
The aim here will be to create definitions of each wikipedia article that can be used to determine if a word could refer to that article. Each article will be defined by the model output for sentences that refer to it, which is a vector of probabilities. This means that the definition of a wikipedia article will be some measure over this vector space.
Creating definitions of these articles was investigated in the synonym clustering evaluation. I want to use the weighted distance approach, as it performed well. The weights of each dimension should be tuned so that there is a unit distance boundary.
Given this it should then be possible to take the output of the model and find the articles that it could refer to. There could be many different articles that match the model output, so the final step is to use the words that appear in the text to resolve the exact article.
All of this will be done on wikipedia data, which is a problem as that is evaluating on the train set. The difference between the evaluation and the cluster definition is that the title of the wikipedia page is used to form the cluster, while the evaluation is against the synonym as it appears in the text.
Wikipedia Article Definitions
As before I am using the data that was processed earlier.
This involved taking the sentences from wikipedia and, for each link in the sentence, resolving the meaning of the link using the teacher model (the XLM-RoBERTa (Conneau et al. 2019) model with a word specific prompt). When prompting the model, the mask token output is captured, and it provides a value per token recognized by the model. The output is what the model thinks would be a suitable substitution for the mask token. Prompting the model is used to make this output a suitable description of the word.
Conneau, Alexis, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2019. “Unsupervised Cross-Lingual Representation Learning at Scale.” arXiv. https://doi.org/10.48550/ARXIV.1911.02116.
Article Reference Description
This process has been run over approximately 2% of English Wikipedia.
The model produces around 250,000 floating point values per input. As wikipedia has a large number of links in it the required disk space of this builds up very quickly.
Well trained language models are confident in their predictions, so the outputs are not normally distributed. Instead a small number of the tokens have outputs that are much higher than the others. This means that taking the top tokens captures the majority of the information in the output.
So the model output is truncated to the top 100 tokens, and softmax is applied to them. Every missing token is assumed to have a probability of zero:
Article Cluster Description
In the previous posts the model output has varied across sentences even when describing the same wikipedia article. This is to be expected. When creating the definition over the token space for an article we must measure the variance in these outputs.
Not all of the outputs are equally valid. Most of the outputs form a group while there are some outliers. To make the measurement of the article decisive I have used DBSCAN (Ester et al. 1996) to identify the core outputs that form a cluster describing the article. The measurement of the article is then based on this.
Ester, Martin, Hans-Peter Kriegel, Jörg Sander, and Xiaowei Xu. 1996. “A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise.” In, 226–31. AAAI Press.
The final concern is that the model can describe the article in different ways. These description differences can be great enough that there are tokens used to describe \(link_a\) which are not used to describe \(link_b\). Consequently the description of the article cluster will be based on tokens which have varying support. To ensure that only significant tokens are included a threshold will be applied, and the included tokens must occur in some appropriate fraction of all descriptions of the article.
Article Cluster Description Problems
The primary difference is that the prompted teacher works with the title of the Wikipedia article. If the title of the wikipedia article was available for prompting then there would be no ambiguity to resolve. So we must try this with just the word as it appears in the text.
The second difference from the previous work I have done on this is that the cluster definition will be used to match the full output of the model. This means that all of the tokens will have a non zero output. I am hopeful that the process of approximation that was performed to save the Wikipedia output was close enough to the real model output that it will not be a problem.
Both of these could cause problems, and by inspecting the relationship between the model output and the article cluster I am hopeful that a consistent way to define a cluster can be found.
Generating Article Cluster Descriptions
This is going to reuse the code from the previous post quite heavily. The aim will be to describe much more of the articles than before and then try to come up with an effective way to match points to articles.
At this point we will just be using the points from different articles, so this really is testing on the train set.
Code
# from src/main/python/blog/prompt_internalization/clustering/expand.py
import numpy as np
import pandas as pd
def expand(
probabilities: np.ndarray, indices: np.ndarray, size: int = 250_002
) -> np.ndarray:
"""Expand the indicies and probabilities for a single row to the full 250k tokens"""
result = np.zeros(shape=size)
result[indices] = probabilities
return result
def expand_all(
probabilities: np.ndarray, indices: np.ndarray, size: int = 250_002
) -> np.ndarray:
"""Expand the indicies and probabilities for several rows to the full 250k tokens"""
rows = probabilities.shape[0]
result = np.zeros(shape=(rows, size))
result.flat[indices + (size * np.arange(rows)[:, None])] = probabilities
return result
def expand_compact(df: pd.DataFrame) -> (np.ndarray, np.ndarray):
"""Expand the indicies and probabilities for several rows to the minimum number of tokens.
Returns the indices used so the process can be repeated."""
unique_tokens = np.sort(df["index"].explode().unique())
token_map = {token_index: index for index, token_index in enumerate(unique_tokens)}
rows = len(df)
token_count = len(unique_tokens)
def map_tokens(tokens: list[int]) -> list[int]:
return list(map(token_map.get, tokens))
token_index = np.array(df["index"].apply(map_tokens).tolist())
probability = np.zeros((rows, token_count))
probability.flat[token_index + (token_count * np.arange(rows)[:, None])] = np.array(
df.probability.tolist()
)
return (probability, unique_tokens)
def expand_match(
probability: np.ndarray, probability_indices: np.ndarray, target_indices: np.ndarray
) -> np.ndarray:
"""Expand the indexed probability matrix to match the target indices.
Missing values are filled with zero."""
rows = probability.shape[0]
columns = target_indices.shape[0]
result = np.zeros(shape=(rows, columns))
# the indices of values in probability that are in target
p_indices = np.where(np.in1d(probability_indices, target_indices))[0]
# the indices of values in target that are in probability
t_indices = np.where(np.in1d(target_indices, probability_indices))[0]
# a = np.array([1, 3, 5, 7, 9])
# b = np.array([3, 4, 5, 6, 7])
# np.where(np.in1d(a, b))[0]
# >> array([1, 2, 3])
# this is the array of values in a that are also present in b:
# a[[1, 2, 3]]
# >> array([3, 5, 7])
result[:, t_indices] = probability[:, p_indices]
return result
# from src/main/python/blog/prompt_internalization/clustering/dbscan.py
import numpy as np
import pandas as pd
from sklearn.cluster import DBSCAN
from sklearn.neighbors import NearestNeighbors
class DBSCANFilter:
"""
This filters the points to those that would be considered part of the majority DBSCAN cluster.
