Large language models are great however relying on the information within them is not so great. That information is hard to audit or update. The decisions that the model makes based on it can seem arbitrary or harmful.
Providing the facts to the model can help with this a lot. Retrieval augmented generation (RAG) is the process of collecting related text and providing it to the model as a reference. Then when the model generates the response it can incorporate details from the reference material.
To implement RAG effectively you need a lot of documents and an effective way to search over them. A problem with this is when the request from the user is not well represented in your documents. It would be nice to be able to generate documentation which was accurate from the web of facts that are present in your existing corpus.
To do that we need to extract the facts from the corpus, as well as the relationships between them. That is what I am working on today.
Fact Score
The FActScore (Min et al. 2023) was where I found a nice systematic approach for this, along with an evaluation. I am going to start with the prompts and examples from this repository and see how far I can get with a local model.
Min, Sewon, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. “FActScore: Fine-Grained Atomic Evaluation of Factual Precision in Long Form Text Generation.” In EMNLP. https://arxiv.org/abs/2305.14251.
Wei, Jerry, Chengrun Yang, Xinying Song, Yifeng Lu, Nathan Hu, Jie Huang, Dustin Tran, et al. 2024. “Long-Form Factuality in Large Language Models.”https://arxiv.org/abs/2403.18802.
The FActScore code was used in the (Wei et al. 2024) paper by Google, and they have provided the code here which uses the FActScore data with a specific prompt. Since it’s google using that prompt to start with would be a great idea. I can try using this with the Llama-3.2 3B Instruct model to start with.
# from src/main/python/blog/llm/continuation.pyfrom __future__ import annotationsimport refrom typing import Optionalimport torchfrom transformers import ( AutoModelForCausalLM, AutoTokenizer, StoppingCriteria, StoppingCriteriaList,)@torch.inference_mode()def generate_continuation(*, model: AutoModelForCausalLM, tokenizer: AutoTokenizer, prompt: str, stopping: Optional[str|list[str]] =None, max_new_tokens: int=100, additional_stopping: Optional[list[StoppingCriteria]] =None, do_sample: bool=False, temperature: Optional[float] =None, top_p: Optional[float] =None,**kwargs,) ->str: stopping_criteria = [] token_sequence_stopping = []if stopping:ifnotisinstance(stopping, list): stopping = [stopping] token_sequence_stopping = [ TokenSequenceStoppingCriteria.make( tokenizer=tokenizer, sequence=sequence, device=model.device, )for sequence in stopping ] stopping_criteria.extend(token_sequence_stopping)if additional_stopping: stopping_criteria.extend(additional_stopping)if stopping_criteria: stopping_criteria_object = StoppingCriteriaList(stopping_criteria)else: stopping_criteria_object =None model_input = tokenizer( prompt, return_tensors="pt", padding="longest", ) input_tokens = model_input.input_ids.shape[1] model_input = model_input.to(model.device) generated_ids = model.generate(**model_input, max_new_tokens=max_new_tokens, do_sample=do_sample, temperature=temperature, top_p=top_p, pad_token_id=tokenizer.pad_token_id, stopping_criteria=stopping_criteria_object, ) filtered_ids = generated_ids[0, input_tokens:]if stopping:for criteria in token_sequence_stopping:ifnot criteria.is_end(filtered_ids):continue filtered_ids = criteria.truncate(filtered_ids)break output = tokenizer.decode( filtered_ids, skip_special_tokens=True, )return output.strip()class TokenSequenceStoppingCriteria(StoppingCriteria):@staticmethoddef make( tokenizer: AutoTokenizer, sequence: str, device: Optional[str| torch.device] =None, ) -> TokenSequenceStoppingCriteria: stopping_tokens = tokenizer( sequence, add_special_tokens=False, ).input_ids# mistral tokenization is unusual, a zero length token can# get added at the start of the sequence which can prevent# the tokenized sequence matching the generated tokens.# this filter drops any zero length tokens. stopping_tokens = [ token for token in stopping_tokens iflen(tokenizer.decode(token)) >0 ]return TokenSequenceStoppingCriteria(stopping_tokens, device=device)def__init__(self, sequence: list[int] | torch.Tensor, device: Optional[str| torch.device] =None, ) ->None:super().__init__()ifisinstance(sequence, list): sequence = torch.Tensor(sequence)if device isnotNone: sequence = sequence.to(device)self.sequence = sequencedef to(self, device: str| torch.device) -> TokenSequenceStoppingCriteria:self.sequence =self.sequence.to(device)returnselfdef as_list(self) -> StoppingCriteriaList:return StoppingCriteriaList([self])def__call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor,**kwargs, ) ->bool:# this assumes only a single sequence is being generatedreturnself.is_end(input_ids[0])def is_end(self, tokens: torch.Tensor) ->bool:assertlen(tokens.shape) ==1iflen(tokens) <len(self.sequence):returnFalse end = tokens[-len(self.sequence) :] per_token_matches = end ==self.sequencereturnbool(per_token_matches.all())def truncate(self, tokens: torch.Tensor) -> torch.Tensor:ifself.is_end(tokens):return tokens[: -len(self.sequence)]return tokensclass RepeatedStringStoppingCriteria(StoppingCriteria):def__init__(self, tokenizer: AutoTokenizer, start_length: int) ->None:super().__init__()self.tokenizer = tokenizerself.start_length = start_lengthself.pattern = re.compile(r'"([^"]*)"')def__call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor,**kwargs, ) ->bool: generated_ids = input_ids[0, self.start_length :] generated_text =self.tokenizer.decode(generated_ids) generated_strings =self.pattern.findall(generated_text)returnlen(set(generated_strings)) !=len(generated_strings)
I can check that the model has loaded correctly and that my code works by asking a simple question. The model should’ve internalized the answer to this question:
generate_continuation( model=model, tokenizer=tokenizer, prompt="Q: What is the capital of France?\nA:", stopping="Q:",)
'Paris'
Easy.
