I want to use whisper (Alec Radford 2022) to transcribe a lot of content. To do this on my home computer I need it to be fast and accurate. Let’s see how fast we can make it while maintaining quality.
I have three copies of this youtube video. It’s a 22 minute video about chess and I’ve created 5 minute and 1 minute versions of it. If I can extract the audio and put it through a summarizer then I don’t need to watch it 😉
Whisper v3
I want to start this by running the v3 large model to establish baselines for both the text and the speed. I’m going to use the settings from the whisper v3 model card. It would also be good to try out increasing the beam size to see if that changes the predicted text.
Ladies and gentlemen, in this video I'm going to be sharing with you
probably the most insane chess world record that I have ever been
lucky to witness. A couple of days ago, a chess game was played on
chess.com. And the two participants involved in that chess game are
Magnus Carlsen, arguably the greatest chess player of all time,
17-time world chess champion, and Faustino Oro. Faustino is 10 years
old, originally from Argentina. Now he's being referred to as,
potentially, the Lionel Messi of chess. Faustino defeated Magnus
Carlsen in the game that they played on chess.com. Faustino did not
- know how to play chess until 2020. Three and a half years ago, he
? ^^^^^^^^
+ know how to play chess until 2020. Three and a half years...
? ^^^
- played chess.
With beam search the transcription is more accurate - the actual utterance is cut off midway through the years word so the single beam hallucinated the end.
We can check the file to hear this in action:
Code
from IPython.display import AudioAudio("gotham-1.mp3")
Using 4 beams is slower though, now it’s slower than real time. I want to speed things up not slow them down!
Distil Whisper v3
There is a distilled version of Whisper v3 large available, running at about half the total parameter count. I’m going to see how well it compares to the original.
Code
from transformers import pipelinev3_distil_pipe = pipeline("automatic-speech-recognition", model="distil-whisper/distil-large-v3", chunk_length_s=30, device="cpu",)
CPU times: user 2min 20s, sys: 16.8 s, total: 2min 37s
Wall time: 16.3 s
This has transcribed the audio using 4 beams faster than the large model managed with 1. Is the quality still good? I’m going to compare it to the 4 beam full version which I will be using as the baseline going forward.
- Ladies and gentlemen, in this video I'm going to be sharing with you+ Ladies and gentlemen, in this video, I'm going to be sharing with you
? +
probably the most insane chess world record that I have ever been
lucky to witness. A couple of days ago, a chess game was played on
- chess.com. And the two participants involved in that chess game are
? ^
+ Chess.com. And the two participants involved in that chess game are
? ^
- Magnus Carlsen, arguably the greatest chess player of all time,
? ^
+ Magnus Carlson, arguably the greatest chess player of all time,
? ^
17-time world chess champion, and Faustino Oro. Faustino is 10 years
- old, originally from Argentina. Now he's being referred to as,
? -
+ old, originally from Argentina. Now he's being referred to as- potentially, the Lionel Messi of chess. Faustino defeated Magnus
? -
+ potentially the Lionel Messi of chess. Faustino defeated Magnus- Carlsen in the game that they played on chess.com. Faustino did not
? ^ -
+ Carlson in the game that they played on chess.com Faustino did not
? ^
- know how to play chess until 2020. Three and a half years...
? ---
+ know how to play chess until 2020. Three and a half years
There is quite a lot of difference here. To be clear the red lines are the baseline, and the green lines are the distil model.
If I ignore the punctuation differences then this is reduced down to the spelling of Magnus Carlsen. The original model gets it right and the distil version makes a mistake with the surname.
This is great. Is this the best it can get?
CTranslate 2
CTranslate 2 supports Whisper. I can use this to try to accelerate the distilled model even further. Let’s give it a go.
To use ctranslate on this I need to convert the model and then load it. The invocation of it will have to change too. It’s easiest to run a command line tool to do the translation, here I quantize the distil-large-v3 model into int8. This version is what I am going to test.
