How Multilingual is Multi-Genre Natural Language Inference
Published
February 7, 2024
I want to use a MNLI model to do sentiment analysis. It’s an odd situation as you could just train a sentiment classifier, however in this case I want to train the model on a very small amount of data. Using a larger model trained on a more complex task should allow it the context to do well.
Lewis, Mike, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2019. “BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension.”CoRR abs/1910.13461. http://arxiv.org/abs/1910.13461.
Williams, Adina, Nikita Nangia, and Samuel Bowman. 2018. “A Broad-Coverage Challenge Corpus for Sentence Understanding Through Inference.” In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 1112–22. New Orleans, Louisiana: Association for Computational Linguistics. http://aclweb.org/anthology/N18-1101.
Conneau, Alexis, Ruty Rinott, Guillaume Lample, Adina Williams, Samuel R. Bowman, Holger Schwenk, and Veselin Stoyanov. 2018. “XNLI: Evaluating Cross-Lingual Sentence Representations.” In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels, Belgium: Association for Computational Linguistics.
XNLI is a subset of a few thousand examples from MNLI which has been translated into a 14 different languages
How well will BART Large MNLI do on this dataset? I think it will be fun to see. Training these large language models, even monolingually, can involve some understanding of other languages. The datasets that are used can include some text that is in another language. BART large is quite large and so has enough space to have some idea of other languages.
To make this evaluation more interesting I can test BART Large MNLI on the MNLI dataset first, to establish a baseline. Then I can test it against the XNLI dataset where both the passage and hypothesis are in a non-English language. Finally I can test it against the XNLI dataset where the passage is in a non-English language but the hypothesis is in English.
There are XNLI models as well so a comparison to a similar size model that is explicitly trained to do this would be good.
Dataset
As always we will start with the dataset. Getting it is easy as both are available on huggingface.
Let’s start with the mnli dataset, which has two validation datasets (matched and mismatched). The labels are entailment (0), neutral (1), contradiction (2).
The premise column is a dictionary of language code to premise. In comparison the hypothesis column has language and translation columns which are lists that are aligned. Extracting from the hypothesis seems needlessly complicated compared to the premise. Otherwise this is fine.
To evaluate the models I will start with a known-good test, which is to evaluate bart-large-mnli on the mnli dataset. This is what it was trained on and it should perform well.
I’ve encoded the mnli datset to add the hypothesis to the premise and convert them to the tokenized form. Doing this in advance makes inference faster as it can just move from batch to batch.
It’s now time to evaluate this. The model is both large and trained on this specific task so I expect it to do well.
Code
from transformers import AutoModelForSequenceClassification, AutoTokenizerimport datasetsfrom sklearn.metrics import classification_reportimport torchfrom tqdm.auto import tqdmimport numpy as np# the mnli dataset has labels entailment (0), neutral (1), contradiction (2)# the bart-large-mnli has outputs contradiction (0), neutral (1), entailment (2)@torch.inference_mode()def evaluate( model_name: str, ds: datasets.Dataset, batch_size: int=64, label_map: dict= {0: 2, 2: 0}, # FROM model TO dataset detail: bool=True,) ->None: model = AutoModelForSequenceClassification.from_pretrained(model_name) model = model.cuda() model = model.eval() tokenizer = AutoTokenizer.from_pretrained(model_name) predictions = []for index in tqdm(range(0, len(ds), batch_size)): batch = ds.select_columns("input_ids")[index:index+batch_size] encoded = tokenizer.pad(batch, return_tensors="pt") encoded = encoded.to(model.device) output = model(**encoded) output = output.logits.argmax(dim=-1).cpu().tolist()if label_map: output = [label_map.get(value, value) for value in output] predictions.extend(output) predictions = np.array(predictions)if detail: report = classification_report( y_true=ds["label"], y_pred=predictions, target_names=["entailment", "neutral", "contradiction"], )print(report)return (predictions == ds["label"]).mean()
You're using a BartTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
You're using a BartTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
You're using a BartTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
This is the first evaluation which is a sanity check. Here the text is in English, as is the prompt. The score of 91% is very similar to what was observed for the MNLI dataset.
This is great as the XNLI dataset is a subset of the MNLI dataset that has been translated. Let’s try it with a French premise and an English hypothesis.
You're using a BartTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
The performance against the French dataset is actually reasonable. It’s much worse than against English, however it is much better than random chance. I suspect that the underlying bart-large model learnt some French during training and the model is able to harness this. French and English also share a common root (Indo-European) so there may be some way that the model can harness that understanding.
To test this we can run the same evaluation against Arabic, which is a Afro-Asiatic language with a distinct character set.
You're using a BartTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
Here the simple accuracy appears to be better than random, however the model no longer meaningfully predicts entailment. This seems to be a broken model to me.
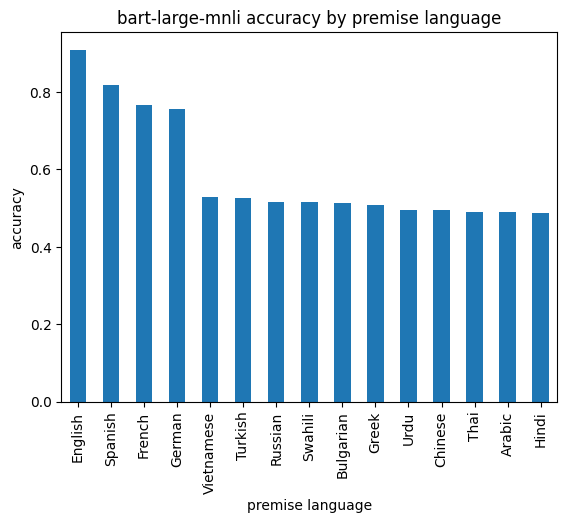
To fully evaluate the model we can compute the accuracy score for every language in the dataset. Remember that the hypothesis will remain in English for all of these.
This clearly shows that the model performance for non English languages is dramatically worse. That’s not a surprise as the XNLI dataset contains a lot of non European languages.
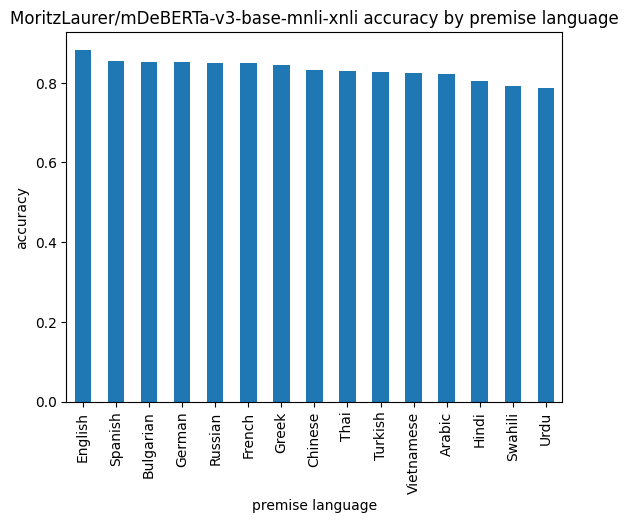
The performance of this model is far more consistent. Unfortunately the performance in English has suffered a little (from 0.91 to 0.88). Moritz Laurer does note the following:
multilingual models tend to be less good than English-only models. For maximum performance, it can be better to first machine translate texts to English and then use an English-only model for zeroshot classification. See the other English-only models in this collection. For free open-source machine translation, I recommend https://github.com/UKPLab/EasyNMT.
For simplicity I will use the multilingual model, as machine translation has it’s own risk.