"""
def __init__(self, min_samples_ratio: float) -> None:
self.min_samples_ratio = min_samples_ratio
self.dbscan = None
self.label = None
def fit_transform(self, probability: np.ndarray) -> np.ndarray:
self.fit(probability)
mask = self.transform(probability)
return probability[mask]
def fit(self, probability: np.ndarray) -> None:
min_samples = max(1, int(probability.shape[0] * self.min_samples_ratio))
neighbors = NearestNeighbors(n_neighbors=min_samples)
neighbors.fit(probability)
neighbor_distance, _ = neighbors.kneighbors(
X=probability, n_neighbors=min_samples
)
# 75% quantile distance that encompasses all min_samples points
median_eps = np.quantile(neighbor_distance[:, -1], 0.75)
self.dbscan = DBSCAN(eps=median_eps, min_samples=min_samples)
self.dbscan.fit(probability)
labels = pd.Series(self.dbscan.labels_)
labels = labels[labels != -1]
self.label = labels.value_counts().index[0]
def transform(self, points: np.ndarray) -> np.ndarray:
assert self.dbscan is not None, "call fit first"
point_count = points.shape[0]
result = np.ones(shape=point_count, dtype=int) * -1
for i in range(point_count):
difference = self.dbscan.components_ - points[i, :]
distance = np.linalg.norm(difference, axis=1)
closest_idx = np.argmin(distance)
if distance[closest_idx] < self.dbscan.eps:
result[i] = self.dbscan.labels_[
self.dbscan.core_sample_indices_[closest_idx]
]
return result == self.label
# from src/main/python/blog/prompt_internalization/clustering/measure.py
from __future__ import annotations
from dataclasses import dataclass
from typing import Optional
import numpy as np
from scipy.spatial.distance import cosine, euclidean
from scipy.stats import norm
@dataclass
class ArticleDescription:
label: str
indices: np.ndarray
mean: np.ndarray
std: np.ndarray
@staticmethod
def make(
label: str,
probability: np.ndarray,
indices: Optional[np.ndarray],
minimum_count: int = 5,
) -> ArticleDescription:
if indices is None:
indices = np.arange(probability.shape[1])
# drop any columns which do not have at least minimum_count values
mask = (~np.isnan(probability)).sum(axis=0) >= minimum_count
indices = indices[mask]
probability = probability[:, mask]
probability = np.nan_to_num(probability, nan=0.0)
mean = np.mean(probability, axis=0)
std = np.std(probability, axis=0)
std[std == 0] = std[std != 0].min()
return ArticleDescription(
label=label, indices=indices.astype(int), mean=mean, std=std
)
def describe(self, point: np.ndarray) -> dict[str, float]:
return {
"cosine_unweighted": self.cosine_similarity(point),
"cosine_weighted": self.cosine_similarity(point, weight=True),
"distance_unweighted": self.distance(point),
"distance_weighted": self.distance(point, weight=True),
"dot_unweighted": self.dot(point),
"dot_weighted": self.dot(point, weight=True),
"log_p_mean": self.log_p(point).mean(),
"log_p_min": self.log_p(point).min(),
}
def cosine_similarity(self, point: np.ndarray, weight: bool = False) -> float:
"""Calculates the dot product between the point and the mean.
This returns 0. for identical direction, 1 for orthogonal and 2 for opposite."""
return np.array(
[
cosine(row, self.mean, w=1 / self.std if weight else None)
for row in point
]
)
def distance(self, point: np.ndarray, weight: bool = False) -> float:
"""Calculates the euclidean distance between
the point and the cluster centroid."""
return np.array(
[
euclidean(row, self.mean, w=1 / self.std if weight else None)
for row in point
]
)
def dot(self, point: np.ndarray, weight: bool = False) -> float:
"""Calculates the dot product between the point and the mean."""
if not weight:
return np.dot(point, self.mean)
return np.sum(np.multiply(point, self.mean) / self.std)
def log_p(self, point: np.ndarray, permutation: float = 0.01) -> float:
"""Calculates the log probability of
this feature describing the provided point.
The point values are assumed to come straight
from the model without softmax being applied."""
left_cdf = norm.cdf(
point - permutation,
loc=self.mean,
scale=self.std,
)
right_cdf = norm.cdf(
point + permutation,
loc=self.mean,
scale=self.std,
)
local_probability = right_cdf - left_cdf
# there can be points where the probability is zero
# because they are that far out of the distribution
local_probability[local_probability <= 0] = 1e-9
return np.log(local_probability)Now that we have the code we can use it to describe the processed wikipedia features.
Code
from pathlib import Path
import pandas as pd
DATA_FOLDER = Path("/data/prompt-internalization/multilingual/wikipedia/enwiki/20220701/")
features_df = pd.concat([
pd.read_parquet(file)
for file in sorted((DATA_FOLDER / "features").glob("*.gz.parquet"))
])
article_counts = features_df.target.value_counts()
article_names = article_counts[article_counts > 100].indexCode
import pandas as pd
def describe(name: str, df: pd.DataFrame) -> ArticleDescription:
probability, indices = expand_compact(df=df[df.target == name].copy())
try:
filtered_probabilities = (
DBSCANFilter(min_samples_ratio=0.1)
.fit_transform(probability)
)
return ArticleDescription.make(
label=name,
probability=filtered_probabilities,
indices=indices,
minimum_count=5,
)
except:
print(f"failed to describe {name}")
return NoneCode
from tqdm.auto import tqdm
articles = [
describe(label, df=features_df)
for label in tqdm(article_names)
]
articles = [
article
for article in articles
if article is not None
]failed to describe $socioeconomicCode
articles_df = pd.DataFrame([
{
"label": article.label,
"indices": article.indices,
"mean": article.mean,
"std": article.std,
}
for article in articles
])
articles_dfarticles_df.to_parquet(DATA_FOLDER / "articles.gz.parquet", compression="gzip")With this it should be possible to measure the distance to other points. They have to be reshaped to match the indicies of the description. Luckily the expand_match function was written just to deal with this.
Code
from typing import Optional
import numpy as np
def evaluate_distance(
article: ArticleDescription,
df: pd.DataFrame,
weight: bool = True,
) -> np.array:
probability, indices = expand_compact(df=df)
distances = distance(
article=article,
probability=probability,
indices=indices,
weight=weight,
)
targets = ", ".join(df.target.unique())
print(f"compare {targets} to {article.label}")
print(
f"mean: {distances.mean():0.3f}, "
f"min: {distances.min():0.3f}, "
f"max: {distances.max():0.3f}, "
f"within unit: {(distances <= 1).sum() / len(distances):0.3f}"
)
def distance(
article: ArticleDescription,
probability: np.array,
indices: Optional[np.array] = None,
weight: bool = True,
) -> np.array:
if (indices is not None):
matched_probability = expand_match(
probability,
probability_indices=indices,
target_indices=article.indices,
)
else:
matched_probability = probability[:, article.indices.astype(int)]
return article.distance(matched_probability, weight=weight)The first thing to check is the distances for a given article against itself, here testing the united states article against the points that make up the cluster:
Code
article = ArticleDescription(**articles_df.iloc[0].to_dict())
evaluate_distance(
article,
df=features_df[features_df.target == article.label],
weight=False,
)compare united states to united states
mean: 0.123, min: 0.012, max: 1.131, within unit: 0.999This looks great.