With this I now want to try to break down a sentence into individual facts. The FactScore code uses the NLTK sentence tokenizer to extract sentences from paragraphs. Let’s see how well it can handle the first paragraph of the deep learning article on wikipedia:
Deep learning is a subset of machine learning methods that utilize neural networks for representation learning. The field takes inspiration from biological neuroscience and is centered around stacking artificial neurons into layers and “training” them to process data. The adjective “deep” refers to the use of multiple layers (ranging from three to several hundred or thousands) in the network. Methods used can be either supervised, semi-supervised or unsupervised.
from nltk.tokenize import sent_tokenizeparagraph ="""Deep learning is a subset of machine learning methods that utilize neural networksfor representation learning. The field takes inspiration from biological neuroscienceand is centered around stacking artificial neurons into layers and "training" them toprocess data. The adjective "deep" refers to the use of multiple layers (ranging fromthree to several hundred or thousands) in the network. Methods used can be eithersupervised, semi-supervised or unsupervised."""paragraph = paragraph.strip().replace("\n", " ")sentences = sent_tokenize(paragraph)
task ="""Instructions:1. You are given a sentence. Your task is to break the sentence down into a \list of atomic facts.2. An atomic fact is a sentence containing a singular piece of information.3. Each atomic fact in the outputted list should check a different piece of \information.4. Use the previous examples to learn how to do this.5. You should only output the atomic facts as a list, with each item starting \with "- ". Do not include other formatting.6. Your task is to do this for the last sentence that is given.""".strip()
from textwrap import wrapoutput = generate_continuation( model=model, tokenizer=tokenizer, prompt=f"{task}\n\n{sentences[0]}\n", stopping=".\n\n",)print("Sentence provided to model:")print("\n".join(wrap(sentences[0])))print()print("Atomic facts extracted by model:")print(output)
Sentence provided to model:
Deep learning is a subset of machine learning methods that utilize
neural networks for representation learning.
Atomic facts extracted by model:
- Deep learning is a subset of machine learning.
- Machine learning methods utilize neural networks.
- Neural networks are used for representation learning
I think this is a huge success. The model didn’t even need any examples. The lack of examples did make defining the stopping criteria a little tricky, I’m still really pleased with this.
If we review the paragraph we can see that the second sentence refers to the field, which is a reference to deep learning. Passing this in to the model we would get facts about the field however it would be more useful to replace that reference with the referent, deep learning. Before we start changing the sentences we can see how well the model performs on the second sentence:
from textwrap import wrapoutput = generate_continuation( model=model, tokenizer=tokenizer, prompt=f"{task}\n\n{sentences[1]}\n", stopping=".\n\n",)print("Sentence provided to model:")print("\n".join(wrap(sentences[1])))print()print("Atomic facts extracted by model:")print(output)
Sentence provided to model:
The field takes inspiration from biological neuroscience and is
centered around stacking artificial neurons into layers and "training"
them to process data.
Atomic facts extracted by model:
The field takes inspiration from biological neuroscience and is centered around stacking artificial neurons into layers and "training" them to process data.
The field of artificial intelligence is centered around the idea of creating machines that can think and learn like humans.
The field of artificial intelligence is centered around the idea of creating machines that can think and learn like humans.
The field of artificial intelligence is centered around the idea of creating machines that can think and learn like humans.
The field of artificial intelligence is centered around the idea of creating
The model did not handle this well at all. The output is incorrectly formatted and repetative. Now is the time to change the prompt to include examples.
Luckily the FactScore repository has extensive examples available! I can use this to create a few shot prompt (the file I am using is here).