CPU times: user 1min 11s, sys: 16.3 s, total: 1min 27s
Wall time: 9.6 s
This is a bad invocation of ctranslate as I’m processing the chunks in series. I should be processing them in parallel. Even so there is a significant speed improvement from 16 seconds to just under 10 seconds.
Does the quantization harm the quality of the transcription?
compare(baseline_beam["text"], ctranslate_beam)
Ladies and gentlemen, in this video I'm going to be sharing with you
probably the most insane chess world record that I have ever been
lucky to witness. A couple of days ago, a chess game was played on
- chess.com. And the two participants involved in that chess game are
? ^
+ Chess.com. And the two participants involved in that chess game are
? ^
- Magnus Carlsen, arguably the greatest chess player of all time,
? ^
+ Magnus Carlson, arguably the greatest chess player of all time,
? ^
- 17-time world chess champion, and Faustino Oro. Faustino is 10 years
? ^
+ 17-time world chess champion. and Faustino Oro. Faustino is 10 years
? ^
- old, originally from Argentina. Now he's being referred to as,
? -
+ old, originally from Argentina. Now he's being referred to as- potentially, the Lionel Messi of chess. Faustino defeated Magnus
? -
+ potentially the Lionel Messi of chess. Faustino defeated Magnus- Carlsen in the game that they played on chess.com. Faustino did not
? ^
+ Carlson in the game that they played on chess.com. Faustino did not
? ^
- know how to play chess until 2020. Three and a half years...+ know how to play chess until 2020.
None
There is the same variation in punctuation and Carlsen -> Carlson change that the distil model had. However the ctranslate version has not completed the partial utterance of three and a half years.
More broadly my implementation of transcription using ctranslate is lacking.
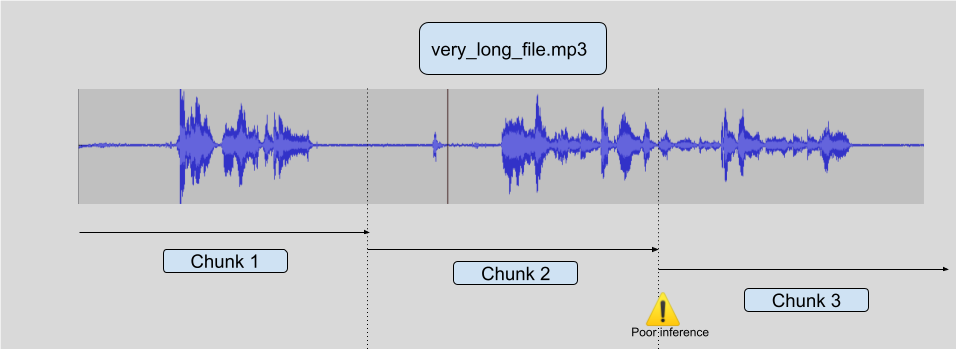
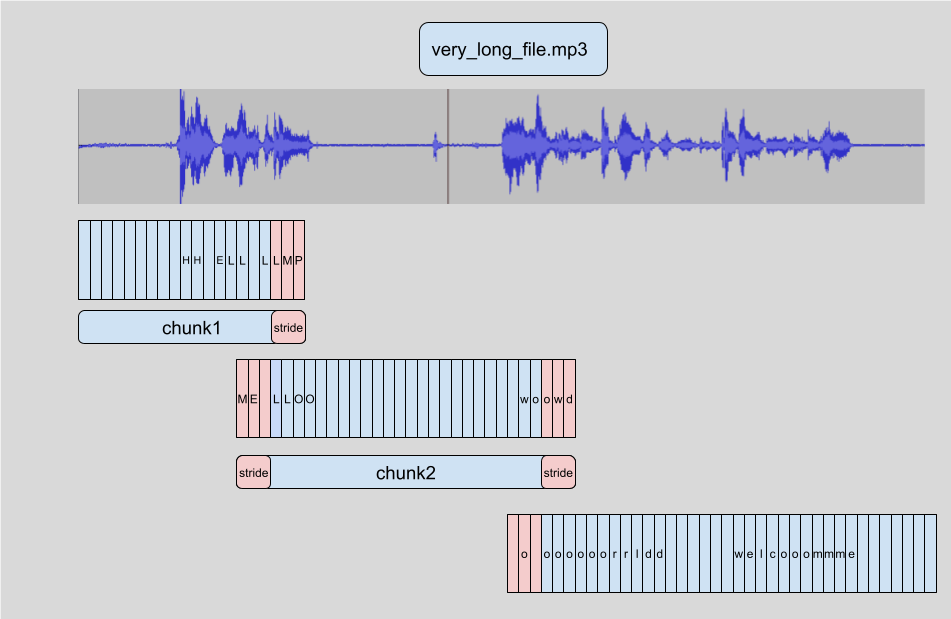
The main problem is that the audio is split into non overlapping 30 second chunks and the results are appended together. It has worked (reasonably) well in this case however there will be plenty of cases where it does not work well.