We need to show that it can distinguish between the article and other articles. To do that we can compare that to the distance to association football:
Code
article = ArticleDescription(**articles_df.iloc[0].to_dict())
evaluate_distance(
article,
df=features_df[features_df.target == "association football"],
weight=False,
)compare association football to united states
mean: 0.714, min: 0.627, max: 0.901, within unit: 1.000This isn’t great, as the association football article is a strong match for the united states article description.
Weighting the different dimensions helped a lot when doing this before. Let’s try running the check of the united states points to the article description:
Code
evaluate_distance(
article,
df=features_df[features_df.target == article.label],
weight=True,
)compare united states to united states
mean: 0.964, min: 0.158, max: 84.763, within unit: 0.832Now the match rate has dropped significantly. I did expect this as the distance weight is based on the standard deviation, which does not capture 100% of the values.
What matters is does this then distinguish between united states and association football? We can run the weighted distance check for the association football points:
Code
evaluate_distance(
article,
df=features_df[features_df.target == "association football"],
weight=True,
)compare association football to united states
mean: 23.734, min: 8.378, max: 110.476, within unit: 0.000This is great. When we previously inspected the article points we found that there was a strong overlap between different countries. It would be good to check that this continues to be the case, as it would suggest that the code is correct (rather than having a bug):
Code
evaluate_distance(
article,
df=features_df[features_df.target == "england"],
weight=True,
)compare england to united states
mean: 0.876, min: 0.365, max: 67.836, within unit: 0.911Here the match for the points in the article itself have now reduced to 0.83 which is quite a large reduction. On the plus side, the association football points are now completely excluded. England being such a strong match is expected as the original evaluation showed that these descriptions do overlap heavily. That is why it is not possible to rely only on the description as the way to determine word sense.
The choice of an appropriate distance seems to be key here. Currently the descriptions use a standard deviation, which could be scaled to produce a unit distance (as by default 1 standard deviation only covers about 68% of the points).
This is a good start and now I want to make this determine the matching articles for the raw output from a model. The first thing to do will be a spot check.
Article Cluster Spot Check
The points that form the cluster have been created by prompting the teacher model with the name of the target article. When resolving the word sense of words in text the target article will not be available. Only the word in the text is available, so that has to be used.
This is a big change. The degree to which it changes the output is as yet unknown.
Code
from transformers import AutoTokenizer, AutoModelForMaskedLM
MODEL_NAME = "xlm-roberta-base"
model = AutoModelForMaskedLM.from_pretrained(MODEL_NAME)
model.eval()
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)Code
import torch
import numpy as np
def get_article(label: str, df: pd.DataFrame) -> ArticleDescription:
row = df[df.label == label].iloc[0]
return ArticleDescription(**row.to_dict())
@torch.inference_mode()
def get_prediction(
text: str,
noun: str,
prompt: str = " Pet: Dog, Color: Yellow, Vehicle: Tractor, Fruit: Banana,<mask>: {}",
) -> np.array:
input_ids = tokenizer(
text.strip() + prompt.format(noun),
return_tensors="pt",
return_attention_mask=False,
).input_ids
output = model(input_ids)
mask_index = input_ids == tokenizer.mask_token_id
predictions = output.logits[mask_index][0]
# should this limit to top 100 tokens first?
predictions = predictions.softmax(-1)
return predictions.cpu().numpy()
def get_prediction_distance(
text: str,
noun: str,
article: ArticleDescription,
weight: bool,
) -> float:
prediction = get_prediction(text, noun)
value = distance(
article,
probability=prediction[None, :],
weight=weight,
)[0]
is_weighted = 'weighted' if weight else 'unweighted'
print(f"The {is_weighted} distance of {noun} in '{text}' to {article.label} is {value:0.3f}")Code
get_prediction_distance(
text="I love NY",
noun="NY",
article=get_article("new york city", df=articles_df),
weight=False,
)The unweighted distance of NY in 'I love NY' to new york city is 0.712The unweighted distance matches almost anything. We need to weight it.
Code
get_prediction_distance(
text="I love NY",
noun="NY",
article=get_article("new york city", df=articles_df),
weight=True,
)The weighted distance of NY in 'I love NY' to new york city is 2.786Is that good or bad? I wanted to use the unit distance as the threshold. That means we have a problem.

The distance for this classic phrase is much higher than I expected. This is a very short phrase though, and so it doesn’t provide much context.
Code
get_prediction_distance(
text="I like to shop at target.",
noun="Target",
article=get_article("target corporation", df=articles_df),
weight=True,
)The weighted distance of Target in 'I like to shop at target.' to target corporation is 2.793Code
get_prediction_distance(
text="I achieved my performance target this week.",
noun="Target",
article=get_article("target corporation", df=articles_df),
weight=True,
)The weighted distance of Target in 'I achieved my performance target this week.' to target corporation is 6.568This at least matches more strongly to shopping than the performance. I think that there is a boundary that can be established, remembering that this is not the only way we will determine word sense.
That means the next task is to estimate this boundary over a larger dataset. I have the wikipedia text which is already annotated with the correct target article through the links.
Word Sense Induction by Article
The aim here will be to measure the distance between links and the correct target article. Once that has been done the recall / precision curve can be determined to find a good distance to use as the threshold.
Obviously as the distance increases there is a greater chance of other articles being considered valid. The second stage of this will be to find the number of articles that consider the output a member of the article. Can do this as some sort of top N metric.
Finally making this efficient will matter. The dataset I have has only a tiny percentage of wikipedia in it. There are about four thousand articles in my current dataset while English Wikipedia has more like six million. To efficiently measure distance to these in reasonable time will require some work.