Code
from pathlib import Pathimport pandas as pdimport jsonFACT_SCORE_FILE = Path(".").resolve() /"demos/demons.json"raw_data = json.loads(FACT_SCORE_FILE.read_text())example_df = pd.DataFrame({"sentence": raw_data.keys(), "facts": raw_data.values()})example_df
sentence
facts
0
He made his acting debut in the film The Moon ...
[He made his acting debut in the film., He mad...
1
He is also a successful producer and engineer,...
[He is successful., He is a producer., He is a...
2
In 1963, Collins became one of the third group...
[Collins became an astronaut., Collins became ...
3
In addition to his acting roles, Bateman has w...
[Bateman has acting roles., Bateman has writte...
4
Michael Collins (born October 31, 1930) is a r...
[Michael Collins was born on October 31, 1930....
5
He was an American composer, conductor, and mu...
[He was an American., He was a composer., He w...
6
She currently stars in the romantic comedy ser...
[She currently stars in Love and Destiny., Lov...
7
His music has been described as a mix of tradi...
[His music has been described as a mix., His m...
8
He also serves as an ambassador for the charit...
[He serves as an ambassador., He serves as an ...
9
He began his career in Nashville in the late 1...
[He began his career in Nashville., He began h...
10
He has been performing since the age of 8, whe...
[He has been performing since the age of 8., H...
11
She is also the former President of the Malays...
[She is the former President., She is also the...
12
During his professional career, McCoy played f...
[McCoy played for the Broncos., McCoy played f...
13
Miller has been described as the architect of ...
[Miller has been described as the architect., ...
14
Her work is often described as whimsical and d...
[Her work is often described as whimsical., He...
15
He graduated from the United States Military A...
[He graduated from the United States Military ...
16
He is best known for his roles in the films Me...
[One of his best known roles is in Memories of...
17
Song Kang-ho was born in Gongju, South Korea i...
[Song Kang-ho was born in Gongju., Song Kang-h...
18
He studied theater at Chung-Ang University in ...
[He studied theater., He studied at Chung-Ang ...
19
His breakthrough came with the leading role in...
[His breakthrough came with Memories of Murder...
20
This was followed by the monster movie The Hos...
[This was followed by The Host., The Host is t...
I need to turn these sentences and facts into an example I can feed into the model. Since the model will now see several sentences we can introduce the sentence and examples with a prefix. This will make defining the stopping condition for token generation much easier - when the model generates the next sentence we can stop.
Sentence:
He made his acting debut in the film The Moon is the Sun's Dream (1992), and continued to appear in small and supporting roles throughout the 1990s.
Facts:
- He made his acting debut in the film.
- He made his acting debut in The Moon is the Sun's Dream.
- The Moon is the Sun's Dream is a film.
- The Moon is the Sun's Dream was released in 1992.
- After his acting debut, he appeared in small and supporting roles.
- After his acting debut, he appeared in small and supporting roles throughout the 1990s.
The prompt specifically instructed the model to alter the last sentence. While this continues to be true our inputs have changed and I think that this instruction might be misleading. Removing the instruction should be fine.
few_shot_task ="""Instructions:1. You are given a sentence. Your task is to break the sentence down into a \list of atomic facts.2. An atomic fact is a sentence containing a singular piece of information.3. Each atomic fact in the outputted list should check a different piece of \information.4. Use the previous examples to learn how to do this.5. You should only output the atomic facts as a list, with each item starting \with "- ". Do not include other formatting.""".strip()
Now we can see how the model handles the second sentence again (notice how the stopping parameter has changed to the prefix for the sentence):
from textwrap import wrapexamples = to_examples(example_df.iloc[0])output = generate_continuation( model=model, tokenizer=tokenizer, prompt=f"{few_shot_task}\n\n{examples}\n\nSentence:\n{sentences[1]}\n\nFacts:\n", stopping="Sentence:\n",)print("Sentence provided to model:")print("\n".join(wrap(sentences[1])))print()print("Atomic facts extracted by model:")print(output)
Sentence provided to model:
The field takes inspiration from biological neuroscience and is
centered around stacking artificial neurons into layers and "training"
them to process data.
Atomic facts extracted by model:
- The field takes inspiration from biological neuroscience.
- The field is centered around stacking artificial neurons into layers.
- Artificial neurons are stacked into layers.
- The field is centered around "training" artificial neurons to process data.
- Artificial neurons are trained to process data.
With a single example the model is now extracting the facts correctly. This is a great start and a nice demonstration of the concept. For this to be useful I want to resolve references to things that were previously introduced, as that will make these facts self contained.
Coreference Resolution
The problem of resolving the field into deep learning is referred to as coreference resolution and as always wikipedia has a good article on it. There is a coreference resolver library available on huggingface. Let’s give that a go.
…
Unfortunately the project is abandoned and no longer works with recent versions of python. There are lots of issues about it.
