upcast_and_reordered_attn(self, query, key, value, attention_mask=None, head_mask=None):
# Use `torch.baddbmm` (a bit more efficient w/ alpha param for scaling -- from Megatron-LM)
bsz, num_heads, q_seq_len, dk = query.size()
_, _, k_seq_len, _ = key.size()
# Preallocate attn_weights for `baddbmm`
attn_weights = torch.empty(bsz * num_heads, q_seq_len, k_seq_len, dtype=torch.float32, device=query.device)
# Compute Scale Factor
scale_factor = 1.0
if self.scale_attn_weights:
scale_factor /= float(value.size(-1)) ** 0.5
if self.scale_attn_by_inverse_layer_idx:
scale_factor /= float(self.layer_idx + 1)
# Upcast (turn off autocast) and reorder (Scale K by 1 / root(dk))
with autocast(enabled=False):
q, k = query.reshape(-1, q_seq_len, dk), key.transpose(-1, -2).reshape(-1, dk, k_seq_len)
attn_weights = torch.baddbmm(attn_weights, q.float(), k.float(), beta=0, alpha=scale_factor)
attn_weights = attn_weights.reshape(bsz, num_heads, q_seq_len, k_seq_len)
if not self.is_cross_attention:
# if only "normal" attention layer implements causal mask
query_length, key_length = query.size(-2), key.size(-2)
causal_mask = self.bias[:, :, key_length - query_length : key_length, :key_length]
mask_value = torch.finfo(attn_weights.dtype).min
# Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`.
# Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device`
mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
attn_weights = torch.where(causal_mask, attn_weights, mask_value)
if attention_mask is not None:
# Apply the attention mask
attn_weights = attn_weights + attention_mask
# CHANGED: add the positional embed
attn_weights = self._add_linear_bias(attn_weights)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
# Downcast (if necessary) back to V's dtype (if in mixed-precision) -- No-Op if otherwise
if attn_weights.dtype != torch.float32:
raise RuntimeError("Error with upcasting, attn_weights does not have dtype torch.float32")
attn_weights = attn_weights.type(value.dtype)
attn_weights = self.attn_dropout(attn_weights)
# Mask heads if we want to
if head_mask is not None:
attn_weights = attn_weights * head_mask
attn_output = torch.matmul(attn_weights, value)
return attn_output, attn_weights
def get_slopes(n):
def get_slopes_power_of_2(n):
start = (2**(-2**-(math.log2(n)-3)))
ratio = start
return [start*ratio**i for i in range(n)]
if math.log2(n).is_integer():
return get_slopes_power_of_2(n)
else:
closest_power_of_2 = 2**math.floor(math.log2(n))
return get_slopes_power_of_2(closest_power_of_2) + get_slopes(2*closest_power_of_2)[0::2][:n-closest_power_of_2]Sanity Check
We have just created an alternative GPT2 model. The change that we have made has broken one of the assumptions that the model used during training, the means by which positional information is encoded. If we have done this correctly then the output of the model should change, as it is fundamentally dependent on word order. It’s easiest to do this by comparing the output of a single simple continuation.
Code
from transformers import AutoModelForCausalLM
import torch
import pandas as pd
MODEL_NAME = "gpt2"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
text = "hello world"
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
alibi_model = AutoModelForCausalLM.from_pretrained("gpt2")
alibi_model.transformer = GPT2AlibiModel.from_pretrained("gpt2")
with torch.inference_mode():
input = tokenizer(text, return_tensors="pt").input_ids
input.to(alibi_model.device)
alibi_output = alibi_model(input)
base_output = model(input)
base_next_token = base_output.logits[0, -1].argmax().item()
alibi_next_token = alibi_output.logits[0, -1].argmax().item()
print(f"given the text: {text}")
print(f"gpt2 predicts: {tokenizer.decode(base_next_token)}")
print(f"gpt2-alibi predicts: {tokenizer.decode(alibi_next_token)}")
print("the difference between the two models can be described as:")
pd.Series(
(base_output.logits - alibi_output.logits)
.flatten()
.numpy()
).describe().to_frame().T[["mean", "std", "min", "max"]]given the text: hello world
gpt2 predicts: .