Code
# from src/main/python/blog/prompt_internalization/wikipedia/articles.py
import bz2
from dataclasses import dataclass
from pathlib import Path
from typing import Iterator, Optional
from lxml.etree import Element, iterparse
MEDIAWIKI_NAMESPACE = "http://www.mediawiki.org/xml/export-0.10/"
@dataclass
class Article:
title: str
body: str
def read_articles(file: Path) -> Iterator[Article]:
for page in read_pages(file):
try:
article = _get_article(page)
if article:
yield article
except Exception as exception: # pylint: disable=broad-except
print(exception)
def _get_article(element: Element) -> Optional[Article]:
namespace = _get("mw:ns", element)
if namespace is None or namespace.text != "0":
return None
redirect = _get("mw:redirect", element)
if redirect is not None:
return None
text_element = _get("mw:revision/mw:text", element)
if text_element is None:
return None
title_element = _get("mw:title", element)
if title_element is None:
return None
return Article(title=title_element.text, body=text_element.text)
def _get(path: str, element: Element) -> Optional[Element]:
elements = element.xpath(path, namespaces={"mw": MEDIAWIKI_NAMESPACE})
if elements:
return elements[0]
return None
def read_pages(file: Path) -> Iterator[Element]:
with bz2.BZ2File(file, "rb") as handle:
for _event, element in iterparse(
handle, tag=f"{{{MEDIAWIKI_NAMESPACE}}}page", events=("end",)
):
yield element
_clear_memory(element)
def _clear_memory(element: Element) -> None:
element.clear()
for ancestor in element.xpath("ancestor-or-self::*"):
while ancestor.getprevious() is not None:
del ancestor.getparent()[0]
# from src/main/python/blog/prompt_internalization/wikipedia/clean.py
from __future__ import annotations
import regex as re
import wikitextparser
TABLE_PATTERN = re.compile(
r"(?:{{[^}]*}})|(?:{\|[^}]*(?<=\|)})",
flags=re.MULTILINE,
)
URL_PATTERN = re.compile(
r"http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+"
)
TITLE_PATTERN = re.compile(r"^\s*==+[^=]*?==+\s*$", flags=re.MULTILINE)
LEADING_COLON_OR_HASH = re.compile(r"^[:#]", flags=re.MULTILINE)
HTML_TAG = re.compile(r"<[^>]+>")
MANY_BLANK_LINES = re.compile(r"(\n\s*)+\n+")
MANY_SPACES = re.compile(r" +")
MARKUP = re.compile(r"[']+")
LIST_ITEM = re.compile(r"^\s*\*.*$", re.MULTILINE)
LINK_ONLY_LINE = re.compile(r"^[^a-zA-Z]*(?:\[\[[^]]*\]\][^a-zA-Z]*)+$", re.MULTILINE)
def clean_wikitext(text: str) -> str:
text = wikitextparser.parse(text).plain_text(replace_wikilinks=False)
for pattern in [
TABLE_PATTERN,
URL_PATTERN,
TITLE_PATTERN,
LEADING_COLON_OR_HASH,
HTML_TAG,
MARKUP,
LIST_ITEM,
LINK_ONLY_LINE,
MANY_BLANK_LINES,
MANY_SPACES,
]:
text = pattern.sub(" ", text)
return text.strip()
# from src/main/python/blog/prompt_internalization/wikipedia/links.py
from __future__ import annotations
from dataclasses import dataclass
from typing import List, Optional, Tuple
import regex as re
import wikitextparser
from transformers import AutoTokenizer
from transformers.tokenization_utils_base import BatchEncoding
SENTENCE_SEPARATOR = re.compile(r"(?<=[.!?])")
@dataclass
class Link:
text: str
target: str
tokens: BatchEncoding
class FeatureTokenizer:
def __init__(
self,
model_name: str,
prompt: str = " Pet: Dog, Color: Yellow, Vehicle: Tractor, Fruit: Banana,<mask>: {}",
minimum_tokens: int = 25,
) -> None:
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.prompt = prompt
# approximate length, the {} will be replaced with the word or words which alters length.
prompt_length = len(
self.tokenizer(prompt, return_attention_mask=False).input_ids
)
self.minimum_tokens = minimum_tokens + prompt_length
@property
def mask_token_id(self) -> int:
return self.tokenizer.mask_token_id
def get_links(self, text: str) -> List[Link]:
links = [
self.encode(text=text, link=link)
for line in self._lines(text)
for text, link in self._text_and_links(line)
if ":" not in link.target
]
return [link for link in links if link]
def encode(self, text: str, link: wikitextparser.WikiLink) -> Optional[Link]:
target = link.target
word = link.text or link.target
capitalized = word[0].upper() + word[1:]
prompted = text.strip() + self.prompt.format(capitalized)
tokens = self.tokenizer(
prompted,
return_attention_mask=False,
).input_ids
token_count = len(tokens)
if token_count > self.tokenizer.model_max_length:
return None
if token_count < self.minimum_tokens:
return None
return Link(text=text, target=target, tokens=tokens)
@staticmethod
def _lines(text: str) -> List[str]:
return [sentence.strip() for sentence in SENTENCE_SEPARATOR.split(text)]
@staticmethod
def _text_and_links(line: str) -> Tuple[str, wikitextparser.WikiLink]:
parsed = wikitextparser.parse(line)
text = parsed.plain_text()
return [(text, link) for link in parsed.wikilinks]Code
from pathlib import Path
import pandas as pd
WIKIPEDIA_ARTICLES_FOLDER = Path("/data/wikipedia/external/enwiki/20220701/")
WIKIPEDIA_ARTICLES = sorted(WIKIPEDIA_ARTICLES_FOLDER.glob("*.bz2"))Code
from typing import List
from dataclasses import asdict
import pandas as pd
from tqdm.auto import tqdm
MODEL_NAME = "xlm-roberta-base"
def make_dataset(articles: List[Path], targets: List[str], count: int = 10_000) -> pd.DataFrame:
targets = set(targets)
tokenizer = FeatureTokenizer(model_name=MODEL_NAME)
links = (
link
for file in articles
for article in read_articles(file)
for link in tokenizer.get_links(clean_wikitext(article.body))
if link.target.casefold().strip() in targets
)
return pd.DataFrame([
asdict(link)
for _, link in zip(tqdm(range(count)), links)
])Code
dataset = make_dataset(WIKIPEDIA_ARTICLES[::-1], targets=article_names)
dataset.to_parquet(DATA_FOLDER / "test.gz.parquet", compression="gzip")Token indices sequence length is longer than the specified maximum sequence length for this model (790 > 512). Running this sequence through the model will result in indexing errorsCode
dataset.target.value_counts()Real Madrid CF 194
Pyrénées-Atlantiques 112
FC Bayern Munich 110
FC Barcelona 110
Communes of France 106
...