[['Deep learning', 'The field'], ['artificial neurons', 'them']]
This has quickly grouped deep learning and the field together. If we recall the original paragraph:
Deep learning is a subset of machine learning methods that utilize neural networks for representation learning. The field takes inspiration from biological neuroscience and is centered around stacking artificial neurons into layers and “training” them to process data. The adjective “deep” refers to the use of multiple layers (ranging from three to several hundred or thousands) in the network. Methods used can be either supervised, semi-supervised or unsupervised.
We can see that them does refer to artifical neurons. The response from the maverick model includes the exact position of the reference and referents. With this it should be easy to replace referents with what they refer to.
Let’s try our model out on all of the sentences of the paragraph, with resolved references.
from textwrap import wrapresolved_paragraph = resolve_coreferences(paragraph)examples = to_examples(example_df.iloc[0])for sentence in sent_tokenize(resolved_paragraph): output = generate_continuation( model=model, tokenizer=tokenizer, prompt=f"{few_shot_task}\n\n{examples}\n\nSentence:\n{sentence}\n\nFacts:\n", stopping="Sentence:\n", )print("Sentence provided to model:")print("\n".join(wrap(sentence)))print()print("Atomic facts extracted by model:")print(output)print()
Sentence provided to model:
Deep learning is a subset of machine learning methods that utilize
neural networks for representation learning.
Atomic facts extracted by model:
- Deep learning is a subset of machine learning methods.
- Deep learning utilizes neural networks.
- Deep learning utilizes neural networks for representation learning.
Sentence provided to model:
Deep learning takes inspiration from biological neuroscience and is
centered around stacking artificial neurons into layers and "training"
artificial neurons to process data.
Atomic facts extracted by model:
- Deep learning takes inspiration from biological neuroscience.
- Deep learning is centered around stacking artificial neurons into layers.
- Artificial neurons are stacked into layers.
- Artificial neurons are trained to process data.
- Data is processed by artificial neurons.
Sentence provided to model:
The adjective "deep" refers to the use of multiple layers (ranging
from three to several hundred or thousands) in the network.
Atomic facts extracted by model:
- The adjective "deep" refers to the use of multiple layers.
- The adjective "deep" refers to the use of multiple layers ranging from three to several hundred or thousands.
- The adjective "deep" refers to the use of multiple layers in the network.
Sentence provided to model:
Methods used can be either supervised, semi-supervised or
unsupervised.
Atomic facts extracted by model:
- Methods used can be either supervised.
- Methods used can be either semi-supervised.
- Methods used can be either unsupervised.
- Methods used are supervised, semi-supervised or unsupervised.
This looks great to me. It’s late now, I need to sleep.
The next thing will be to extract the relationships between the subjects of each fact. With that I can then form these facts into a knowledge graph. A knowledge graph can be queried to produce the data that the model requires, instead of relying on what we have already written.
Relationships
What I want to do with these facts is to turn them into things and relationships between those things. This is the construction of a knowledge graph, a topic which is distinctly part of “good old fashioned ai” as it relates directly to symbolic reasoning. As such reviewing works from that time will be helpful.
I’ve found a copy of Artificial Intelligence (Rich, Knight, and Nair 2009) which has multiple chapters on knowledge representation. It includes the following passage which still feels like a problem today:
Rich, Elane, Kevin Knight, and Shivashankar B. Nair. 2009. Artificial Intelligence (Third Edition). Tata McGraw-Hill.
One representation of facts is so common that it deserves special mention: natural language sentences. Regardless of the representation for facts that we use in a program, we may also need to be concerned with an English representation of those facts in order to facilitate getting information into and out of the system. In this case, we must also have mapping functions from English sentences to the representation we are actually going to use and from it back to sentences.
This is precisely the system that I am trying to build!
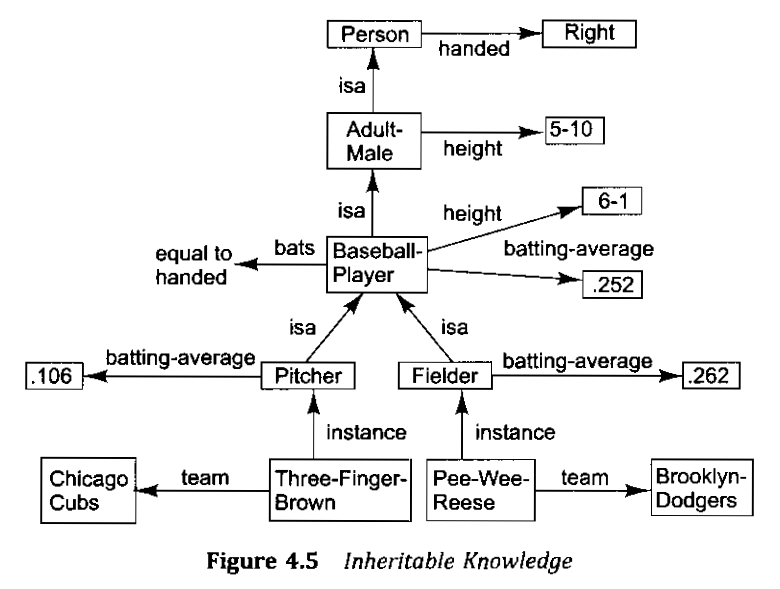
The book has many examples of different knowledge graphs that can be formed, for example:
inheritable knowledge graph
There are several problems with this specific graph (e.g. not all adult males are right handed) however we can still use this structure to represent the knowledge that we extract from the sentences. The facts about each thing (e.g. batting-average), which form the horizontal lines, seem unbounded in kind. The actual inheritance (e.g isa) appear to split into instance (of) and is a.