A smaller issue is that since the audio is split into chunks, the chunks could be processed in parallel to transcribe more quickly. It’s unlikely that the batch processing would lead to big speed improvements as this is running on CPU, it is an indication of the (lack of) quality of the implementation though.
The better implementation of chunking is covered in this huggingface blog post. What I have written is like this:
converting non overlapping chunks
A better implementation is like this:
providing context to chunks
All of this goodness is implemented in the huggingface AutomaticSpeechRecognitionPipeline. If I can get the ctranslate code working with that then I can benefit from these improvements for free.
CTranslate and Huggingface
I’ve hacked around with this a lot and read a lot of the pipeline code. Huggingface writes excellent code that is normally very easy to follow. The pipeline abstraction that they provide is conceptually simple, however it is hard to see how to integrate the ctranslate model into it cleanly.
I don’t need a perfect implementation, I just want to try this approach out. As such the easiest way to find how to integrate it is to actually invoke the huggingface pipeline and track how it is invoking the model. To do this I have created a very hacky class to track the different methods that are called and the arguments that they are called with.
I only need to concern myself with the whisper model and not the preprocessor or tokenizer as the ctranslate version uses the huggingface classes for them.
Code
from __future__ import annotationsfrom typing import Iteratorfrom functools import wrapsfrom transformers.modeling_outputs import BaseModelOutputfrom contextlib import contextmanagerimport transformers@contextmanagerdef track(pipeline: transformers.Pipeline) -> Iterator[None]:class Watcher:def__init__(self, model):self.model = modeldef__getattr__(self, name: str):returnself._resolve(name)def__call__(self, *args, **kwargs): call =self._resolve("__call__")return call(*args, **kwargs)def _resolve(self, name: str): my_name =self.model.__class__.__name__print(f"resolving {my_name}.{name}") value =getattr(self.model, name)ifnotcallable(value):return value@wraps(value)def wrapper(*args, **kwargs): value_name = value.__name__ formatted_arguments = _pretty_args(*args, **kwargs)print(f"calling {my_name}.{value_name}({formatted_arguments})") result = value(*args, **kwargs)print(f"\tit returned {_pretty_value(result)}")if _should_wrap(result):print(f"\ttracking ...")return Watcher(result)return resultreturn wrapperdef _pretty_args(*args, **kwargs) ->str: args =", ".join(map(_pretty_value, args)) kwargs =", ".join(f"{key}={_pretty_value(value)}"for key, value in kwargs.items() )return", ".join(string for string in [args, kwargs] if string)def _pretty_value(value) ->str:ifisinstance(value, torch.Tensor):returnf"tensor(shape={list(value.shape)})"if _is_class_instance(value):# return type(value)return value.__class__.__name__returnstr(value)def _should_wrap(value) ->bool:ifisinstance(value, (BaseModelOutput, torch.Tensor, Watcher)):returnFalsereturn _is_class_instance(value)def _is_class_instance(value) ->bool:# is the value an instance of a class# hard to tell apparently, this is a hackreturnhasattr(value, "__dict__") original = pipeline.modeltry: pipeline.model = Watcher(original)yieldfinally: pipeline.model = original
With this tracker I wrap the model in the pipeline and it will show every attribute that is accessed and every method that is called. This will show me what the ctranslate version needs to implement.