Hamilton Tiger-Cats 1
Calgary Stampeders 1
Vogue (magazine) 1
Jack Nicholson 1
minor ice hockey 1
Name: target, Length: 2975, dtype: int64Code
from transformers import AutoModelForMaskedLM
import numpy as np
MODEL_NAME = "xlm-roberta-base"
class Model:
def __init__(self, model_name: str, mask_token_id: int) -> None:
self.model = AutoModelForMaskedLM.from_pretrained(model_name)
self.model.eval()
self.model.cuda()
self.mask_token_id = mask_token_id
@torch.inference_mode()
def infer(self, tokens: List[int]) -> np.array:
input_ids = torch.tensor(
tokens,
dtype=torch.long,
device=self.model.device,
)[None, :]
output = self.model(input_ids)
mask_index = input_ids == tokenizer.mask_token_id
predictions = output.logits[mask_index][0]
# should this limit to top 100 tokens first?
predictions = predictions.softmax(-1)
return predictions.cpu().numpy()
def distance(
self,
tokens: List[int],
article: ArticleDescription,
weight: bool,
) -> float:
prediction = self.infer(tokens)
return distance(
article,
probability=prediction[None, :],
weight=weight,
)[0]Code
model = Model(model_name=MODEL_NAME, mask_token_id=tokenizer.mask_token_id)Code
row = dataset.iloc[0]
model.distance(
tokens=row.tokens,
article=get_article(
row.target.casefold().strip(),
df=articles_df
),
weight=True
)0.48049835285052855Code
from collections import defaultdict
from typing import Dict
import pandas as pd
from tqdm.auto import tqdm
def get_target_distances(model: Model, article_df: pd.DataFrame, test_df: pd.DataFrame) -> Dict[str, np.array]:
targets = [
target.casefold().strip()
for target in sorted(test_df.target.unique())
]
articles = {
target: get_article(target, df=article_df)
for target in targets
}
result = defaultdict(list)
for row in tqdm(test_df.iloc, total=len(test_df)):
target = row.target.casefold().strip()
result[target].append(
model.distance(
tokens=row.tokens,
article=articles[target],
weight=True,
)
)
return {
target: np.array(distances)
for target, distances in result.items()
}Code
test_distances = get_target_distances(
model=model,
article_df=articles_df,
test_df=dataset,
)Code
test_distances_df = pd.DataFrame(
test_distances.items(),
columns=["target", "distances"]
)
(
test_distances_df
.distances
.explode()
.sort_values()
.reset_index(drop=True)
.plot(logy=True)
)
test_distances_description = (
test_distances_df
.distances
.explode()
.astype(float)
.describe()
)
test_distances_descriptioncount 10000.000000
mean 1.962475
std 10.603511
min 0.124409
25% 0.677459
50% 0.976587
75% 1.591136
max 828.763570
Name: distances, dtype: float64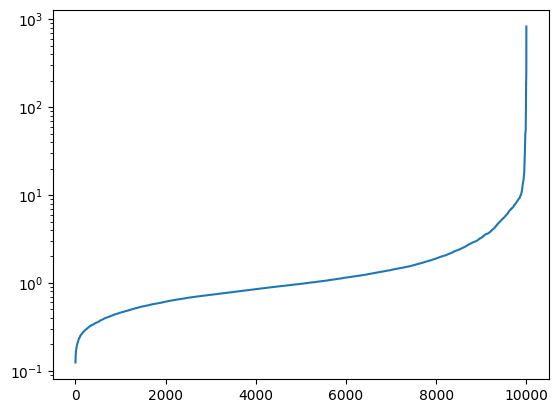
It looks like a distance of ~1.6 would capture 75% of the articles that have just been processed. There are some very strong outliers in this. Overall this is encouraging as it shows that the distance appears to be quite close.
The thing to do would be to find out how this distribution varies for the other articles.
Code
from collections import defaultdict
from typing import Dict
import pandas as pd
from tqdm.auto import tqdm
def get_inverse_distances(model: Model, article_df: pd.DataFrame, test_df: pd.DataFrame) -> Dict[str, np.array]:
articles = [
ArticleDescription(**row.to_dict())
for row in article_df.iloc
]
def distances(target: str, tokens: List[int]) -> List[float]:
prediction = model.infer(tokens)
return [
distance(
article,
probability=prediction[None, :],
weight=True,
)[0]
for article in articles
if article.label != target
]
result = defaultdict(list)
for row in tqdm(test_df.iloc, total=len(test_df)):
target = row.target.casefold().strip()
result[target].extend(distances(target=target, tokens=row.tokens))
return {
target: np.array(distances)
for target, distances in result.items()
}Code
test_inverse_distances = get_inverse_distances(
model=model,
article_df=articles_df,
test_df=dataset,
)Code
test_inverse_distances_df = pd.DataFrame(
test_inverse_distances.items(),
columns=["target", "distances"]
)
(
test_inverse_distances_df
.distances
.explode()
.sort_values()
.reset_index(drop=True)
.plot(logy=True)
)
test_inverse_distances_description = (
test_inverse_distances_df
.distances
.explode()
.astype(float)
.describe()
)
test_inverse_distances_descriptioncount 4.133000e+07
mean 1.303832e+01
std 1.065694e+02
min 1.328982e-01
25% 3.404495e+00
50% 6.161124e+00
75% 1.129665e+01
max 2.303269e+04
Name: distances, dtype: float64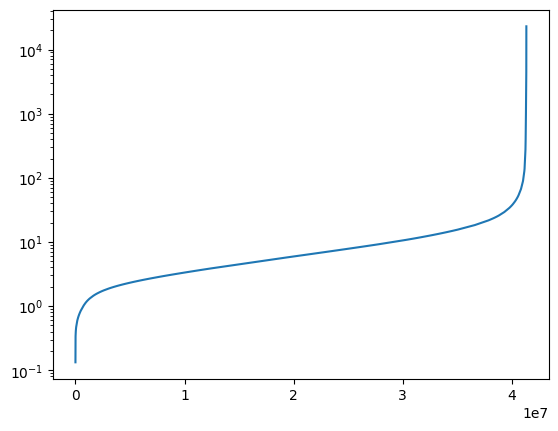
To compare these:
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| matching | 10000.0 | 1.962475 | 10.603511 | 0.124409 | 0.677459 | 0.976587 | 1.591136 | 828.763570 |
| inverse | 41330000.0 | 13.038316 | 106.569437 | 0.132898 | 3.404495 | 6.161124 | 11.296645 | 23032.693293 |
We can see that most of the articles are quite distant. The minimum being very close is to be expected as we have observed overlapping clusters when visualising the articles before.
With this it should now be possible to start matching articles to the points that are within some fixed distance. Then I can use the synonyms to find the correct article.
Making the Metric
To have a metric that can plug into the huggingface trainer I need a way to measure the ideal output against the current output. I think that quartiles or a threshold seem appropriate, and that the model output is good if the distance to the correct article is within some boundary.
I also need a way to do this that fits within the shape of the dataset that I use to train the model. That can come later though. The aim of this section is to evaluate the student against this metric for at least ten thousand rows.
Creating Test Dataset
The parallel sentence dataset has the problem that I do not know what the nouns actually refer to in it. For this to work with the student model I need an article to compare against. That means working with wikipedia, as I am using that to define the articles to begin with.
Once I have accepted working with wikipedia the next thing is to clean the data and extract the links. The text (without wikipedia markup) can then be tokenized and the links can be associated with the tokens. Finally I can split the input up into longer sequences than a single sentence, to provide more context to the model:

The first thing to do is to define the metric. I just need all of the different article descriptions and a way to resolve them. For now I am going to use an index which the processed data will have to respect, I may change that to make it more flexible when I fully process the data.