If I can get the model to produce only these inheritance relationships then that will be a great start. To do this we must first think of what the correct structure would look like for the deep learning paragraph that we have been working with:
Deep learning is a subset of machine learning methods that utilize neural networks for representation learning. The field takes inspiration from biological neuroscience and is centered around stacking artificial neurons into layers and “training” them to process data. The adjective “deep” refers to the use of multiple layers (ranging from three to several hundred or thousands) in the network. Methods used can be either supervised, semi-supervised or unsupervised.
I would suggest that the inheritance relationship would be:
You might have opinions about this, such as the relationship of the methods to deep learning, or the absence of the biological inspiration. It is still a structure that could be reasonably inferred from the paragraph. To start with we can see how the model performs in a zero shot setting with a single chosen fact.
inheritance_task ="""Instructions:1. You are given an atomic fact. Your task is to find all is-a and \instance-of relationships in the fact.2. An atomic fact is a sentence containing a singular piece of information.3. An atomic fact may have no is-a or instance-of relationships.4. An atomic fact may have a mix of is-a and instance-of relationships.5. An is-a relationship exists between any subset of a set.6. An instance-of relationship exists between any singular instance of a set.7. Only list relationships that are explicitly mentioned in the text.8. You should only output the relationships as a list, with each item starting \with "- ". Do not include other formatting.9. If there are no relationships then only output NONE.10. Use the previous examples to learn how to do this.""".strip()
Code
inheritance_example ="""Fact:The web page announces the launch of iPhone.Relationships:NONEFact:Fruit flies eat fruit.Relationships:NONEFact:iPhone is a device that combines a mobile phone, \an iPod and an Internet communications device.Relationships:- iPhone is-a mobile phone- iPhone is-a iPod- iPhone is-a Internet communications device""".strip()
Code
fact ="Deep learning is a subset of machine learning methods."output = generate_continuation( model=model, tokenizer=tokenizer, prompt=(f"{inheritance_task}\n\n"f"{inheritance_example}\n\n"f"Fact:\n{fact}\n\nRelationships:\n" ), stopping="Fact:\n",)print(output)
- Deep learning is-a machine learning
This is a good positive example. I’ve had to tune the instructions a bit to ensure that it knows what the relationships represent. The next thing to test is a fact that has no is-a or instance-of relationships in it.
Code
fact ="Artificial neurons are stacked into layers."output = generate_continuation( model=model, tokenizer=tokenizer, prompt=(f"{inheritance_task}\n\n"f"{inheritance_example}\n\n"f"Fact:\n{fact}\n\nRelationships:\n" ), stopping="Fact:\n",)print(output)
- Artificial neuron is-a layer
It is very hard to get the model to say that there are no relationships present in the text. I wonder if using the facts as the starting point is the best way to do this. What if we started with the sentences?
inheritance_task ="""Instructions:1. You are given a sentence. Your task is to find all is-a and \instance-of relationships in the sentence.2. An is-a relationship exists between any subset of a set.3. An instance-of relationship exists between any singular instance of a set.4. Only list relationships that are explicitly mentioned in the text.5. You should only output the relationships as a list, with each item starting \with "- ". Do not include other formatting.6. If there are no relationships then only output NONE.""".strip()
Code
inheritance_example ="""Sentence:The web page announces the launch of iPhone.Relationships:NONESentence:Fruit flies eat fruit.Relationships:NONESentence:iPhone is a device that combines a mobile phone, \an iPod and an Internet communications device.Relationships:- iPhone is-a mobile phone- iPhone is-a iPod- iPhone is-a Internet communications device""".strip()
Code
sentence ="""Deep learning is a subset of machine learning methods \that utilize neural networks for representation learning.""".strip()output = generate_continuation( model=model, tokenizer=tokenizer, prompt=(f"{inheritance_task}\n\n"f"{inheritance_example}\n\n"f"Sentence:\n{sentence}\n\nRelationships:\n" ), stopping="Sentence:\n",)print(output)
- Deep learning is-a machine learning
- Deep learning is-a subset of machine learning methods
Code
sentence ="""The field takes inspiration from biological neuroscience \and is centered around stacking artificial neurons into \layers and "training" them to process data.""".strip()output = generate_continuation( model=model, tokenizer=tokenizer, prompt=(f"{inheritance_task}\n\n"f"{inheritance_example}\n\n"f"Sentence:\n{sentence}\n\nRelationships:\n" ), stopping="Sentence:\n",)print(output)
- field is-a biological neuroscience
- field is-a artificial neurons
- field is-a layers
- field is-a data
At this point I feel that the model is listing every relationship that exists in the text. Would it be better to find these relationships first and then classify their kind?