gpt2-alibi predicts: would
the difference between the two models can be described as:| mean | std | min | max | |
|---|---|---|---|---|
| 0 | 18.336964 | 7.781691 | -1.934105 | 38.141624 |
This is quite a difference, which is to be expected. The ALiBi GPT2 model has been initialized with the weights from the base GPT2 model, but those weights expect the positional embeddings and have not been updated.
Fixing ALiBi GPT2 with Distillation
To fix the ALiBi GPT2 model it needs to be trained. The training could be done using causal language modelling, however I want to try improving that with distillation.
In distillation you have two models, a student model which is being trained, and a teacher model. The student performs a base task and is evaluated on that like in normal training. The teacher also performs that task and provides a second loss metric, where the difference in output distribution between the teacher and student informs the student. This distribution loss is a more informative loss as it tells the student about the decision boundaries that the teacher has used to solve the task.
For this to work the two models must have the same architecture. Incorporating ALiBi into the student has changed the architecture - but is the model still similar enough to learn from the unaltered teacher? I think it would be fun to find out.
Code
# from src/main/python/blog/distillation/classes.py
from typing import Any, Dict, Tuple, Union
import torch
import torch.nn.functional as F
from torch import nn
from transformers import AutoModelForCausalLM, Trainer, TrainingArguments
class DistillationTrainingArguments(TrainingArguments):
def __init__(
self, *args, alpha: float = 0.5, temperature: float = 2.0, **kwargs
) -> None:
super().__init__(*args, **kwargs)
self.alpha = alpha
self.temperature = temperature
class DistillationTrainer(Trainer):
def __init__(
self, *args, teacher_model: AutoModelForCausalLM = None, **kwargs
) -> None:
super().__init__(*args, **kwargs)
self.teacher = teacher_model
# place teacher on same device as student
self._move_model_to_device(self.teacher, self.model.device)
self.teacher.eval()
def compute_loss(
self,
model: AutoModelForCausalLM,
inputs: Dict[str, Union[torch.Tensor, Any]],
return_outputs: bool = False,
) -> Union[Tuple[torch.Tensor, torch.Tensor], torch.Tensor]:
# compute student output
outputs_student = model(**inputs)
student_loss = outputs_student.loss
# compute teacher output
with torch.no_grad():
outputs_teacher = self.teacher(**inputs)
# assert size
assert outputs_student.logits.size() == outputs_teacher.logits.size()
# Soften probabilities and compute distillation loss
loss_function = nn.KLDivLoss(reduction="batchmean")
loss_logits = loss_function(
F.log_softmax(outputs_student.logits / self.args.temperature, dim=-1),
F.softmax(outputs_teacher.logits / self.args.temperature, dim=-1),
) * (self.args.temperature**2)
# Return weighted student loss
loss = self.args.alpha * student_loss + (1.0 - self.args.alpha) * loss_logits
return (loss, outputs_student) if return_outputs else lossCode
from pathlib import Path
DATA_FOLDER = Path("/data/blog/2023/07/11/retraining-gpt-with-alibi")
DATA_FOLDER.mkdir(exist_ok=True, parents=True)
MODEL_NAME = "gpt2"
LEARNING_RATE = 3e-4
BATCH_SIZE = 4
MAX_STEPS = 10_000To perform the distillation we want a bunch of text that can be used for causal language modelling. There are quite a few different datasets available at huggingface including wikitext and the pile. For this we just want to see if the model is going to learn at all, so I have chosen a smaller dataset that consists of summarized news articles.
To use this we have to tokenize the text in it. The dataset has the summary of the article which we will tokenize, and also the headline and category of the article which we don’t really need.