with track(v3_pipe): baseline = transcribe(v3_pipe, "gotham-1.mp3")
resolving WhisperForConditionalGeneration.config
resolving WhisperForConditionalGeneration.get_encoder
calling WhisperForConditionalGeneration.get_encoder()
it returned WhisperEncoder
tracking ...
resolving WhisperEncoder.__call__
calling WhisperEncoder._wrapped_call_impl(tensor(shape=[3, 128, 3000]), attention_mask=None)
it returned BaseModelOutput
resolving WhisperForConditionalGeneration.generate
calling WhisperForConditionalGeneration.generate(attention_mask=None, max_new_tokens=448, return_timestamps=True, encoder_outputs=BaseModelOutput)
it returned tensor(shape=[3, 94])
resolving WhisperForConditionalGeneration.config
This shows me that the encoder is used to generate output that is then passed on to the ctranslate model itself. The encoder output is wrapped in a BaseModelOutput. I’ve picked through this code a little and I didn’t wrap the BaseModelOutput because there is a specific test for it using isinstance in transformers.models.whisper.generation_whisper:
@staticmethoddef _retrieve_total_input_frames(input_features, input_stride, kwargs):if input_features isnotNone:return input_features.shape[-1]if"encoder_outputs"in kwargs: encoder_outputs_shape = ( kwargs["encoder_outputs"][0].shapeifisinstance(kwargs["encoder_outputs"], BaseModelOutput)else kwargs["encoder_outputs"].shape )return encoder_outputs_shape[1] * input_strideraiseValueError("Make sure to provide either `input_features` or `encoder_outputs` to `generate`.")
Can I create the BaseModelOutput using the ctranslate encoder?
If I look back at the ctranslate code, I can see
def transcribe_chunk(audio: np.array) ->list[int]:# Compute the features of the first 30 seconds of audio. inputs = processor(audio, return_tensors="np", sampling_rate=sampling_rate) features = ctranslate2.StorageView.from_array(inputs.input_features)# Run generation for the 30-second window. results = model.generate( features, [prompt], beam_size=4, num_hypotheses=1, )return results[0].sequences_ids[0]
This generates features and then passes them to the generate function. The features are from the processor which is a transformers object. If the encoder just provides this as the BaseModelOutput then that would likely be sufficient.
The pipeline does pass around tensors a lot. These tensors can be easily converted to the numpy arrays as the tensor.numpy() and tensor.from_numpy() operations use a view over the underlying data so do not involve copy operations. This would require forcing the pipeline to be cpu only (which is desirable anyway).
- Ladies and gentlemen, in this video I'm going to be sharing with you+ Ladies and gentlemen, in this video, I'm going to be sharing with you
? +
probably the most insane chess world record that I have ever been
lucky to witness. A couple of days ago, a chess game was played on
- chess.com. And the two participants involved in that chess game are
? ^
+ Chess.com. And the two participants involved in that chess game are
? ^
- Magnus Carlsen, arguably the greatest chess player of all time,
? ^
+ Magnus Carlson, arguably the greatest chess player of all time,
? ^
17-time world chess champion, and Faustino Oro. Faustino is 10 years
- old, originally from Argentina. Now he's being referred to as,
? -
+ old, originally from Argentina. Now he's being referred to as- potentially, the Lionel Messi of chess. Faustino defeated Magnus
? -
+ potentially the Lionel Messi of chess. Faustino defeated Magnus- Carlsen in the game that they played on chess.com. Faustino did not
? ^ ^
+ Carlson in the game that they played on Chess.com. Faustino did not
? ^ ^
know how to play chess until 2020. Three and a half years...
Comparing this to my own version, this is now 11 seconds instead of 9.6s. On the plus side it does capture the Three and a half years… utterance, which shows that the ctranslate model is capable of doing that.
I’m struggling to get it to output the timestamps for the sections. It turns out that they are available if I transcribe a longer audiofile.