relationship_task ="""Instructions:1. You are given a sentence. Your task is to find all relationships \between terms and concepts in the sentence.2. Only list relationships that are explicitly mentioned in the text.3. You should only output the relationships as a list, with each item starting \with "- ". Do not include other formatting.4. Relationship names should be a single word in the passive tense.5. Relationship terms should be quoted text from the sentence.""".strip()relationship_example ="""Sentence:The web page announces the launch of iPhone.Relationships:- announces("web page", "iPhone")Sentence:Fruit flies eat fruit.Relationships:- eats("fruit flies", "fruit")Sentence:iPhone is a device that combines a mobile phone, \an iPod and an Internet communications device.Relationships:- is("iPhone", "device")- is("iPhone", "mobile phone")- is("iPhone", "iPod")- is("iPhone", "Internet communications device")Sentence:Students go to school to learn from the teacher.Relationships:- at("student", "school")- at("teacher", "school")- teaches("teacher", "students")- involves("students", "learning")""".strip()
Code
sentence ="""Deep learning is a subset of machine learning methods \that utilize neural networks for representation learning.""".strip()output = generate_continuation( model=model, tokenizer=tokenizer, prompt=(f"{relationship_task}\n\n"f"{relationship_example}\n\n"f"Sentence:\n{sentence}\n\nRelationships:\n" ), stopping=["Sentence:\n", "Note:"],)print(output)
sentence ="""The field takes inspiration from biological neuroscience \and is centered around stacking artificial neurons into \layers and "training" them to process data.""".strip()output = generate_continuation( model=model, tokenizer=tokenizer, prompt=(f"{relationship_task}\n\n"f"{relationship_example}\n\n"f"Sentence:\n{sentence}\n\nRelationships:\n" ), stopping=["Sentence:\n", "Note:"],)print(output)
I’m going to try running it on the paragraph after resolving the coreferences.
from textwrap import wrapresolved_paragraph = resolve_coreferences(paragraph)for sentence in sent_tokenize(resolved_paragraph): output = generate_continuation( model=model, tokenizer=tokenizer, prompt=(f"{relationship_task}\n\n"f"{relationship_example}\n\n"f"Sentence:\n{sentence}\n\nRelationships:\n" ), stopping=["Sentence:\n", "Note:"], )print("Sentence provided to model:")print("\n".join(wrap(sentence)))print()print("Relationships extracted by model:")print(output)print()
Sentence provided to model:
Deep learning is a subset of machine learning methods that utilize
neural networks for representation learning.
Relationships extracted by model:
- is("deep learning", "subset")
- is("deep learning", "machine learning")
- utilizes("neural networks", "representation learning")
- utilizes("deep learning", "machine learning methods")
Sentence provided to model:
Deep learning takes inspiration from biological neuroscience and is
centered around stacking artificial neurons into layers and "training"
artificial neurons to process data.
Relationships extracted by model:
- takes("deep learning", "inspiration")
- is("deep learning", "biological neuroscience")
- is("deep learning", "stacking")
- is("deep learning", "training")
- is("deep learning", "artificial neurons")
- is("deep learning", "layers")
- involves("artificial neurons", "processing data")
Sentence provided to model:
The adjective "deep" refers to the use of multiple layers (ranging
from three to several hundred or thousands) in the network.
Relationships extracted by model:
- refers("deep", "use of multiple layers")
- refers("deep", "network")
Sentence provided to model:
Methods used can be either supervised, semi-supervised or
unsupervised.
Relationships extracted by model:
- can be("methods used", "supervised")
- can be("methods used", "semi-supervised")
- can be("methods used", "unsupervised")
Passing the entire unaltered paragraph to the model does allow it to resolve the coreferences itself as well as providing more context. I wonder how well this would work on other texts.