Code
import pandas as pd
import torch
class ArticleMetric:
def __init__(self, article_df: pd.DataFrame) -> None:
articles = [
ArticleDescription(**row.to_dict())
for row in article_df.iloc
]
self.articles = sorted(articles, key=lambda article: article.label)
@property
def target_ids(self) -> dict[str, int]:
return {
article.label: index
for index, article in enumerate(self.articles)
}
def distance(self, output: torch.Tensor, target: int) -> float:
article = self.articles[target]
probability = output[article.indices]
probability = probability.cpu().numpy()
return article.distance(probability[None, :], weight=True)[0]Now I can write the code to process the data and come up with the dataset. As I have processed a bunch of wikipedia data before I am going to reuse a lot of that code.
Code
# from src/main/python/blog/prompt_internalization/wikipedia/articles.py
import bz2
from dataclasses import dataclass
from pathlib import Path
from typing import Iterator, Optional
from lxml.etree import Element, iterparse
MEDIAWIKI_NAMESPACE = "http://www.mediawiki.org/xml/export-0.10/"
@dataclass
class Article:
title: str
body: str
def read_articles(file: Path) -> Iterator[Article]:
for page in read_pages(file):
try:
article = _get_article(page)
if article:
yield article
except Exception as exception: # pylint: disable=broad-except
print(exception)
def _get_article(element: Element) -> Optional[Article]:
namespace = _get("mw:ns", element)
if namespace is None or namespace.text != "0":
return None
redirect = _get("mw:redirect", element)
if redirect is not None:
return None
text_element = _get("mw:revision/mw:text", element)
if text_element is None:
return None
title_element = _get("mw:title", element)
if title_element is None:
return None
return Article(title=title_element.text, body=text_element.text)
def _get(path: str, element: Element) -> Optional[Element]:
elements = element.xpath(path, namespaces={"mw": MEDIAWIKI_NAMESPACE})
if elements:
return elements[0]
return None
def read_pages(file: Path) -> Iterator[Element]:
with bz2.BZ2File(file, "rb") as handle:
for _event, element in iterparse(
handle, tag=f"{{{MEDIAWIKI_NAMESPACE}}}page", events=("end",)
):
yield element
_clear_memory(element)
def _clear_memory(element: Element) -> None:
element.clear()
for ancestor in element.xpath("ancestor-or-self::*"):
while ancestor.getprevious() is not None:
del ancestor.getparent()[0]
# from src/main/python/blog/prompt_internalization/wikipedia/clean.py
from __future__ import annotations
import regex as re
import wikitextparser
TABLE_PATTERN = re.compile(
r"(?:{{[^}]*}})|(?:{\|[^}]*(?<=\|)})",
flags=re.MULTILINE,
)
URL_PATTERN = re.compile(
r"http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\(\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+"
)
TITLE_PATTERN = re.compile(r"^\s*==+[^=]*?==+\s*$", flags=re.MULTILINE)
LEADING_COLON_OR_HASH = re.compile(r"^[:#]", flags=re.MULTILINE)
HTML_TAG = re.compile(r"<[^>]+>")
MANY_BLANK_LINES = re.compile(r"(\n\s*)+\n+")
MANY_SPACES = re.compile(r" +")
MARKUP = re.compile(r"[']+")
LIST_ITEM = re.compile(r"^\s*\*.*$", re.MULTILINE)
LINK_ONLY_LINE = re.compile(r"^[^a-zA-Z]*(?:\[\[[^]]*\]\][^a-zA-Z]*)+$", re.MULTILINE)
def clean_wikitext(text: str) -> str:
text = wikitextparser.parse(text).plain_text(replace_wikilinks=False)
for pattern in [
TABLE_PATTERN,
URL_PATTERN,
TITLE_PATTERN,
LEADING_COLON_OR_HASH,
HTML_TAG,
MARKUP,
LIST_ITEM,
LINK_ONLY_LINE,
MANY_BLANK_LINES,
MANY_SPACES,
]:
text = pattern.sub(" ", text)
return text.strip()
# from src/main/python/blog/prompt_internalization/wikipedia/dataset.py
from dataclasses import dataclass, replace
from typing import Dict, Iterator, List, Tuple
import regex as re
import wikitextparser
from transformers import AutoTokenizer
SENTENCE_PATTERN = re.compile(r"([^.!?\s][^.!?]+[.!?])")
def to_rows(
text: str,
tokenizer: AutoTokenizer,
target_id: Dict[str, int],
) -> Iterator[Dict[str, List[int]]]:
sentences = _get_sentences(text=text, tokenizer=tokenizer)
batch = []
length_limit = tokenizer.model_max_length - 2 # special tokens
for sentence in sentences:
batch_length = sum(len(entry.input_ids) for entry in batch)
sentence_length = len(sentence.input_ids)
if batch_length + sentence_length > length_limit:
yield from _explode_batch(
batch=batch, tokenizer=tokenizer, target_id=target_id
)
if sentence_length > length_limit:
batch = []
continue
while batch and batch_length + sentence_length > length_limit:
batch = batch[1:]
batch_length = sum(len(entry.input_ids) for entry in batch)
batch.append(sentence)
if batch:
yield from _explode_batch(batch=batch, tokenizer=tokenizer, target_id=target_id)
@dataclass
class Link:
text: str
target: str
start: int
end: int
@dataclass
class SentenceLinks:
text: str
input_ids: List[int]
links: List[Link]
def _explode_batch(
batch: List[SentenceLinks],
tokenizer: AutoTokenizer,
target_id: Dict[str, int],
) -> Iterator[Dict[str, List[int]]]:
input_ids = (
[tokenizer.bos_token_id]
+ sum([entry.input_ids for entry in batch], start=[])
+ [tokenizer.eos_token_id]
)
offset = 1 # bos_token
for entry in batch:
for link in entry.links:
target = link.target.casefold().strip()
if target not in target_id:
continue
yield {
"input_ids": input_ids,
"label": (
link.start + offset,
link.end + offset,
target_id[target],
),
}
offset += len(entry.input_ids)
def _get_sentences(
text: str,
tokenizer: AutoTokenizer,
) -> List[SentenceLinks]:
text, links = _get_links(text)
sentences = [
{
"text": match.groups()[0],
"start": match.span()[0],
"end": match.span()[1],
}
for match in SENTENCE_PATTERN.finditer(text)
]
sentences = [
{
**sentence,
**tokenizer(
sentence["text"],
add_special_tokens=False,
return_attention_mask=False,
return_offsets_mapping=True,
),
}
for sentence in sentences
]
sentences = [
SentenceLinks(
text=sentence["text"],
input_ids=sentence["input_ids"],
links=_get_sentence_links(
start=sentence["start"], offsets=sentence["offset_mapping"], links=links
),
)
for sentence in sentences
]
return sentences
def _get_sentence_links(
start: int, offsets: List[Tuple[int, int]], links: List[Link]
) -> List[Link]:
starts = [s for s, _ in offsets]
ends = [e for _, e in offsets]
links = [
replace(link, start=link.start - start, end=link.end - start) for link in links
]
return [
replace(link, start=starts.index(link.start), end=ends.index(link.end) + 1)
for link in links
if link.start in starts and link.end in ends
]
def _get_links(text: str) -> Tuple[str, List[Link]]:
parsed = wikitextparser.parse(text)
links = []
offset = 0
for link in parsed.wikilinks:
start, end = link.span
text = link.plain_text()
length = len(text)
links.append(
Link(
target=link.target,
text=text,
start=start - offset,
end=start + length - offset,
)
)
offset += end - (start + length)
return parsed.plain_text(), linksCode
from typing import List
from pathlib import Path
from transformers import AutoTokenizer
from tqdm.auto import tqdm
import pandas as pd
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
metric = ArticleMetric(article_df=articles_df)
def collect_rows(files: List[Path], count: int = 10_000) -> pd.DataFrame:
target_id = metric.target_ids
row_generator = (
row
for file in files
for article in read_articles(file)
for row in to_rows(
clean_wikitext(article.body),
tokenizer=tokenizer,
target_id=target_id,
)
)
rows = [
row
for index, row in tqdm(zip(range(count), row_generator), total=count)
]
return pd.DataFrame(rows)Code
rows_df = collect_rows(WIKIPEDIA_ARTICLES[::-1])We can do a spot check on this by looking at the text around a noun as well as the noun itself. This has already been filtered down to the pages that have articles.