CPU times: user 6min 27s, sys: 1min 32s, total: 7min 59s
Wall time: 58.1 s
{'timestamp': (0.0, 4.6),
'text': " Ladies and gentlemen, in this video, I'm going to be sharing with you"}
We can see here that for a 5 minute file the transcription time now takes 58 seconds. That’s slightly worse than linear (would expect 55 seconds) and is likely due to the striding.
This does show that it’s possible to fit the ctranslate models into the huggingface pipeline system. I think that’s rather neat. A more complete implementation would pay more attention to the arguments to generate, as there is likely quite a bit I have missed there.
Faster Whisper
Why do all that when there is a library just to run ctranslate whisper fast? Faster Whisper describes itself as:
faster-whisper is a reimplementation of OpenAI’s Whisper model using CTranslate2, which is a fast inference engine for Transformer models.
This implementation is up to 4 times faster than openai/whisper for the same accuracy while using less memory. The efficiency can be further improved with 8-bit quantization on both CPU and GPU.
I would like to compare this to my raw implementation and the huggingface pipeline.
Code
from typing import Iteratorimport faster_whisperclass FasterWhisper:def__init__(self, model_name: str="large-v3") ->None:self.model = faster_whisper.WhisperModel( model_name, device="cpu", compute_type="int8", )def transcribe(self,file: str, num_beams: int=4,**kwargs, ) ->str: segments, info =self._transcribe(file, beam_size=num_beams, **kwargs) text =" ".join(segment.text.strip() for segment in segments)return text# just to add type annotationsdef _transcribe(self, file: str, **kwargs) -> Tuple[ faster_whisper.transcribe.TranscriptionInfo, faster_whisper.transcribe.TranscriptionInfo, ]:returnself.model.transcribe(file,**kwargs, )
This fails and yet the distil-large-v3 model is compatible with ctranslate. There is a ticket which indicates that the _MODELS dict in faster_whisper.utils needs to be updated. Since this can, apparently, just take folders or huggingface identifiers I might be able to get it working without changing the code.
%%timefaster_output = faster_model.transcribe("gotham-1.mp3", language="en", # prevents language detection num_beams=4, best_of=1, # num_hypothesis alias, see transcribe.py:798)
CPU times: user 34.1 s, sys: 5.79 s, total: 39.9 s
Wall time: 11.2 s
compare(baseline_beam["text"], faster_output)
- Ladies and gentlemen, in this video I'm going to be sharing with you+ Ladies and gentlemen, in this video, I'm going to be sharing with you
? +
probably the most insane chess world record that I have ever been
lucky to witness. A couple of days ago, a chess game was played on
- chess.com. And the two participants involved in that chess game are
? ^
+ Chess.com. And the two participants involved in that chess game are
? ^
- Magnus Carlsen, arguably the greatest chess player of all time,
? ^
+ Magnus Carlson, arguably the greatest chess player of all time,
? ^
- 17-time world chess champion, and Faustino Oro. Faustino is 10 years
? ^^^ ^^ ^ ^^^^^^^^^^^^
+ 17-time world chess champion. And Faustino a lot, and Faustino,
? ^^^ ^^^ ^^^^^^ ^
+ Fostino did not he's being referred to as potentially, Fostino did not+ know how to do not know how to play chess, Fostino did not know how to+ play chess.- old, originally from Argentina. Now he's being referred to as,- potentially, the Lionel Messi of chess. Faustino defeated Magnus- Carlsen in the game that they played on chess.com. Faustino did not- know how to play chess until 2020. Three and a half years...
While this matches the speed of the huggingface version the output is noticeably worse. The name Faustino Oro is spelt as Faustino a lot and Fostino. Errors with names is something that I can accept as names are essentially arbitrary collections of sounds and this is an unusual (to me) name.