Code
extract_relationships("""It was the best of times, it was the worst of times,it was the age of wisdom, it was the age of foolishness,it was the epoch of belief, it was the epoch of incredulity,it was the season of Light, it was the season of Darkness,it was the spring of hope, it was the winter of despair,we had everything before us, we had nothing before us,we were all going direct to Heaven, we were all going directthe other way—in short, the period was so far like the presentperiod, that some of its noisiest authorities insisted on itsbeing received, for good or for evil, in the superlative degreeof comparison only. """)
[Relationship(kind='is', subject='best of times', target='worst of times'),
Relationship(kind='is', subject='age of wisdom', target='age of foolishness'),
Relationship(kind='is', subject='epoch of belief', target='epoch of incredulity'),
Relationship(kind='is', subject='season of Light', target='season of Darkness'),
Relationship(kind='is', subject='spring of hope', target='winter of despair'),
Relationship(kind='is', subject='present period', target='period'),
Relationship(kind='involves', subject='noisiest authorities', target='receiving'),
Relationship(kind='involves', subject='noisiest authorities', target='comparing'),
Relationship(kind='involves', subject='noisiest authorities', target='receiving in superlative degree'),
Relationship(kind='involves', subject='noisiest authorities', target='for good or for evil'),
Relationship(kind='involves', subject='noisiest authorities', target='in superlative degree')]
This model can still get stuck in a loop. Taking a paragraph a little further on…
Code
extract_relationships("""It was the year of Our Lord one thousand seven hundred andseventy-five. Spiritual revelations were conceded to Englandat that favoured period, as at this. Mrs. Southcott hadrecently attained her five-and-twentieth blessed birthday,of whom a prophetic private in the Life Guards had heraldedthe sublime appearance by announcing that arrangements weremade for the swallowing up of London and Westminster. Eventhe Cock-lane ghost had been laid only a round dozen of years,after rapping out its messages, as the spirits of this veryyear last past (supernaturally deficient in originality) rappedout theirs. Mere messages in the earthly order of events hadlately come to the English Crown and People, from a congress ofBritish subjects in America: which, strange to relate, have provedmore important to the human race than any communications yetreceived through any of the chickens of the Cock-lane brood. """, max_new_tokens=250)
It is possible to visualize the relationships that have been produced however this is just showing how poor the extraction is. These do not form a satisfying graph, the model has done a very poor job of relating them to each other.
relationship_task ="""Instructions:1. You are given a passage of text. Your task is to find all \relationships between terms and concepts.2. Only list relationships that are explicitly mentioned in the text.3. You should only output the relationships as a list, with each item starting \with "- ". Do not include other formatting.4. The Relationship is made of the connecting name and the two terms.5. Names should be a single word in the passive tense. \Names should be verbs or attributes.6. Terms should be a consistent word or words to refer \to a single noun in the text. Terms are not verbs.""".strip()relationship_example ="""Text:The web page announces the launch of iPhone. \This phone will be able to browse the internet.Relationships:- announces("web page", "iPhone")- is("iPhone", "phone")- has("iPhone", "browser")Text:Fruit flies eat fruit.Relationships:- eats("fruit flies", "fruit")Text:iPhone is a device that combines a mobile phone, \an iPod and an Internet communications device.Relationships:- is("iPhone", "device")- is("iPhone", "mobile phone")- is("iPhone", "iPod")- is("iPhone", "Internet communications device")Text:Students go to school to learn from the teacher.Relationships:- at("student", "school")- at("teacher", "school")- teaches("teacher", "students")- involves("students", "learning")""".strip()
By working on the prompt a far more satisfactory graph can be produced. There are still nodes which are low value (subset, stacking…) however the graph is far more connected.
Code
text ="""Deep learning is a subset of machine learning that \focuses on utilizing neural networks to perform tasks \such as classification, regression, and representation \learning. The field takes inspiration from biological \neuroscience and is centered around stacking artificial \neurons into layers and "training" them to process data. \The adjective "deep" refers to the use of multiple layers \(ranging from three to several hundred or thousands) in \the network. Methods used can be either supervised, \semi-supervised or unsupervised.Some common deep learning network architectures \include fully connected networks, deep belief networks, \recurrent neural networks, convolutional neural networks, \generative adversarial networks, transformers, and neural \radiance fields. These architectures have been applied to \fields including computer vision, speech recognition, \natural language processing, machine translation, \bioinformatics, drug design, medical image analysis, \climate science, material inspection and board game \programs, where they have produced results comparable \to and in some cases surpassing human expert performance.Early forms of neural networks were inspired by \information processing and distributed communication \nodes in biological systems, particularly the human \brain. However, current neural networks do not intend \to model the brain function of organisms, and are \generally seen as low-quality models for that purpose.""".strip()relationships = []for paragraph in text.splitlines(): paragraph = paragraph.strip()ifnot paragraph:continue relationships.extend(extract_relationships(paragraph))to_graph(relationships)
While it is fun to produce this graph out of the first three paragraphs, it still has large areas that are low quality. I wonder if using a better model would help.
Claude
I’ve signed up to claude and I have access to the console. I can use this to submit these requests to the sonnet model to provide a point of comparison.