Code
for row in rows_df.iloc[0:10].iloc:
print(tokenizer.decode(row.input_ids[row.label[0]:row.label[1]]))
print(tokenizer.decode(row.input_ids[max(0, row.label[0]-50):row.label[1]+50]))
print()Queensland
<s> David Stagg (born 18 October 1983, in Townsville, Queensland) is an Australian former professional rugby league footballer. He made one appearance for the Queensland State of Origin side and played for the Brisbane Broncos, with whom he won the 2006 NRL Premiership, and the Canterbury-
rugby league
<s> David Stagg (born 18 October 1983, in Townsville, Queensland) is an Australian former professional rugby league footballer. He made one appearance for the Queensland State of Origin side and played for the Brisbane Broncos, with whom he won the 2006 NRL Premiership, and the Canterbury-Bankstown Bulldogs. He
Brisbane Broncos
<s> David Stagg (born 18 October 1983, in Townsville, Queensland) is an Australian former professional rugby league footballer. He made one appearance for the Queensland State of Origin side and played for the Brisbane Broncos, with whom he won the 2006 NRL Premiership, and the Canterbury-Bankstown Bulldogs. He was known for his high workload and played as a and, but could also fill in at. Stagg
Canterbury-Bankstown Bulldogs
ville, Queensland) is an Australian former professional rugby league footballer. He made one appearance for the Queensland State of Origin side and played for the Brisbane Broncos, with whom he won the 2006 NRL Premiership, and the Canterbury-Bankstown Bulldogs. He was known for his high workload and played as a and, but could also fill in at. Stagg played his junior football for Norms TRL before joining the Brisbane Broncos. He made his NRL
Brisbane Broncos
the Canterbury-Bankstown Bulldogs. He was known for his high workload and played as a and, but could also fill in at. Stagg played his junior football for Norms TRL before joining the Brisbane Broncos. He made his NRL debut in round 18 of the 2003 NRL season against the Canterbury-Bankstown Bulldogs. In 2004, Stagg set a new record for tackles in a game, with 64 tackles made against
Canterbury-Bankstown Bulldogs
a and, but could also fill in at. Stagg played his junior football for Norms TRL before joining the Brisbane Broncos. He made his NRL debut in round 18 of the 2003 NRL season against the Canterbury-Bankstown Bulldogs. In 2004, Stagg set a new record for tackles in a game, with 64 tackles made against the Cronulla-Sutherland Sharks, this record has since been beaten. In 2006, Stagg made his representative debut
Cronulla-Sutherland Sharks
He made his NRL debut in round 18 of the 2003 NRL season against the Canterbury-Bankstown Bulldogs. In 2004, Stagg set a new record for tackles in a game, with 64 tackles made against the Cronulla-Sutherland Sharks, this record has since been beaten. In 2006, Stagg made his representative debut, and played only one game for Queensland in State of Origin before being dropped. Later that year he played at centre in the Broncos 2006 NRL
Canterbury-Bankstown Bulldogs
sland in State of Origin before being dropped. Later that year he played at centre in the Broncos 2006 NRL Grand Final victory. After winning the grand final with the Broncos, Stagg signed a two-year deal with the Canterbury-Bankstown Bulldogs. In his first season at Canterbury, Stagg played 24 games as the club finished second on the table during the regular season. Stagg played for Canterbury in their preliminary final defeat against arch rivals Parramatta
Parramatta
Bulldogs. In his first season at Canterbury, Stagg played 24 games as the club finished second on the table during the regular season. Stagg played for Canterbury in their preliminary final defeat against arch rivals Parramatta at Telstra Stadium. In 2010, he extended his contract with Canterbury-Bankstown until the end of 2012. In the 2012 NRL season, Stagg played 27 games as Canterbury won the Minor Premiership and reached the 2012
Melbourne
stown until the end of 2012. In the 2012 NRL season, Stagg played 27 games as Canterbury won the Minor Premiership and reached the 2012 NRL Grand Final. Stagg played in Canterbury s 14–4 loss against Melbourne at ANZ Stadium. Stagg rejoined the Brisbane Broncos in 2013 on a two-year deal, he would go on to play 14 games for the club in the 2013 NRL season. In the early rounds of
This looks good to me. With this it should then be possible to create a simple metric class that just produces the distance for each article, given the student model output.
Since I am doing this as a spot check I am going to iterate over the rows individually. I do feel that iterating over the rows in the batch is both expensive and necessary at this point. A more efficient implementation is possible by using the target as an index and then doing hadamard operations:
\[ \left\lVert output \circ mean_{target} \circ \frac{1}{\sigma_{target}} \right\rVert_2 \]
(I’m trying to get better at understanding the mathematics behind what I am doing)
Let’s try loading everything up and running it over a single row.