What is unacceptable is the noticeable hallucination at the end:
Fostino did not know how to do not know how to play chess, Fostino did not know how to play chess.
which has made up text and misses quite a lot of audio. I have tried to reproduce the settings that were used in the huggingface pipeline, so there must be something in the way that faster whisper does it’s work that causes this problem.
for temperature in options.temperatures:if temperature >0: kwargs = {"beam_size": 1,"num_hypotheses": options.best_of,"sampling_topk": 0,"sampling_temperature": temperature, }else: kwargs = {"beam_size": options.beam_size,"patience": options.patience, }
The default temperature for the huggingface pipeline is 1, which forces the beam_size to be 1 and topk to be 0 (instead of beam_size 4 and topk 1). I imagine that a top-k of zero disables top-k filtering entirely as the top-k number is the number of options to retain (so a topk of 1 restricts the choice to only the most probable token, i.e. disables temperature sampling).
I can disable the temperature fiddles however I cannot restore the beam size search. This makes faster-whisper unsuitable for me.
Just to check this I am going to disable the temperature sampling to see how the else block performs.
%%timefaster_output_temperature = faster_model.transcribe("gotham-1.mp3", language="en", # prevents language detection num_beams=4, best_of=1, # num_hypothesis alias, see transcribe.py:798 temperature=0.,)
CPU times: user 35 s, sys: 5.98 s, total: 41 s
Wall time: 11.4 s
- Ladies and gentlemen, in this video I'm going to be sharing with you+ Ladies and gentlemen, in this video, I'm going to be sharing with you
? +
probably the most insane chess world record that I have ever been
lucky to witness. A couple of days ago, a chess game was played on
- chess.com. And the two participants involved in that chess game are
? ^
+ Chess.com. And the two participants involved in that chess game are
? ^
- Magnus Carlsen, arguably the greatest chess player of all time,
? ^
+ Magnus Carlson, arguably the greatest chess player of all time,
? ^
- 17-time world chess champion, and Faustino Oro. Faustino is 10 years
? ^^^ ^^ ^ ^^^^^^^^^^^^
+ 17-time world chess champion. And Faustino a lot, and Faustino,
? ^^^ ^^^ ^^^^^^ ^
+ Fostino did not he's being referred to as potentially, Fostino did not+ know how to do not know how to play chess, Fostino did not know how to+ play chess.- old, originally from Argentina. Now he's being referred to as,- potentially, the Lionel Messi of chess. Faustino defeated Magnus- Carlsen in the game that they played on chess.com. Faustino did not- know how to play chess until 2020. Three and a half years...
Disabling the temperature sampling did nothing. Boo! Boo!
Whisper X
There is another package that builds on faster-whisper and adds some nice features. Whisper X (Bain et al. 2023) uses faster-whisper and provides speaker diarization (identification of different speakers). This would be really good as I can then separate by speaker when there is a conversation.
Bain, Max, Jaesung Huh, Tengda Han, and Andrew Zisserman. 2023. “WhisperX: Time-Accurate Speech Transcription of Long-Form Audio.”INTERSPEECH 2023.
This library works with the distilled whisper models. Let’s see if I can get it all working.
Code
from typing import Iterableimport whisperximport numpy as npclass WhisperX:def__init__(self, model_name: str, num_beams: int=4, num_hypothesis: int=1, max_new_tokens: int=448, language: str="en",**kwargs, ) ->None:# example code lacks the asr_options.# the options are required to load the model without error!# https://github.com/m-bain/whisperX/issues/721#issuecomment-2030084511# the minimal fix is:# asr_options={# "max_new_tokens": None,# "clip_timestamps": None,# "hallucination_silence_threshold": None,# }# I have tried to replicate the huggingface settings,# except beam_size which has been 4 throughout this.# the asr_options are defined here:# https://github.com/m-bain/whisperX/blob/main/whisperx/asr.py#L300-L326# and at the time of writing that has the fixself.model = whisperx.load_model( model_name, device="cpu", compute_type="int8", language=language, asr_options={"max_new_tokens": max_new_tokens, # bugfix recommended None"clip_timestamps": None,"hallucination_silence_threshold": None,"beam_size": num_beams,"best_of": num_hypothesis,**kwargs, } )self.language = languagedef transcribe(self,file: str, batch_size: int=16,**kwargs, ) ->str: audio =self._load(file) result =self._transcribe(audio, batch_size=batch_size, **kwargs) text =" ".join( segment["text"].strip()for segment in result["segments"] )return textdef _load(self, file: str) -> np.array:return whisperx.load_audio(file)def _transcribe(self, audio: np.array, batch_size: int,**kwargs, ) -> whisperx.types.TranscriptionResult:returnself.model.transcribe( audio, batch_size=batch_size, language=self.language, )
Model was trained with pyannote.audio 0.0.1, yours is 3.1.1. Bad things might happen unless you revert pyannote.audio to 0.x.
