How is Cosine Similarity affected by dimension count
Is a Cosine Similarity of 0.5 discriminative for high dimensional vectors?
Published
September 21, 2023
A paper recently used a cosine similarity of 0.5 to cluster news articles. This seemed like a high value to me as cosine similarity itself has a range of -1 to 1. The vectors that were being clustered were \(x \in \mathbb{R}^{768}\), so they were of reasonably high dimensionality.
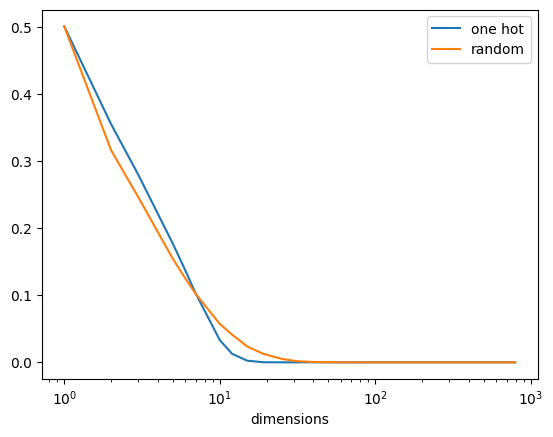
How does the number of matches with this threshold vary as we increase the dimension count? We can test this in two ways, one with a fixed one hot vector compared to a random vector, and another with two random vectors.
import pandas as pddimensions =sorted({int(10**log_d)for log_d in np.arange(0, 3, 0.1)})df = pd.DataFrame([ {"dimensions": n,"one hot": compare_one_hot( dimensions=n, iterations=100_000, threshold=0.5, ),"random": compare_random( dimensions=n, iterations=100_000, threshold=0.5, ), }for n in dimensions])df = df.set_index("dimensions")df.plot(logx=True)df.iloc[[0, -1]]
one hot
random
dimensions
1
0.50081
0.50064
794
0.00000
0.00000
We can see that as the dimension count increases the probability decreases. By the time you reach the high dimensions there are very few matches (0 matches in 100,000 comparisons). So it is a discriminatory test. Why is this?
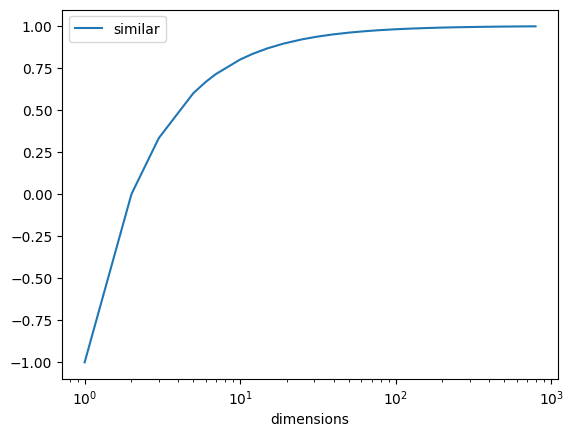
If we imagine a pair of vectors and the similarity between them, can we produce a positive cosine similarity if any of the dimensions are orthogonal? Cosine similarity is the normalized dot product of the two vectors. The most similar vector pair with orthogonality would be \([1, ...]^N\) and \([-1, 1, ...]^N\). Let’s compare these.
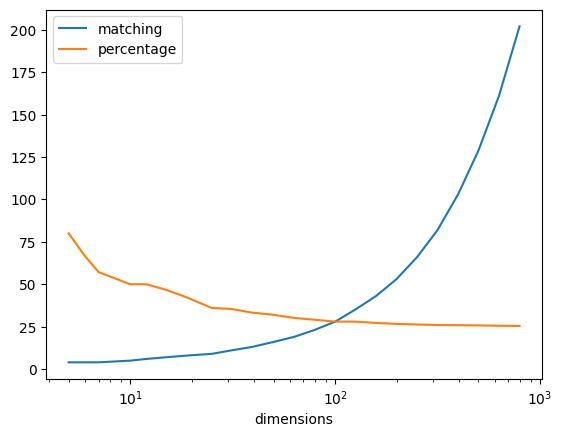
import pandas as pddimensions =sorted({int(10**log_d)for log_d in np.arange(0, 3, 0.1)})df = pd.DataFrame([ {"dimensions": n,"matching": required_matches(dimensions=n),"percentage": required_matches(dimensions=n) *100/ n, }for n in dimensions])df = df.set_index("dimensions")df.plot(logx=True)df.iloc[[0, 1, 2, 3, -1]]
matching
percentage
dimensions
1
inf
inf
2
inf
inf
3
inf
inf
5
4.0
80.000000
794
202.0
25.440806
What this graph is showing me is that a single orthogonal value becomes increasingly impactful as the number of dimensions increases. In order to counteract a single orthogonal value a large percentage of the remaining values must match. This becomes increasingly unlikely as the number of dimensions grows.
Expressing this relationship mathematically might be interesting. For now I’m going to get on with other things.