Code
from transformers import AutoModelForMaskedLM
model = AutoModelForMaskedLM.from_pretrained("/data/prompt-internalization/multilingual/xlm-roberta-base-e2-bs32-lr0.0001-t2/")
model.eval()
model.cuda() ; NoneCode
import torch
with torch.inference_mode():
row = rows_df.iloc[0]
input_ids = torch.tensor(
row.input_ids,
dtype=torch.long,
device=model.device,
)
input_ids = input_ids[None, :]
output = model(input_ids)
prediction = output.logits[0, row.label[0]] # start token of noun
distance = metric.distance(prediction, target=row.label[2])
print(f"noun: {tokenizer.decode(input_ids[0, row.label[0]:row.label[1]])}")
print(f"context: {tokenizer.decode(input_ids[0])}")
print()
print(f"distance: {distance}")noun: Queensland
context: <s> David Stagg (born 18 October 1983, in Townsville, Queensland) is an Australian former professional rugby league footballer. He made one appearance for the Queensland State of Origin side and played for the Brisbane Broncos, with whom he won the 2006 NRL Premiership, and the Canterbury-Bankstown Bulldogs. He was known for his high workload and played as a and, but could also fill in at. Stagg played his junior football for Norms TRL before joining the Brisbane Broncos. He made his NRL debut in round 18 of the 2003 NRL season against the Canterbury-Bankstown Bulldogs. In 2004, Stagg set a new record for tackles in a game, with 64 tackles made against the Cronulla-Sutherland Sharks, this record has since been beaten. In 2006, Stagg made his representative debut, and played only one game for Queensland in State of Origin before being dropped. Later that year he played at centre in the Broncos 2006 NRL Grand Final victory. After winning the grand final with the Broncos, Stagg signed a two-year deal with the Canterbury-Bankstown Bulldogs. In his first season at Canterbury, Stagg played 24 games as the club finished second on the table during the regular season. Stagg played for Canterbury in their preliminary final defeat against arch rivals Parramatta at Telstra Stadium. In 2010, he extended his contract with Canterbury-Bankstown until the end of 2012. In the 2012 NRL season, Stagg played 27 games as Canterbury won the Minor Premiership and reached the 2012 NRL Grand Final. Stagg played in Canterbury s 14–4 loss against Melbourne at ANZ Stadium. Stagg rejoined the Brisbane Broncos in 2013 on a two-year deal, he would go on to play 14 games for the club in the 2013 NRL season. In the early rounds of the 2014 NRL season, Stagg suffered a serious knee injury, ruling him out for the season before retiring at the end of the 2015 NRL season. During the 2007/2008 off season Stagg married his then girlfriend, Tamika Sellars. The couple have 2 children.</s>
distance: 400879.4418640264As a spot check this is brutal. The student is terrible!
I can check how well the article itself is described, however this outcome is not entirely unexpected.
Code
article_counts[article_counts.index == "queensland"]queensland 687
Name: target, dtype: int64So it’s being measured against almost 700 observed links. The article processing as it was done at the time was quite different to this - only the single sentence that was surrounding the noun was processed and quite a lot of junk pages were included. Even so this is a very different output.
Reprocessing the articles to get better centroids for them should certainly be considered. Before that the model should be assessed on all of the dataset.
Code
from typing import List
from transformers import AutoModelForMaskedLM, AutoTokenizer
import pandas as pd
import torch
from tqdm.auto import tqdm
def measure(
model: AutoModelForMaskedLM,
tokenizer: AutoTokenizer,
metric: ArticleMetric,
rows: pd.DataFrame,
) -> pd.DataFrame:
results = []
for row in tqdm(rows.iloc, total=len(rows)):
input_ids = row.input_ids
start, _end, target = row.label
prediction = predict(model=model, input_ids=input_ids, start=start)
distance = metric.distance(prediction, target=target)
results.append({
"target": metric.articles[target].label,
"distance": distance
})
return pd.DataFrame(results)
@torch.inference_mode()
def predict(model: AutoModelForMaskedLM, input_ids: List[int], start: int) -> torch.Tensor:
input_ids = torch.tensor(
input_ids,
dtype=torch.long,
device=model.device,
)
input_ids = input_ids[None, :]
output = model(input_ids)
return output.logits[0, start]Code
distances_df = measure(model=model, tokenizer=tokenizer, metric=metric, rows=rows_df)Code
distances_df.distance.describe()count 1.000000e+04
mean 1.335403e+05
std 1.509900e+05
min 2.669118e+04
25% 4.756868e+04
50% 6.907920e+04
75% 1.548984e+05
max 1.192647e+06
Name: distance, dtype: float64Code
(
distances_df
.distance
.sort_values()
.reset_index(drop=True)
.plot(logy=True)
) ; None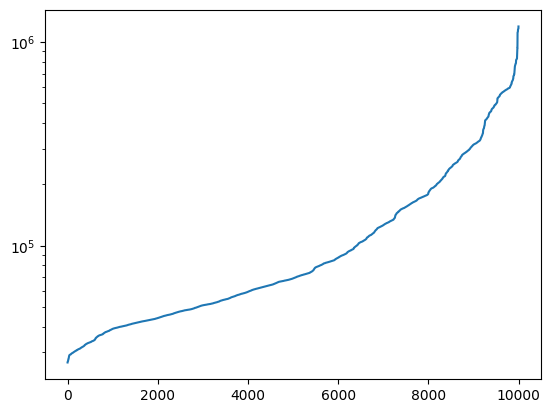
This is clearly a really brutal assessment. As such it forms a great metric.
Next Steps
The next task is to reprocess the data to produce better centroids. As I think about it this would be a really neat way to train the model as well. The article descriptions are formed without using the student so they can be computed ahead of time. Then I can train the model by comparing the output to the article centroid.
That would be really neat as it would both provide longer input to the student and provide multiple nouns per input. The current structure of the training data only provides feedback on a single entry so I would need a way to deal with that.
The bigger problem would be connecting the wikipedia articles across languages. As it happens the wikidata site appears to do exactly this. If I look at the page for Planet Earth on wikipedia I can see a wikidata item link on the left hand side. This page then links to the Spanish version and a lot of others on the right hand side. If I can process the wikidata pages then I can find links between the titles of the different languages.
This would completely break the requirement to have aligned sentences, which is really neat. I was not making much progress on getting a dataset which has noun level associations between the sentences.
When training like this I may also change to a semantic search type training, where I have a target article and several detractor articles. I can then use the cosine similarity between them to move the model output towards the target article and away from the other articles. I don’t know if this would be better as it’s usually used to establish structure in an unlabelled space.
It also occurs to me that the overlap of the different articles may well form an ontology of articles. When assigning the model prediction to an article it would be good to assign it to the broadest article that makes sense. For many things there are increasingly specific articles, for example the iPhone vs the iPhone 4S. These articles are likely to strongly overlap so it would be good to take the one that has the broader context.