Model was trained with torch 1.10.0+cu102, yours is 2.2.0+cu121. Bad things might happen unless you revert torch to 1.x.
The model may’ve been trained with those old versions but there is no way I’m downgrading either of those libraries. Let’s press on and see what happens.
CPU times: user 34.2 s, sys: 6.19 s, total: 40.4 s
Wall time: 11.2 s
Code
compare(baseline_beam["text"], whisperx_output)
- Ladies and gentlemen, in this video I'm going to be sharing with you+ Ladies and gentlemen, in this video, I'm going to be sharing with you
? +
probably the most insane chess world record that I have ever been
lucky to witness. A couple of days ago, a chess game was played on
chess.com. And the two participants involved in that chess game are
- Magnus Carlsen, arguably the greatest chess player of all time,
? ^
+ Magnus Carlson, arguably the greatest chess player of all time,
? ^
- 17-time world chess champion, and Faustino Oro. Faustino is 10 years
? ^
+ 17-time world chess champion. and Faustino Oro. Faustino is 10 years
? ^
- old, originally from Argentina. Now he's being referred to as,
? -
+ old, originally from Argentina. Now he's being referred to as- potentially, the Lionel Messi of chess. Faustino defeated Magnus
? -
+ potentially the Lionel Messi of chess. Faustino defeated Magnus- Carlsen in the game that they played on chess.com. Faustino did not
? ^ ^
+ Carlson in the game that they played on Chess.com. Faustino did not
? ^ ^
- know how to play chess until 2020. Three and a half years...
? ^^^ ---
+ know how to play chess until 2020, three and a half years
? ^^^
This is interesting. The whisperx model is able to transcribe the audio well, producing the same kind of variance as the basic distil model (punctuation, Carlsen -> Carlson). This is even though the underlying faster-whisper model had great trouble with the end of the utterance. Whisper X is also able to run as fast as faster-whisper or ctranslate huggingface.
Whisper X Diarization
Diarization is the assignment of separate speakers to different parts of the text. The Whisper X library supports using the pyannote speaker diarization model (Plaquet and Bredin 2023)(Bredin 2023) which we can now try out.
Plaquet, Alexis, and Hervé Bredin. 2023. “Powerset Multi-Class Cross Entropy Loss for Neural Speaker Diarization.” In Proc. INTERSPEECH 2023.
Bredin, Hervé. 2023. “pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe.” In Proc. INTERSPEECH 2023.
Before running diarization the Whisper X documentation recommends improving the word boundary alignment first. Since this post is about speed I want to see how much time it takes.