Code
from datasets import load_dataset
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.pad_token_id = tokenizer.eos_token_id
dataset = load_dataset("JulesBelveze/tldr_news")
dataset = dataset.remove_columns(["headline", "category"])
dataset = dataset.map(lambda row: tokenizer(row["content"]), batched=True)With this dataset and the distillation trainer we can now train the ALiBi GPT2 model.
Code
from pathlib import Path
from transformers import (
AutoModelForCausalLM,
DataCollatorForLanguageModeling,
)
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
tokenizer.pad_token_id = tokenizer.eos_token_id
alibi_model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
alibi_model.transformer = GPT2AlibiModel.from_pretrained(MODEL_NAME)
training_arguments = DistillationTrainingArguments(
report_to=[],
output_dir=str(DATA_FOLDER / "output"),
logging_dir=str(DATA_FOLDER / "output"),
overwrite_output_dir=True,
save_total_limit=2,
evaluation_strategy="steps",
max_steps=MAX_STEPS,
learning_rate=LEARNING_RATE,
warmup_ratio=0.06,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=BATCH_SIZE*2,
eval_steps=500,
logging_steps=500,
load_best_model_at_end=True,
metric_for_best_model="loss",
greater_is_better=False,
)
trainer = DistillationTrainer(
model=alibi_model,
teacher_model=AutoModelForCausalLM.from_pretrained(MODEL_NAME),
args=training_arguments,
data_collator=DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=False,
),
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
)
trainer.train()
alibi_model = trainer.model
alibi_model.save_pretrained(DATA_FOLDER / "best-model")
[10000/10000 22:06, Epoch 5/6]
| Step | Training Loss | Validation Loss |
|---|---|---|
| 500 | 102.803000 | 36.601101 |
| 1000 | 43.042600 | 28.497589 |
| 1500 | 35.109100 | 24.234194 |
| 2000 | 29.679400 | 22.294165 |
| 2500 | 25.083800 | 20.382338 |
| 3000 | 24.173100 | 18.993040 |
| 3500 | 22.808500 | 17.853329 |
| 4000 | 19.593900 | 16.814453 |
| 4500 | 18.167000 | 15.901449 |
| 5000 | 17.962500 | 14.859370 |
| 5500 | 16.412200 | 14.372695 |
| 6000 | 15.037200 | 13.705388 |
| 6500 | 14.719800 | 12.982800 |
| 7000 | 13.888000 | 12.372024 |
| 7500 | 12.962700 | 11.911731 |
| 8000 | 12.406700 | 11.423912 |
| 8500 | 11.896800 | 11.073598 |
| 9000 | 11.567100 | 10.735437 |
| 9500 | 10.950700 | 10.467397 |
| 10000 | 10.699700 | 10.337049 |
TrainOutput(global_step=10000, training_loss=23.448189794921873, metrics={'train_runtime': 1326.8822, 'train_samples_per_second': 30.146, 'train_steps_per_second': 7.536, 'total_flos': 3962717762217984.0, 'train_loss': 23.448189794921873, 'epoch': 5.6})We can see a steady decrease in the training and validation loss over this train. The training process has run over this small news dataset 5 times so while it could likely decrease more, I think that there is limited value in doing so - the student would just learn the mannerisms of this particular dataset more precisely. A more diverse dataset would be better for doing a longer train. Remember that the original GPT-2 was trained on 40GB of data while this news dataset is just 1.7MB.
Evaluating the trained ALiBi GPT2 model
How well has the model trained? We can test this by seeing how well the model can generate text. This is one way that the original blog post demonstrated the quality of the GPT-2 model originally. As a homage to that original demonstration of quality I will use the same unicorn discovery prompt.