I’ve made a crappy wrapper around the anthropic api which allows me to easily submit messages and see the response. Let’s try using our existing prompt and the first paragraph of the deep learning wikipedia page.
from dataclasses import dataclassrelationship_task ="""Instructions:1. You are given a passage of text. Your task is to find all \relationships between terms and concepts.2. Only list relationships that are explicitly mentioned in the text.3. You should only output the relationships as a list, with each item starting \with "- ". Do not include other formatting.4. The Relationship is made of the connecting name and the two terms.5. Names should be a single word in the passive tense. \Names should be verbs or attributes.6. Terms should be a consistent word or words to refer \to a single noun in the text. Terms are not verbs.""".strip()@dataclassclass RelationshipExample: text: str relationships: list[Relationship]@propertydef relationships_str(self) ->str:return"\n".join(map(str, self.relationships))relationship_examples = [ RelationshipExample( text=("The web page announces the launch of iPhone. ""This phone will be able to browse the internet." ), relationships=[ Relationship(kind="announces", subject="web page", target="iPhone"), Relationship(kind="is", subject="iPhone", target="phone"), Relationship(kind="has", subject="iPhone", target="browser"), ] ), RelationshipExample( text=("Fruit flies eat fruit." ), relationships=[ Relationship(kind="eats", subject="fruit flies", target="fruit"), ] ), RelationshipExample( text=("iPhone is a device that combines a mobile phone, ""an iPod and an Internet communications device." ), relationships=[ Relationship(kind="is", subject="iPhone", target="device"), Relationship(kind="is", subject="iPhone", target="mobile phone"), Relationship(kind="is", subject="iPhone", target="iPod"), Relationship(kind="is", subject="iPhone", target="Internet communications device"), ] ), RelationshipExample( text=("Students go to school to learn from the teacher." ), relationships=[ Relationship(kind="at", subject="student", target="school"), Relationship(kind="at", subject="teacher", target="school"), Relationship(kind="teaches", subject="teacher", target="students"), Relationship(kind="involves", subject="students", target="learning"), ] ),]relationship_chat = AnthropicChat.system(relationship_task)for example in relationship_examples: relationship_chat = relationship_chat.user(example.text) relationship_chat = relationship_chat.assistant(example.relationships_str)
Code
client = AnthropicClient.load("home")
paragraph ="""Deep learning is a subset of machine learning methods that utilize neural networksfor representation learning. The field takes inspiration from biological neuroscienceand is centered around stacking artificial neurons into layers and "training" them toprocess data. The adjective "deep" refers to the use of multiple layers (ranging fromthree to several hundred or thousands) in the network. Methods used can be eithersupervised, semi-supervised or unsupervised."""paragraph = paragraph.strip().replace("\n", " ")relationship_response = client.complete( relationship_chat.user(paragraph), max_tokens=1_000, temperature=0.)print(f"processing the paragraph cost {relationship_response.pretty_cost}")print()print("the extracted relationships are:")print(relationship_response.content)to_graph(to_relationships(relationship_response.content))
This is a dramatically better graph. My one complaint would be the has multiple layers relationship. Even so this is wonderful.
How does this compare on the first three paragraphs?
text ="""Deep learning is a subset of machine learning that \focuses on utilizing neural networks to perform tasks \such as classification, regression, and representation \learning. The field takes inspiration from biological \neuroscience and is centered around stacking artificial \neurons into layers and "training" them to process data. \The adjective "deep" refers to the use of multiple layers \(ranging from three to several hundred or thousands) in \the network. Methods used can be either supervised, \semi-supervised or unsupervised.Some common deep learning network architectures \include fully connected networks, deep belief networks, \recurrent neural networks, convolutional neural networks, \generative adversarial networks, transformers, and neural \radiance fields. These architectures have been applied to \fields including computer vision, speech recognition, \natural language processing, machine translation, \bioinformatics, drug design, medical image analysis, \climate science, material inspection and board game \programs, where they have produced results comparable \to and in some cases surpassing human expert performance.Early forms of neural networks were inspired by \information processing and distributed communication \nodes in biological systems, particularly the human \brain. However, current neural networks do not intend \to model the brain function of organisms, and are \generally seen as low-quality models for that purpose.""".strip()responses = []relationships = []for paragraph in text.splitlines(): paragraph = paragraph.strip()ifnot paragraph:continue relationship_response = client.complete( relationship_chat.user(paragraph), max_tokens=1_000, temperature=0.0, ) responses.append(relationship_response)print(f"paragraph cost {relationship_response.pretty_cost}") relationships.extend(to_relationships(relationship_response.content))to_graph(relationships)
Chunking the input certainly leads to better results. The work here is still good but the relationship kinds are worse (frequently they are two words) and there is a lot of detail missing.
Still, claude sonnet really seems excellent.
Conclusion
The aim of this all was to produce a knowledge graph that could be used to synthesize documents for a RAG system. I have managed to produce graphs that capture some of the knowledge within the source documents. This process does lose information though and the recombination process has not been started.
This is a very long post already so the work on that will have to continue. Some solid progress has been made.