Code
from typing import Iterable, TypedDictimport whisperximport numpy as npclass DiarizedWord(TypedDict): word: str start: float end: float score: float speaker: strclass DiarizedSegment(TypedDict): start: float end: float text: str words: list[DiarizedWord]class DiarizedAudio(TypedDict): segments: list[DiarizedSegment] word_segments: list[DiarizedWord]class WhisperXExtended:def__init__(self, model_name: str, num_beams: int=4, num_hypothesis: int=1, max_new_tokens: int=448, load_alignment: bool=True, load_diarization: bool=False, language: str="en",**kwargs, ) ->None:# example code lacks the asr_options.# the options are required to load the model without error!# https://github.com/m-bain/whisperX/issues/721#issuecomment-2030084511# the minimal fix is:# asr_options={# "max_new_tokens": None,# "clip_timestamps": None,# "hallucination_silence_threshold": None,# }# I have tried to replicate the huggingface settings,# except beam_size which has been 4 throughout this.# the asr_options are defined here:# https://github.com/m-bain/whisperX/blob/main/whisperx/asr.py#L300-L326# and at the time of writing that has the fixself.model = whisperx.load_model( model_name, device="cpu", compute_type="int8", language=language, asr_options={"max_new_tokens": max_new_tokens, # bugfix recommended None"clip_timestamps": None,"hallucination_silence_threshold": None,"beam_size": num_beams,"best_of": num_hypothesis,**kwargs, } )if load_alignment:self.alignment_model, self.alignment_metadata = whisperx.load_align_model( language_code=language, device=device, )if load_diarization:self.diarization_pipeline = whisperx.DiarizationPipeline()self.language = languagedef transcribe(self,file: str, align: bool=False, batch_size: int=16,**kwargs, ) ->str: audio =self._load(file) result =self._transcribe(audio, batch_size=batch_size, **kwargs)if align: result =self._align(audio, segments=result["segments"]) text =" ".join( segment["text"].strip()for segment in result["segments"] )return textdef diarize(self,file: str, align: bool=False, batch_size: int=16,**kwargs, ) -> DiarizedAudio: audio =self._load(file) result =self._transcribe(audio, batch_size=batch_size, **kwargs)if align: result =self._align(audio, segments=result["segments"]) result =self._diarize(audio, result)return resultdef _load(self, file: str) -> np.array:return whisperx.load_audio(file)def _transcribe(self, audio: np.array, batch_size: int,**kwargs, ) -> whisperx.types.TranscriptionResult:returnself.model.transcribe( audio, batch_size=batch_size, language=self.language, )def _align(self, audio: np.array, segments: Iterable[whisperx.types.SingleSegment] ) -> whisperx.types.AlignedTranscriptionResult:asserthasattr(self, "alignment_model"), "did not load alignment model when creating WhisperX"return whisperx.align( audio=audio, transcript=segments, model=self.alignment_model, align_model_metadata=self.alignment_metadata, device="cpu", return_char_alignments=False, )def _diarize(self, audio: np.array, result: whisperx.types.AlignedTranscriptionResult, ): diarize_segments =self.diarization_pipeline(audio)return whisperx.assign_word_speakers(diarize_segments, result)
Model was trained with pyannote.audio 0.0.1, yours is 3.1.1. Bad things might happen unless you revert pyannote.audio to 0.x.
Model was trained with torch 1.10.0+cu102, yours is 2.2.0+cu121. Bad things might happen unless you revert torch to 1.x.
CPU times: user 46.1 s, sys: 5.56 s, total: 51.7 s
Wall time: 14.4 s
compare(whisperx_output, whisperx_aligned_output)
Ladies and gentlemen, in this video, I'm going to be sharing with you
probably the most insane chess world record that I have ever been
lucky to witness. A couple of days ago, a chess game was played on
chess.com. And the two participants involved in that chess game are
Magnus Carlson, arguably the greatest chess player of all time,
17-time world chess champion. and Faustino Oro. Faustino is 10 years
old, originally from Argentina. Now he's being referred to as
potentially the Lionel Messi of chess. Faustino defeated Magnus
Carlson in the game that they played on Chess.com. Faustino did not
know how to play chess until 2020, three and a half years
Alignment costs about 30% more time and does not alter the text at all. With this done we can now diarize the audio to separate it by distinct speaker.
CPU times: user 2min 14s, sys: 6.18 s, total: 2min 20s
Wall time: 37.4 s
This has now become a significant slowdown, more than doubling the total time taken. To use this you would really have to need it. My example audio is only for a single speaker though. It is worth bearing in mind that both the alignment and diarization are unoptimized, so it might be possible to see similar speed gains.
If I review the diarized output then I can see it has split the text into every individual word and assigned a speaker to each. That’s neat for interviews. It does this by clustering the audio signature of the chunks. There is a nice youtube video by pyannote if you want to learn more.