Code
import torch
alibi_model.eval()
with torch.inference_mode():
tokens = tokenizer(
"In a shocking finding, scientist discovered a herd "
"of unicorns living in a remote, previously unexplored "
"valley, in the Andes Mountains. Even more surprising "
"to the researchers was the fact that the unicorns "
"spoke perfect English.",
return_tensors="pt"
)
tokens = tokens.to(alibi_model.device)
output = alibi_model.generate(
**tokens,
do_sample=True,
temperature=0.7,
top_p=1,
repetition_penalty=1.2,
max_new_tokens=128,
pad_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(output[0])
output = "\n".join(f"> {line}" for line in output.splitlines())
print(output)In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English. In fact it was the first language spoken by a native speaker. It was not a foreign speaker and it was the first language spoken by one who learned Arabic.
The first language where one can have two languages. The first language is very powerful. Most people may listen with the first language. They will hear what they know when speaking the first language while they are learning languages. This means they are learning the first language and listening for them. At this point we are also listening before they are listening to language. We understand the first language as well.
We learn the first language. Once they know what language
The language use here is not very good. There is a lack of coherence in the output. I do think that it resembles natural language but I wouldn’t write a celebratory blog post about it.
However, given that the model has trained for 20 minutes on 1.7MB of text I think this is a good start. How well does the original model do given this prompt?
Code
from transformers import AutoModelForCausalLM
base_model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
base_model.to(alibi_model.device)
with torch.inference_mode():
output = base_model.generate(
**tokens,
do_sample=True,
temperature=0.7,
top_p=1,
repetition_penalty=1.2,
max_new_tokens=128,
pad_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(output[0])
output = "\n".join(f"> {line}" for line in output.splitlines())
print(output)In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English. “They were so beautiful and wild they could move like sheep,” says archaeologist Robert Hildegardt from Yale University’s Center for Archaeological Research (CRA). “This is an interesting discovery.” The scientists didn’t reveal exactly what had happened or where it came down but say their findings suggest there are other things going on as well. The unicorn found may have been left behind by another creature known only as ‘the devil,’ which has become extinct over time due not just habitat loss at present but also climate change too - particularly because this species can be seen wandering across much narrower terrain than human-made structures such As
We can see here the fluency that was so remarkable when the model first released.
Given that our ALiBi version is noticeably worse, can we demonstrate that it has improved at all? We could try generating text with the untrained ALiBi GPT2 model for comparison.
Code
from transformers import AutoModelForCausalLM
unrefined_model = AutoModelForCausalLM.from_pretrained("gpt2")
unrefined_model.transformer = GPT2AlibiModel.from_pretrained("gpt2")
unrefined_model.to(alibi_model.device)
with torch.inference_mode():
output = unrefined_model.generate(
**tokens,
do_sample=True,
temperature=0.7,
top_p=1,
repetition_penalty=1.2,
max_new_tokens=128,
pad_token_id=tokenizer.eos_token_id,
)
output = tokenizer.decode(output[0])
output = "\n".join(f"> {line}" for line in output.splitlines())
print(output)In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English. all other and come one just we also but with life share f at by real 1 end as even 2 un last second care among others which were found be most - on not only s when 3 have two they are so much seen n who had – people where it death this part many taken such shared how came see what alone led both from down nearly none truly ended put us almost tragically spent first left over worse known started children heart badly she actually her said deep I leave sadly” less began after 40 then far worst stories took bed dest died off those without them berean disaster ” forced whole young me tears too 10 three our loved g 20
This is unreadable trash. Clearly training has improved the model.
A longer train with better data could result in a useable model that benefits from the vastly improved context length available.
Final Thoughts
I’ve been discussing this with someone at work and they pointed out that the new means of representing the positions makes long distance connections weaker. This could be undesirable because when using a model you often put the prompt in first, and anything that reduces the impact of the prompt makes it harder to control the model. Furthermore for things like news articles the subject is introduced at the start and provides the most context for the rest of the article.
Is the current linear bias the best? Should it be based on some other equation? Something to investigate.